Clear Sky Science · fr
Modélisation à grande échelle pour la prédiction de l’état des logements à l’aide d’algorithmes d’apprentissage automatique
Pourquoi l’état de nos logements compte
Qu’un logement soit sûr, sec et confortable influe sur tout, de la santé d’un enfant à la stabilité financière d’une famille. Pourtant, alors que nous suivons les prix des logements jusque dans les moindres rues, nous disposons rarement d’une image aussi détaillée de la qualité du bâti. Cette étude s’attaque à cette zone d’ombre en utilisant des techniques informatiques modernes pour estimer l’état de près de chaque logement aux États-Unis, et en produisant des cartes qui montrent où les logements prospèrent et où ils peuvent mettre les habitants en danger.
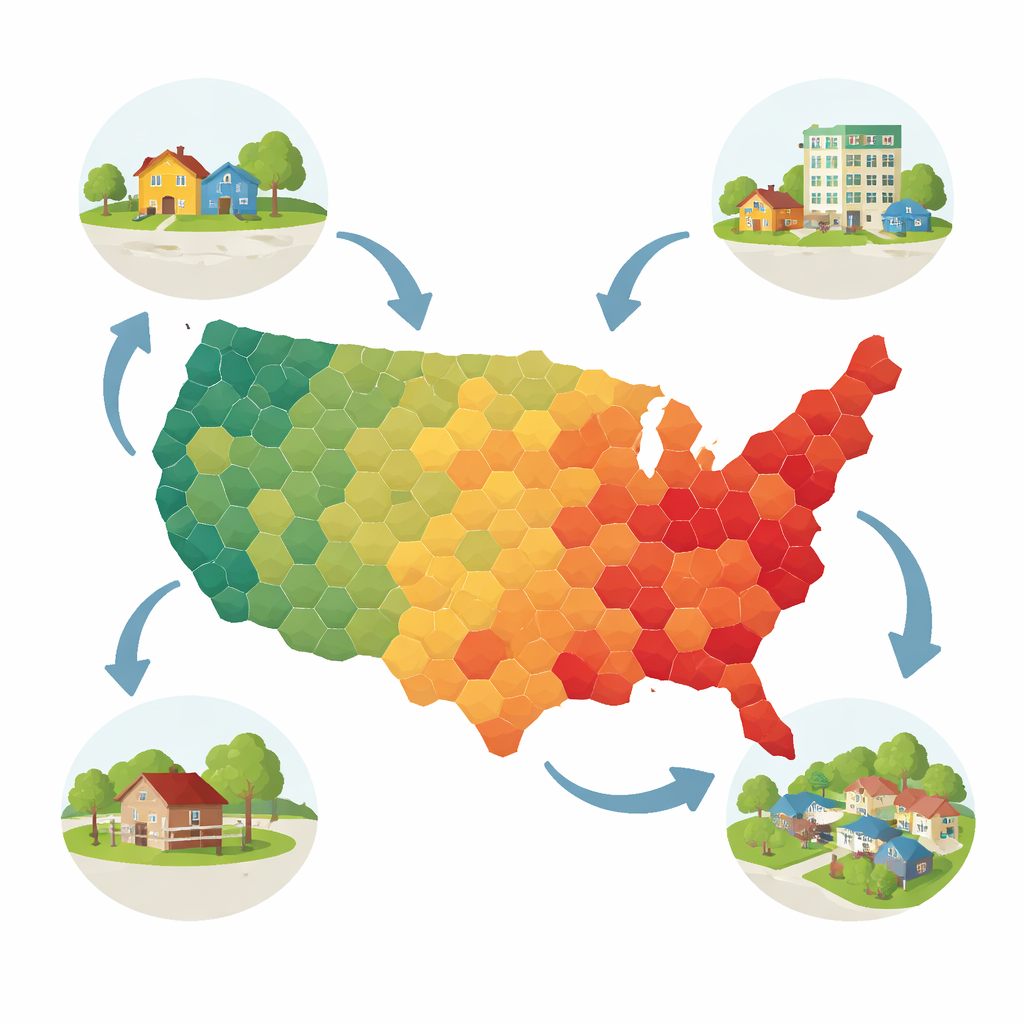
Des prix des maisons à la qualité des logements
Les chercheurs ont depuis longtemps modélisé la valeur des logements, mais on sait beaucoup moins de choses sur leur habitabilité. Les enquêtes nationales existantes ne fournissent que des instantanés grossiers, souvent au niveau des États ou des zones métropolitaines, et de nombreux jeux de données gouvernementaux se concentrent sur l’abordabilité ou la suroccupation plutôt que sur l’état physique des bâtiments. Comme les agences locales collectent et évaluent les logements de manières différentes, il n’existait pas de vision unifiée et détaillée des conditions du parc résidentiel à l’échelle nationale. Cette lacune complique le travail des urbanistes, des responsables de la santé et des communautés qui cherchent à repérer où des logements de mauvaise qualité peuvent concentrer des risques comme la moisissure, les fuites, des températures intérieures extrêmes ou des structures dangereuses.
Intégrer le big data au niveau du quartier
Pour combler ce vide, les auteurs ont combiné deux sources majeures de données. La première est une base foncière nationale contenant plus de 111 millions de logements, avec des détails tels que le nombre de chambres et de salles de bains, l’année de construction et de rénovation, les matériaux de toiture et d’extérieur, le système de chauffage, le stationnement, les taxes et — quand elles sont disponibles — une évaluation en six niveaux de l’état du bâtiment, de « non sain » à « excellent ». La seconde source regroupe des données du recensement américain et des informations de voisinage apparentées, décrivant les niveaux de revenus locaux, la valeur des logements, la part de propriétaires et de mobil-homes, la densité de population, la pauvreté et le caractère urbain ou rural d’une zone. En appariant spatialement chaque propriété à son secteur de recensement ou groupe de blocs environnant, l’équipe a créé un enregistrement unifié liant les caractéristiques du bâtiment au contexte socio-économique autour de chaque logement.
Apprendre aux machines à reconnaître la santé des logements
Environ la moitié des biens dans la base n’avait pas d’évaluation officielle d’état. Les chercheurs ont entraîné trois modèles avancés d’apprentissage automatique — CatBoost, LightGBM et XGBoost — sur les logements qui disposaient d’une notation, demandant aux algorithmes d’apprendre comment les combinaisons de caractéristiques de la propriété et du voisinage se rattachent à l’état du logement. Ils ont soigneusement nettoyé les données, traité les valeurs aberrantes et manquantes, et utilisé un cluster de calcul haute performance — doté de processeurs graphiques puissants — pour rechercher efficacement les meilleurs réglages des modèles. Pour éviter que les modèles ne « mémorisent » simplement les données d’entraînement, ils ont utilisé la précision équilibrée et la validation croisée, puis affiné davantage le modèle gagnant afin que ses probabilités estimées correspondent le plus possible aux résultats du monde réel.

Transformer les prédictions en cartes utiles
Une fois le modèle le plus performant (CatBoost) sélectionné, il a été utilisé pour prédire les notes d’état des millions de logements dépourvus d’information. La catégorie de chaque logement a été convertie en un score numérique allant de un (pire) à six (meilleur). Pour protéger la vie privée et rendre les motifs plus lisibles, les chercheurs ont ensuite moyenné ces scores selon trois types de zones : les tracts de recensement, les zones de dénombrement par code postal (ZIP code tabulation areas) et une grille régulière d’hexagones d’environ 36 kilomètres carrés couvrant tout le pays. Le résultat est un ensemble de cartes nationales révélant de larges paysages de qualité du logement tout en restant suffisamment détaillé pour orienter des analyses locales. L’équipe a également vérifié les performances du modèle à l’aide de plusieurs tests statistiques, trouvant un accord modéré mais significatif compte tenu de l’ampleur et de la complexité de la tâche.
Ce qui influence des logements meilleurs ou pires
En examinant les entrées ayant le plus d’importance pour le modèle, l’étude livre des indices sur les facteurs déterminants de l’état des logements. Les caractéristiques au niveau de la propriété prédominent : montant estimé des taxes, revêtement extérieur, type de toiture, système de chauffage, ainsi que l’âge et l’historique des rénovations d’un logement ont eu une influence marquée. Des facteurs de voisinage tels que les taux de pauvreté, la densité de population et la part de mobil-homes ont joué un rôle moindre mais néanmoins important. Ces résultats s’inscrivent dans des recherches plus larges montrant que les ménages à faibles revenus, les locataires et les communautés de couleur sont plus susceptibles d’habiter des logements dégradés, en partie façonnés par des pratiques de crédit inégales et une application disparate des protections du logement.
Un nouvel outil pour des logements plus sûrs et plus équitables
En termes simples, ce travail utilise des motifs présents dans des enregistrements existants pour combler les pièces manquantes d’un puzzle national sur la qualité des logements. Les cartes et jeux de données rendus publics offrent aux urbanistes, aux agences de santé et aux groupes communautaires un nouvel outil puissant pour repérer où des logements peuvent mettre les habitants en danger et où des investissements pourraient produire les bénéfices les plus importants. Aucun modèle n’est parfait, surtout lorsqu’il opère sur des données sous-jacentes inégales, mais cette approche à grande échelle représente une avancée majeure vers la compréhension — et en fin de compte l’amélioration — des environnements quotidiens que les gens appellent chez eux.
Citation: Kim, K., Holmes, T., Powell, E. et al. Large-scale modeling for housing condition prediction using machine learning algorithms. Sci Data 13, 647 (2026). https://doi.org/10.1038/s41597-026-07012-w
Mots-clés: qualité du logement, apprentissage automatique, données spatiales, santé publique, urbanisme