Clear Sky Science · es
Distancias en redes de orden superior ponderadas
Por qué importa medir la distancia en redes
Desde las redes sociales hasta la investigación científica, gran parte de la vida moderna puede describirse como redes de conexiones. Pero muchas situaciones reales implican grupos en lugar de pares simples: un artículo conecta varios campos, un correo va a muchos destinatarios, un fármaco combina varios ingredientes. En estas redes de orden superior, incluso definir qué tan “separados” están dos elementos se vuelve complejo. Este artículo presenta una nueva forma de medir la distancia en sistemas grupales y complejos para mapear mejor cómo se relacionan ideas, personas o componentes.
De enlaces simples a conexiones grupales ricas
En las redes ordinarias, la distancia es directa: es la longitud del camino más corto entre dos nodos. Esto funciona bien cuando cada enlace conecta exactamente dos nodos. Sin embargo, muchos conjuntos de datos reales se describen mejor mediante hipergráficas, donde una sola conexión puede unir tres, cuatro o muchos más nodos a la vez. Un atajo común es descomponer cada grupo en muchos enlaces por pares, un proceso llamado proyección en cliques. Aunque conveniente, este atajo descarta información importante sobre el tamaño de los grupos y sus solapamientos, y por tanto puede distorsionar las distancias entre nodos.
Construir una distancia que respete la estructura de orden superior
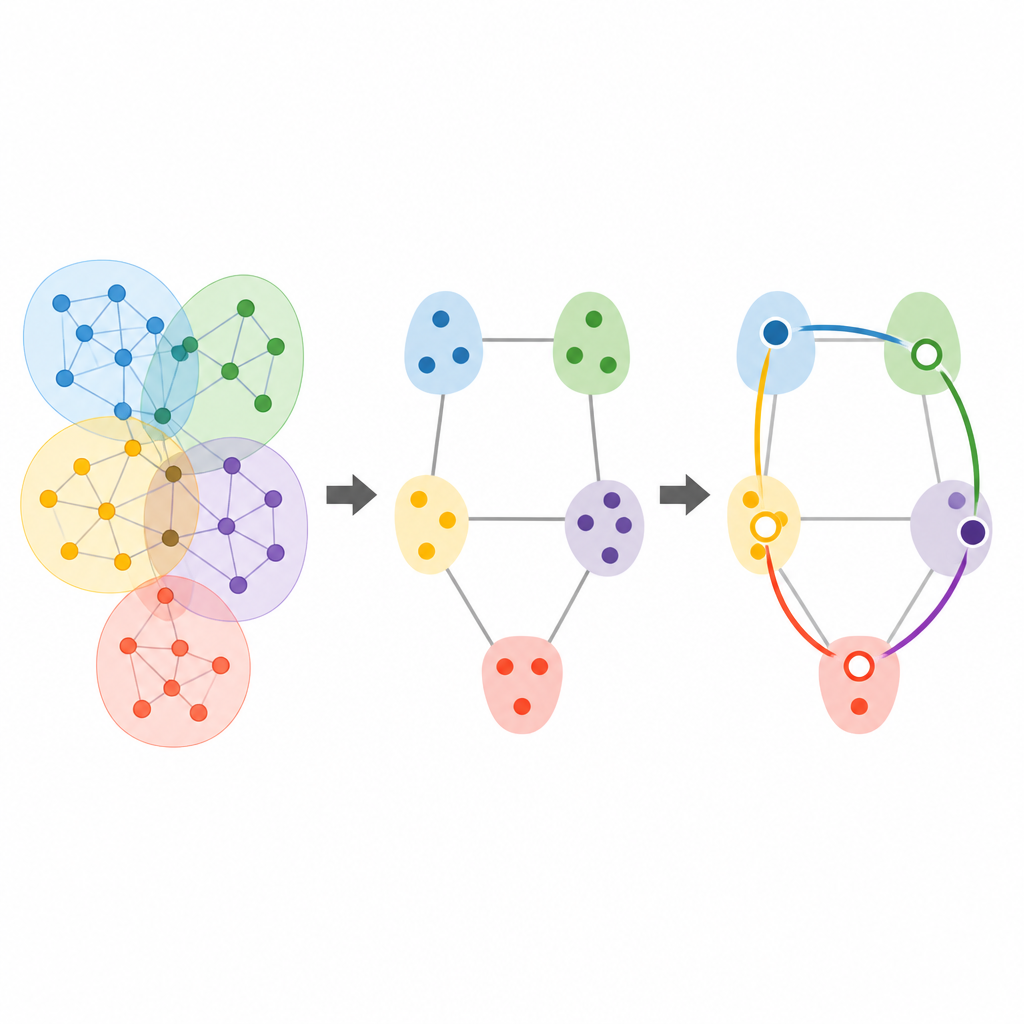
Los autores proponen una medida de distancia diseñada específicamente para hipergráficas ponderadas, donde cada grupo también tiene una intensidad o frecuencia. Su construcción se basa en transformar la hipergráfica en una estructura compañera en la que cada grupo se convierte en un nodo y los solapamientos entre grupos se vuelven enlaces. Las distancias entre nodos originales se derivan entonces de caminos que recorren esta “red de grupos”, teniendo en cuenta tanto el tamaño de los grupos como la fuerza de sus ponderaciones. La distancia resultante cumple todas las reglas habituales de una métrica, como ser siempre no negativa y satisfacer la desigualdad triangular, y se reduce a la distancia de grafos familiar cuando las conexiones son puramente por pares.
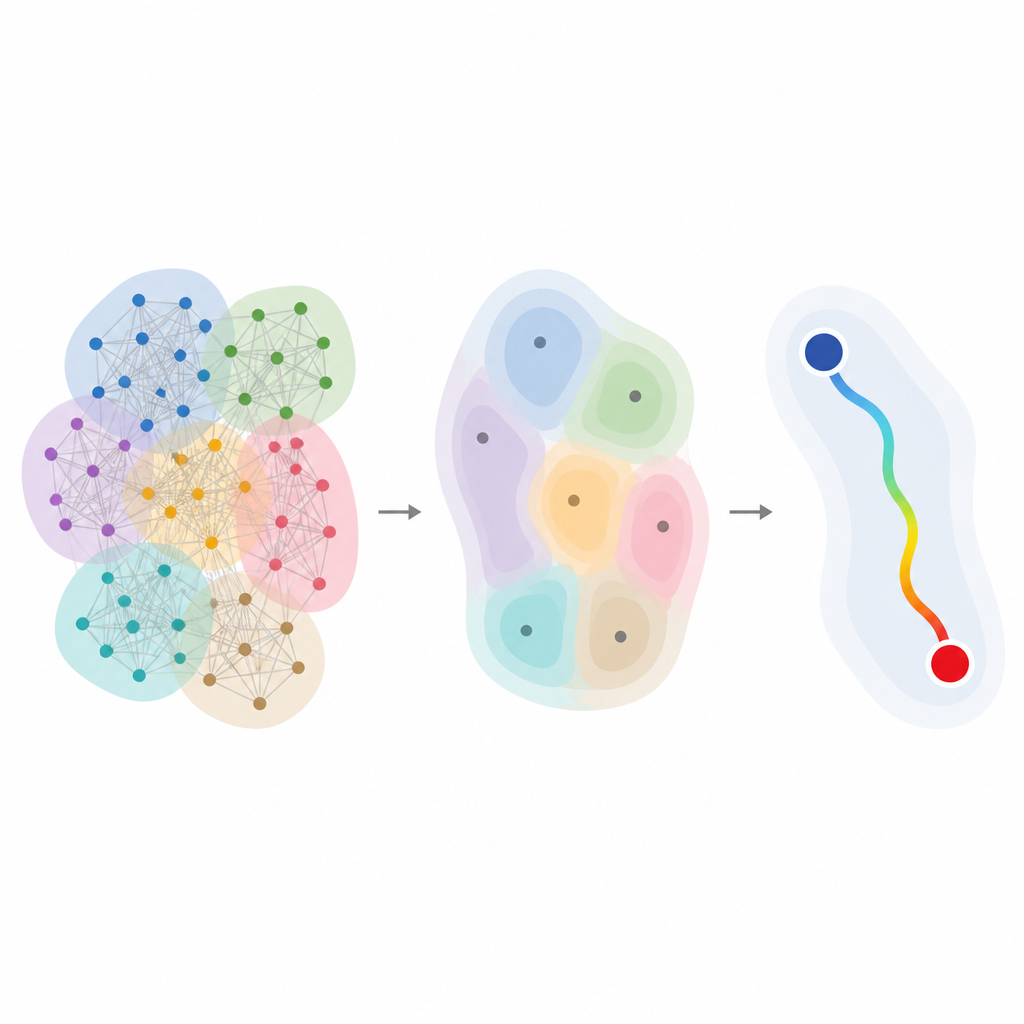
Cómo los pesos y solapamientos moldean la separación
Mediante ejemplos sencillos, el estudio ilustra por qué importan los efectos de orden superior. Cuando un único grupo contiene muchos nodos, cualquier par de miembros de ese grupo grande se considera más lejano que los miembros de un grupo pequeño, reflejando la idea de que compartir un contexto abarrotado genera una afinidad directa más débil. Del mismo modo, si dos grupos se solapan mucho, los nodos en distintos grupos pero dentro del núcleo compartido están efectivamente más cerca. Al añadir ponderaciones, las interacciones frecuentes o fuertes entre grupos acortan las distancias, pero de una forma que depende tanto del tamaño del grupo como de cómo se intersectan. Esta visión más rica contrasta con la proyección en cliques, donde la misma hipergráfica subyacente puede producir distancias por pares idénticas aun cuando la estructura de orden superior es muy distinta.
Probar el método con datos del mundo real
Los investigadores aplican su medida de distancia a varios conjuntos de datos reales, incluyendo el repositorio de preprints arXiv, patrones de contacto en escuelas, correos electrónicos en una empresa, composiciones de fármacos y comités del Senado de Estados Unidos. En el caso de arXiv, cada campo científico es un nodo, cada artículo forma un grupo de campos y los pesos de grupo registran con qué frecuencia aparece una combinación determinada. La nueva distancia se usa para estudiar la “distancia cognitiva” entre campos, es decir, cuán conceptualmente separados están los disciplinas entre sí. Al comparar sus distancias basadas en hipergráficas con las obtenidas mediante proyecciones en cliques, encuentran que algunos pares de campos pueden moverse de relativamente cercanos a relativamente lejanos, o viceversa, según el método. Estos cambios muestran que las proyecciones pueden enmascarar estructura significativa, especialmente cuando muchos artículos abarcan más de dos campos.
Qué implica esto para mapear sistemas complejos
En todos los conjuntos de datos, los autores hallan que las proyecciones por pares funcionan razonablemente bien sólo cuando la mayoría de las interacciones involucran dos nodos, como en los contactos típicos en un aula. En sistemas donde son comunes grupos más grandes y con ponderaciones diversas, el enfoque de proyección puede subestimar o mal clasificar significativamente las distancias. La nueva medida preserva la información completa de orden superior sin dejar de ser manejable computacionalmente, e incluye de forma natural la distancia de grafos ordinaria como caso particular. Para los no especialistas, el mensaje clave es que, cuando intentamos cartografiar qué tan separados están ideas, personas o componentes en contextos grupales complejos, necesitamos herramientas que vayan más allá de los enlaces por pares. Esta noción de distancia basada en hipergráficas ofrece un mapa más fiel de la separación en las redes multilayer que subyacen a la ciencia y la sociedad modernas.
Cita: del Genio, C.I., Vasilyeva, E., Tupikina, L. et al. Distances in weighted higher-order networks. Commun Phys 9, 178 (2026). https://doi.org/10.1038/s42005-026-02592-w
Palabras clave: distancia en hipergráficas, redes de orden superior, distancia cognitiva, métricas de redes, datos de arXiv