Clear Sky Science · fr
Méthode de planification de trajectoire pour UAV policiers basée sur un PSO amélioré utilisant AFS et HJS
Des yeux plus intelligents dans le ciel
Les forces de police recourent de plus en plus à de petits aéronefs sans pilote — les drones de police — pour surveiller les rues animées, rechercher des personnes disparues et intervenir en cas d'urgence. Mais pour un drone, « où voler ensuite » n'est pas une question simple : il doit visiter plusieurs lieux rapidement, éviter les zones d'interdiction de vol et préserver la batterie, le tout dans un espace aérien urbain encombré. Cette étude présente une nouvelle méthode de planification automatique de ces trajectoires afin que les drones de police puissent accomplir leurs missions plus rapidement et en toute sécurité, même dans des environnements urbains complexes.
Le défi de trouver un meilleur itinéraire
Imaginez une voiture de patrouille capable de franchir bouchons et bâtiments — c'est à peu près ce qu'un drone de police peut faire. Pourtant, son itinéraire doit être soigneusement choisi. Les méthodes existantes de planification de trajectoires issues de la robotique et de l'intelligence artificielle peuvent aider, mais chacune comporte des compromis. Certaines explorent bien mais sont trop lentes, d'autres sont rapides mais restent bloquées sur des solutions moyennes. Le travail policier ajoute des complications : le drone peut devoir visiter de nombreux objectifs, contourner des espaces aériens restreints et s'adapter à des situations changeantes. Les auteurs se concentrent sur cette version particulière du problème de planification d'itinéraire et la nomment problème de planification de trajectoire pour UAV policiers, ou PU3P.
Emprunter des idées aux volées d'oiseaux
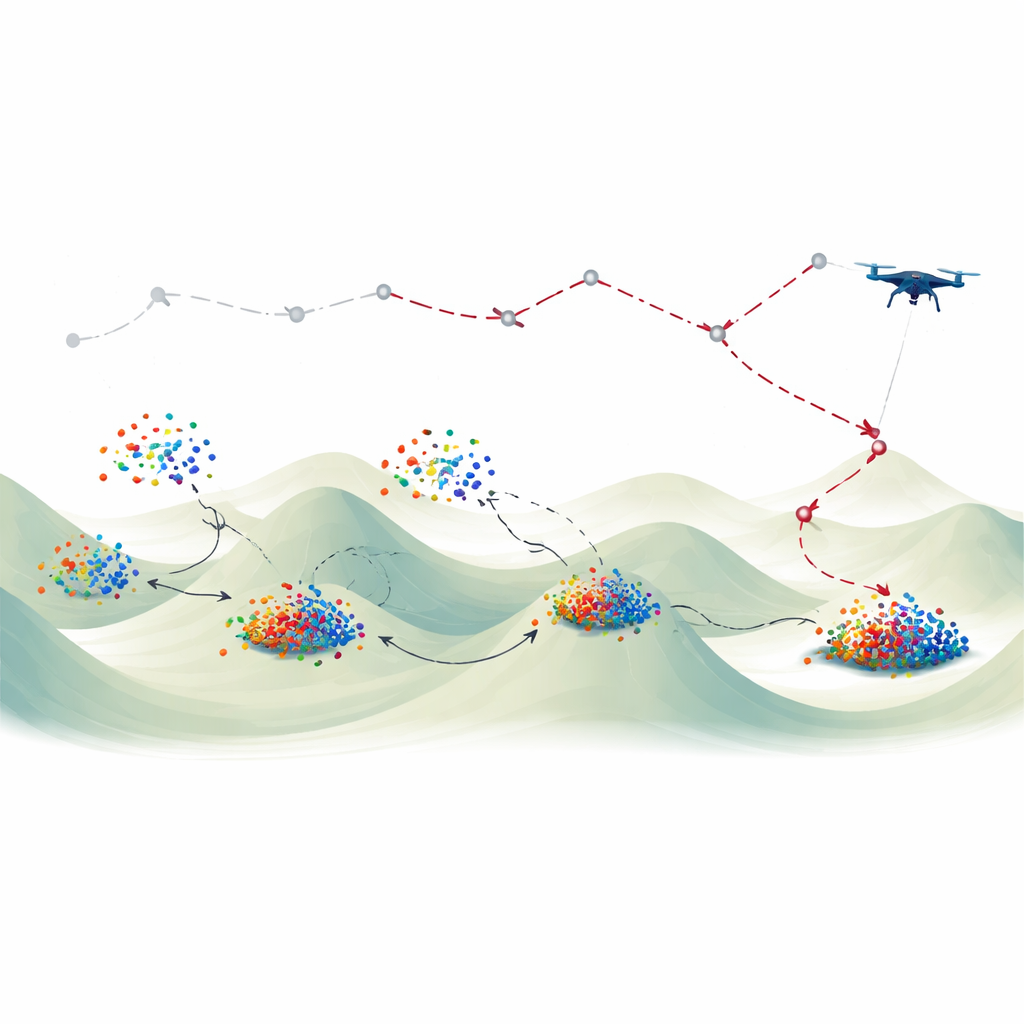
Pour aborder le PU3P, les chercheurs s'appuient sur une méthode d'optimisation populaire appelée Particle Swarm Optimization. Dans cette approche, de nombreux « particules » virtuelles simples parcourent un espace de recherche comme des oiseaux d'un volée qui se dispersent sur un champ pour trouver de la nourriture. Chaque particule se souvient de sa meilleure position jusqu'à présent et prend en compte la meilleure position trouvée par le groupe. Au fil des itérations, l'essaim tend à se diriger vers des régions prometteuses, qui correspondent ici à de bons trajets. Les versions classiques de cette méthode ont toutefois été conçues principalement pour des problèmes lisses et continus, pas pour les séquences discrètes de points de passage qui définissent la route d'un drone. Elles peuvent aussi converger prématurément vers une solution médiocre.
Deux ajustements pour améliorer la recherche
L'article introduit deux ajustements clés pour affiner cette recherche inspirée des volées. Le premier, appelé stratégie du facteur adaptatif, modifie progressivement la force avec laquelle les particules conservent leur mouvement précédent dans l'étape suivante. Au début, cela favorise une large exploration ; plus tard, cela privilégie l'affinage autour de bons candidats. Le second ajustement, nommé stratégie du demi‑saut, pousse périodiquement certaines particules à se rapprocher partiellement des meilleures positions observées, au lieu de les laisser errer complètement seules. Ensemble, ces stratégies donnent naissance à un essaim amélioré, nommé AFS‑HJS‑PSO, capable à la fois d'explorer largement et de converger rapidement. Les auteurs adaptent ensuite cet essaim amélioré pour traiter les séquences étape par étape des visites de cibles dans le PU3P, en définissant une fonction d'aptitude qui capture la distance totale parcourue par un drone de police visitant toutes les positions assignées.
Mettre la nouvelle méthode à l'épreuve
Pour vérifier l'intérêt de leur approche, l'équipe oppose l'AFS‑HJS‑PSO à plusieurs concurrents bien connus : une méthode d'essaim standard, un algorithme génétique inspiré de l'évolution, le recuit simulé emprunté à la métallurgie et un solveur classique d'optimisation non linéaire. Ils testent d'abord toutes ces méthodes sur 20 problèmes de référence mathématiques standard couramment utilisés pour évaluer les algorithmes de recherche. Sur la plupart de ces tests, le nouvel essaim atteint de meilleures solutions, y parvient plus rapidement ou le fait de manière plus régulière. Ils passent ensuite au problème réel d'itinéraires pour drones de police, en exécutant chaque méthode 30 fois sur le même ensemble de cibles. L'essaim amélioré trouve à nouveau des trajets moyens plus courts et montre une rapidité et une fiabilité compétitives par rapport aux autres techniques.
Ce que cela signifie pour les drones de police à venir
En termes simples, l'étude montre que l'on peut obtenir de meilleurs plans de vol pour les drones de police en apprenant à un essaim virtuel à ajuster son comportement en temps réel et à effectuer des demi‑pas intelligents vers de bonnes solutions. La méthode améliorée n'est pas parfaite — elle peut encore gagner en stabilité et en efficacité — mais dans les conditions testées, elle surpasse plusieurs outils établis. À mesure que les drones se multiplieront dans la sécurité publique, de tels progrès en planification d'itinéraires pourraient les aider à intervenir plus vite, à passer moins de temps en vol et à réduire les risques dans des cieux encombrés.
Citation: Wang, D., Qian, X. Police UAV path planning method based on improved PSO using AFS and HJS. Sci Rep 16, 12417 (2026). https://doi.org/10.1038/s41598-026-40670-9
Mots-clés: drone de police, planification de trajectoire UAV, optimisation par essaim, algorithmes de planification d'itinéraire, surveillance urbaine