Clear Sky Science · fr
Décodage d’effacement quantique dégénéré
Pourquoi la disparition de qubits est un problème majeur
Les ordinateurs quantiques du futur seront construits à partir de bits quantiques fragiles, ou qubits, constamment menacés de disparition ou de fuite hors du système. Sur de nombreuses plateformes matérielles de pointe — des atomes ultrafroids aux circuits supraconducteurs — le mode de défaillance dominant n’est pas un petit bruit mais bien une perte complète : un qubit disparaît tout simplement. Cet article pose une question pratique aux implications considérables : peut‑on concevoir des codes de correction d’erreurs quantiques et des décodeurs rapides qui annulent presque parfaitement ce type de perte, tout en utilisant le moins de matériel et de temps de calcul possible ?
Transformer la perte de qubits en un bruit plus propre
Les expériences modernes peuvent souvent détecter quand un qubit s’est échappé et marquer sa position. On appelle cela la conversion en effacement : la fuite physique désordonnée est transformée en un « effacement » bien défini à une position connue. Sur un canal d’effacement de ce type, il existe une limite théorique nette à l’efficacité avec laquelle on peut protéger l’information quantique : au maximum une fraction 1 − 2p des qubits matériels peut stocker de l’information utile si chaque qubit est effacé avec une probabilité p. Jusqu’à présent, seule une classe spéciale de codes topologiques bidimensionnels atteignait cette limite pour l’effacement, et ce au prix d’un taux d’information qui tend vers zéro à mesure que le système grandit. Cela les rend coûteux en matériel, d’où la recherche de meilleurs codes et de décodeurs plus rapides adaptés aux effacements.
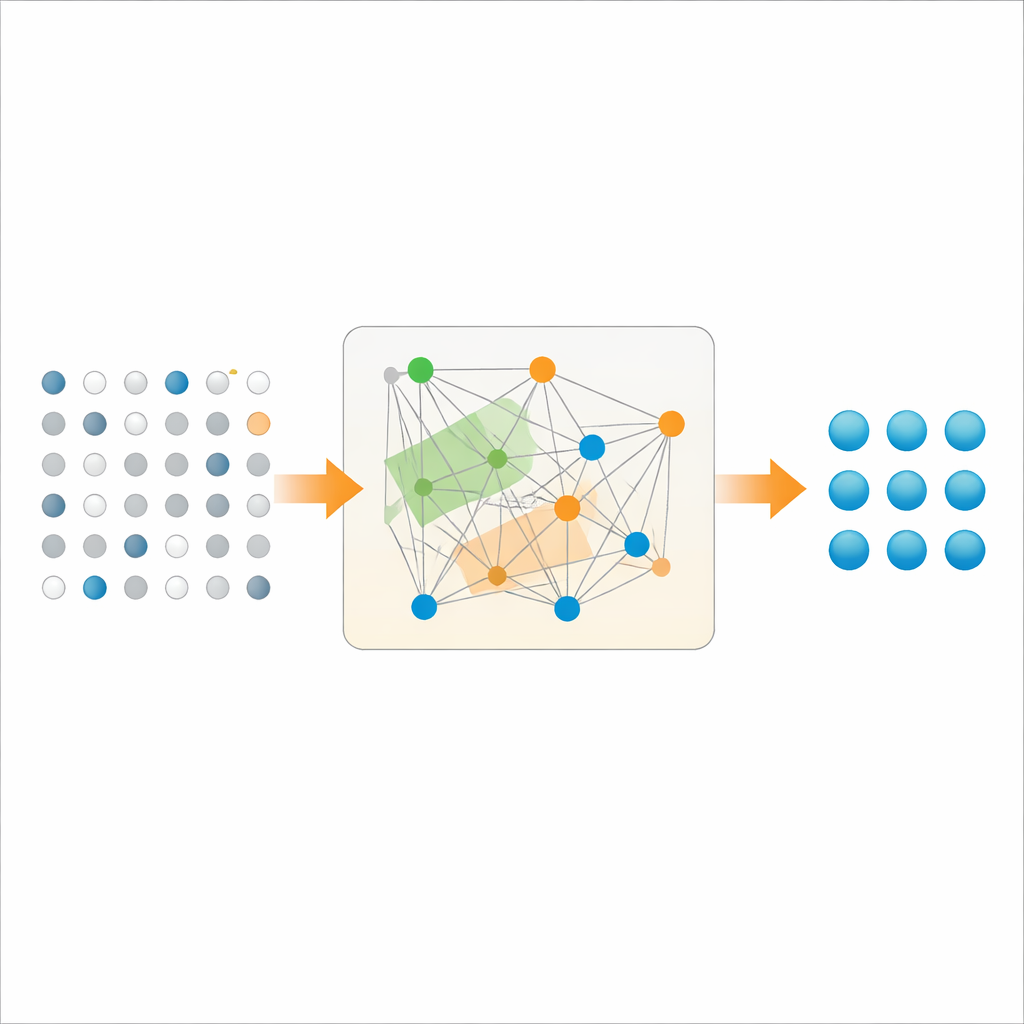
Construire des codes à haut taux qui approchent la limite ultime
Les auteurs montrent que plusieurs familles de codes quantiques à parité creuse (QLDPC) — en particulier les codes bicycle et les codes par produit relevé — peuvent en fait atteindre ou s’approcher de la capacité d’effacement sur une large plage de taux de code. Avec un décodage de maximum de vraisemblance mathématiquement optimal, mis en œuvre par élimination gaussienne, ces codes corrigent les effacements aussi bien que la théorie le permet : le taux réalisable s’aligne étroitement sur 1 − 2p pour des probabilités d’erreur pratiques. Le même cadre couvre aussi les codes topologiques bidimensionnels familiers, confirmant que leur meilleure performance possible en présence d’effacements est retrouvée lorsqu’ils sont décodés de façon optimale.
Du décodage optimal lent à des schémas rapides et quasi‑optimaux
Le problème est que le décodage de maximum de vraisemblance se scale mal : l’algèbre linéaire requise croît approximativement comme le cube du nombre de qubits, trop lent pour une opération en temps réel dans un grand processeur quantique. Pour surmonter cela, l’article développe une famille de décodeurs par propagation de croyances (BP) qui s’exécutent essentiellement en temps linéaire par rapport à la taille du système. Ces décodeurs traitent le code comme un réseau graphique de contraintes et font passer itérativement des « messages » le long des arêtes pour inférer le motif d’erreurs le plus plausible. Crucialement, ils sont conçus pour exploiter une caractéristique purement quantique appelée dégénérescence : de nombreux motifs d’erreurs différents peuvent avoir exactement le même effet sur l’information encodée. En orientant les mises à jour BP vers n’importe quel membre de ces grands ensembles symétriques d’erreurs équivalentes, les décodeurs trouvent de bonnes solutions sans avoir besoin d’identifier l’erreur microscopique exacte.
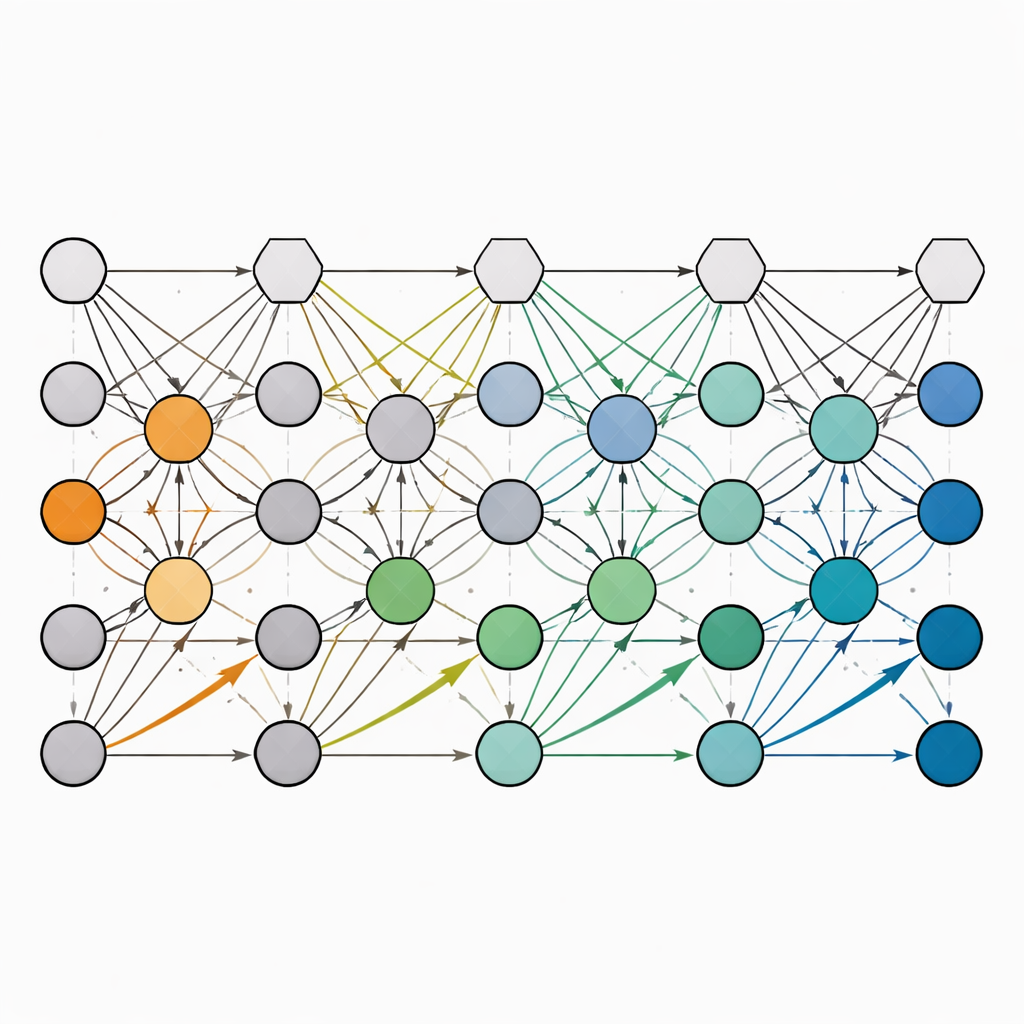
Affiner le passage de messages pour gérer les motifs d’erreur difficiles
Les auteurs introduisent des variantes de BP qui intègrent des idées de descente de gradient et d’effets de mémoire à la manière de réseaux neuronaux. Une version simple « flip » met à jour des valeurs binaires et effectue parfois un pas gourmand lorsque le progrès stagne, tandis que des versions plus avancées « soft » opèrent sur des valeurs de confiance graduées plutôt que sur des décisions strictes 0/1. Ces décodeurs « soft » tempèrent et recyclent les messages passés, ajustent leurs tailles de pas et, dans certains cas, traitent conjointement différents types d’erreurs quantiques plutôt que séparément. Le résultat est une suite d’algorithmes qui, pour les familles de codes testées, atteignent des seuils très proches de ceux du maximum de vraisemblance, tout en ayant un temps d’exécution qui croît seulement linéairement avec le nombre de qubits et relativement peu quand le taux d’erreur diminue.
Extension à des bruits plus réalistes et mixtes
Le matériel réel subit rarement des effacements purs. Les auteurs testent donc leurs décodeurs sur des scénarios plus complexes : des canaux qui combinent des effacements à position connue avec des retournements aléatoires ordinaires, et des canaux où des qubits peuvent être supprimés sans que leur position soit signalée. En concaténant des codes QLDPC avec de petits codes internes invariants par permutation, les suppressions locales sont d’abord converties en effacements effectifs, que les décodeurs BP gèrent ensuite efficacement. Des expériences numériques montrent que la même famille de décodeurs peut prendre en charge ces modèles d’erreurs mixtes avec une grande précision, ce qui suggère que l’approche est robuste bien au‑delà du cadre idéalisé d’effacements purs.
Ce que cela signifie pour les machines quantiques du futur
Dans l’ensemble, ce travail comble une lacune clé entre la théorie et la pratique pour les systèmes quantiques dominés par la perte de qubits. Il démontre que des performances atteignant la capacité, ou proches de celle‑ci, sur les canaux d’effacement sont possibles avec des codes quantiques structurés ayant des taux d’information non nuls, et — surtout — que cela peut être réalisé avec des décodeurs dont le coût croît seulement linéairement avec la taille du système. Pour un lecteur non spécialiste, la conclusion est que, en exploitant astucieusement les symétries des erreurs quantiques, on peut protéger les données quantiques presque aussi bien que le permettent les lois de la physique, sans surcharger le matériel ni par des qubits supplémentaires ni par un calcul classique lourd. Cela renforce significativement l’argument en faveur de la construction d’ordinateurs et de réseaux quantiques à grande échelle sur des plateformes où la perte de qubits peut être détectée et convertie en effacements.
Citation: Kuo, KY., Ouyang, Y. Degenerate quantum erasure decoding. npj Quantum Inf 12, 75 (2026). https://doi.org/10.1038/s41534-026-01212-3
Mots-clés: correction d’erreurs quantiques, erreurs d’effacement, décodage par propagation de croyances, codes LDPC quantiques, informatique quantique tolérante aux fautes