Clear Sky Science · es
Conectando fases de la materia con la planitud del paisaje de pérdida en algoritmos variacionales cuánticos análogos
Por qué importa esto para los futuros ordenadores cuánticos
A medida que los ordenadores cuánticos pasan de curiosidades de laboratorio a herramientas prácticas, surge un gran desafío: muchos algoritmos prometedores se vuelven imposibles de entrenar conforme los dispositivos crecen. Este artículo explora una manera sorprendente de abordar ese problema tomando prestadas ideas de la física de la materia condensada. Los autores muestran cómo distintas “fases” de la materia cuántica—maneras en que un sistema de muchas partículas se organiza—pueden hacer que los algoritmos variacionales cuánticos sean entrenables o queden efectivamente estancados, y proponen una estrategia para mantenerlos entrenables en hardware cuántico análogo.
Aprendizaje cuántico compatible con el hardware
Los algoritmos variacionales cuánticos usan un dispositivo cuántico para preparar un estado cuántico ajustable y un ordenador clásico para girar las perillas hasta minimizar una magnitud objetivo, como la energía o un coste. La mayoría de los diseños existentes son “digitales”: construyen estados a partir de largas secuencias de puertas lógicas. Aunque son flexibles, estos circuitos pueden ser demasiado expresivos, explorando vastas regiones del espacio de estados cuánticos innecesarias para la tarea. En sistemas grandes esto puede causar el llamado problema de las llanuras estériles, donde el paisaje de pérdida se vuelve casi perfectamente plano y los gradientes se anulan exponencialmente con el tamaño del sistema. En lugar de ensamblar largas secuencias de puertas, los autores estudian un enfoque “análogo”: dejar que una cadena de espines cuánticos evolucione bajo sus interacciones naturales en una serie de cambios súbitos, o quenches, que son directamente implementables en plataformas como iones atrapados, átomos de Rydberg y circuitos superconductores. Controlando el desorden en la cadena de espines, pueden colocar cada quench en una de dos fases de la materia distintas, termalizada o localizada many-body, e investigar cómo esa elección moldea el comportamiento del algoritmo.
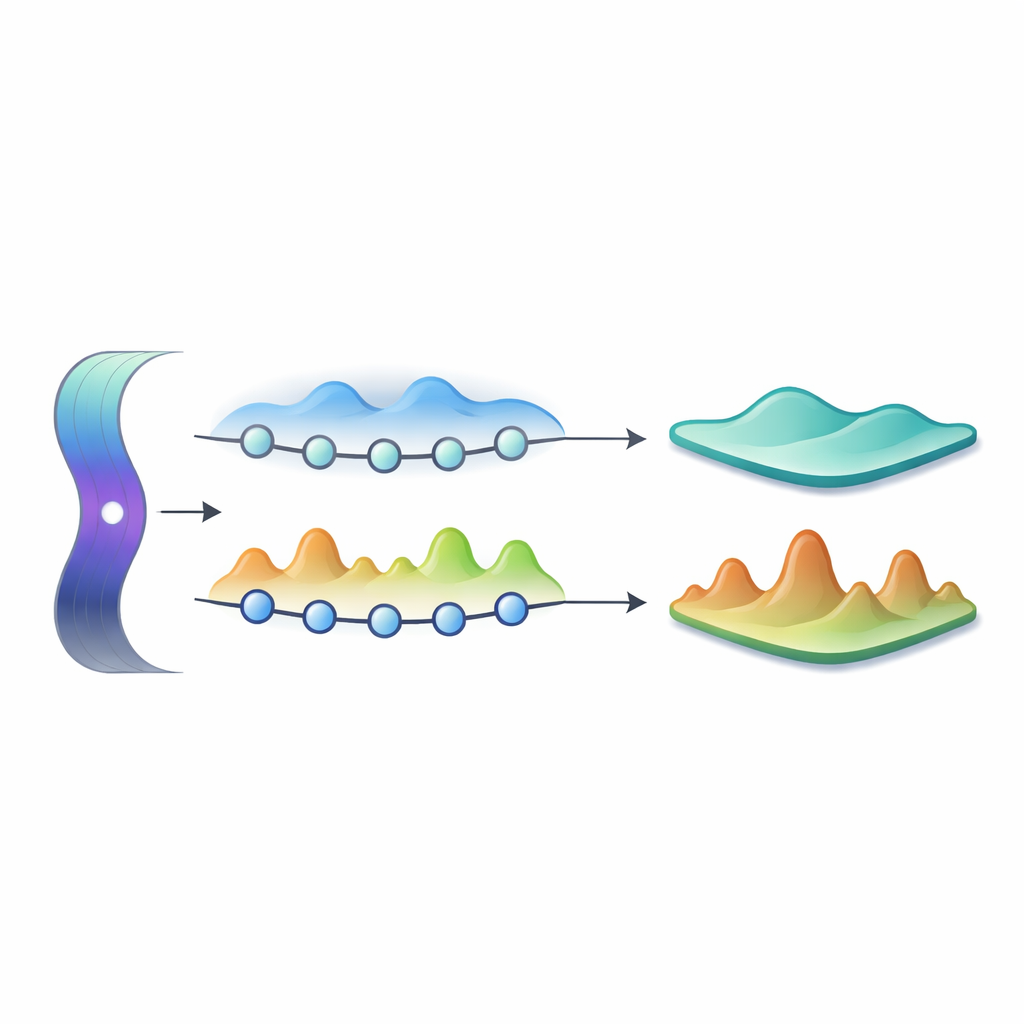
Dos fases, dos paisajes de aprendizaje muy distintos
En la fase termalizada, el sistema se comporta de forma caótica: las interacciones y un desorden débil propagan rápidamente información y entrelazamiento por todos los espines, impulsando la cadena hacia estados que se parecen a los producidos por un proceso cuántico totalmente aleatorio. En la fase localizada many-body (MBL), un desorden fuerte impide ese tipo de mezcla. Los patrones locales del estado inicial permanecen visibles durante tiempos muy largos, y el entrelazamiento crece solo lentamente. Los autores usan medidas cuantitativas de cuánto explora el ansatz del algoritmo el espacio de evoluciones cuánticas posibles—su expresividad—y relacionan esto con cuán plano se vuelve el paisaje de pérdida. Encuentran que ambas fases se vuelven expresivas al máximo si se aplican suficientes quenches, pero la fase termalizada alcanza ese régimen mucho antes. Al hacerlo, la varianza de la función de pérdida, y por tanto los gradientes necesarios para el aprendizaje, se reducen exponencialmente con el número de qubits, señalando llanuras estériles. En la fase MBL, el mismo destino ocurre finalmente, pero solo después de muchos más quenches.
Vinculando el crecimiento del entrelazamiento con la entrenabilidad
¿Por qué la fase MBL retrasa la aparición de paisajes planos? Los autores lo atribuyen a cómo se acumula el entrelazamiento. En el régimen termalizado, cada quench produce un gran salto en el entrelazamiento entre partes de la cadena de espines, y el sistema imita rápidamente estados totalmente aleatorios. Este rápido scrambling borra la estructura del paisaje de pérdida, haciendo que los gradientes sean extremadamente pequeños. En contraste, el régimen MBL genera entrelazamiento mucho más lentamente y de manera más localizada. Numéricamente, el número de quenches necesarios para que la varianza de la pérdida se sature sigue de cerca el número requerido para que el entrelazamiento se sature, y la brecha entre las dos fases crece aproximadamente de forma lineal con el tamaño del sistema. Esto significa que existe una ventana amplia en la que el ansatz basado en MBL ya es bastante expresivo pero aún no ha caído en una llanura estéril, mientras que el ansatz termalizado ya no es entrenable.
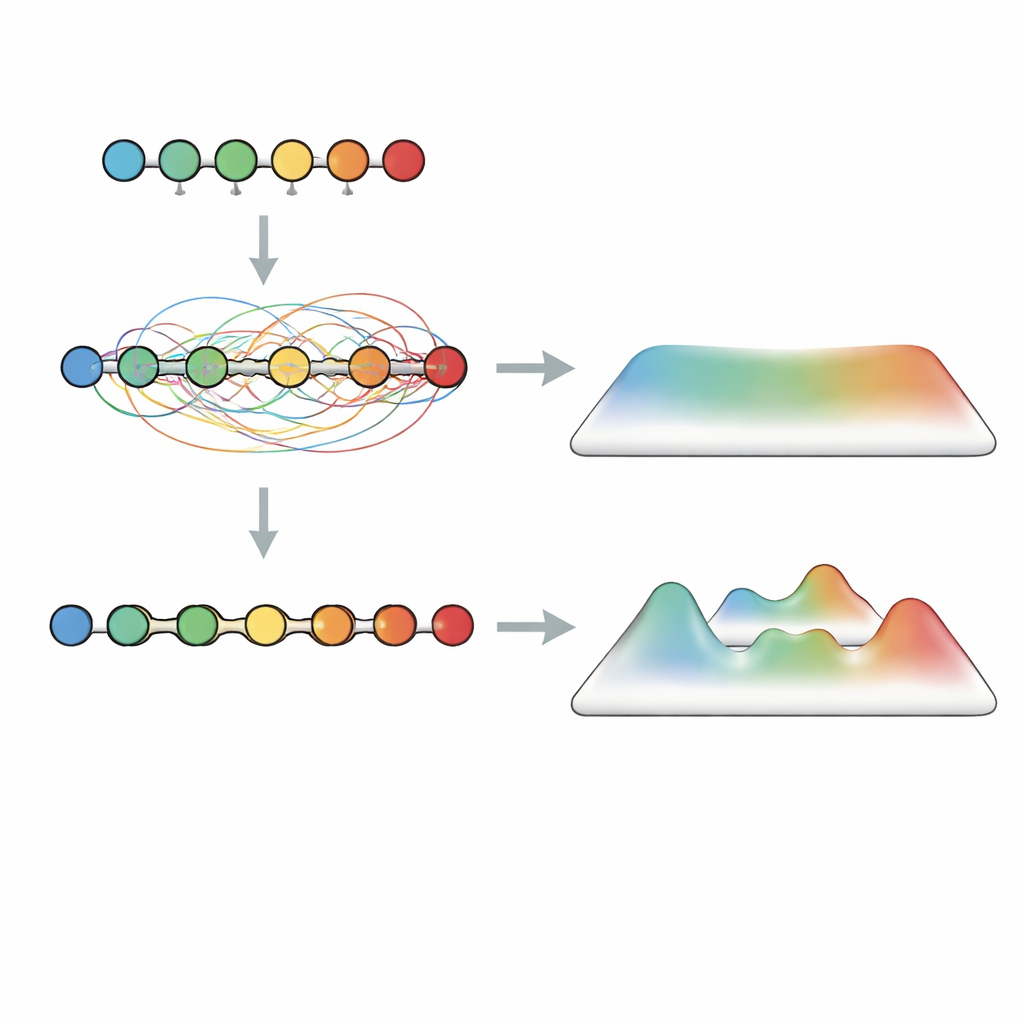
Una estrategia de inicialización que evita el fallo temprano
Partiendo de esta idea, los autores proponen una regla práctica para configurar algoritmos variacionales análogos. Elegir un número intermedio de quenches e inicializar el sistema en la fase MBL: la misma profundidad que ya sería demasiado profunda y plana en la fase termalizada sigue siendo entrenable en la fase MBL. Durante la optimización, los parámetros de control pueden entonces alejarse de la localización estricta si es necesario, ganando acceso a mayor expresividad sin haber empezado en una región plana. Pruebas en ejemplos pequeños pero no triviales apoyan esta imagen. Para ciertos problemas cuya estructura coincide estrechamente con el hardware, una configuración termalizada y poco profunda puede funcionar bien. Pero para objetivos más genéricos, como encontrar el estado fundamental de una cadena de Heisenberg o resolver instancias aleatorias de Max-Cut, la inicialización basada en MBL a profundidad intermedia ofrece una precisión energética significativamente mejor y soluciones de mayor calidad, con convergencia más fiable y menos instancias atrapadas en mínimos pobres.
Qué significa esto para escalar algoritmos cuánticos
El estudio sugiere que la física de las fases cuánticas no es solo un obstáculo o una curiosidad, sino una herramienta para diseñar mejores arquitecturas de aprendizaje cuántico. Al ajustar un dispositivo análogo hacia un régimen many-body localizado para la inicialización, se puede retrasar la aparición de llanuras estériles mientras se mantiene suficiente flexibilidad para aproximar estados complejos más adelante en el entrenamiento. Los autores enfatizan que esto no es una cura mágica: las llanuras estériles y otros problemas, como malos mínimos locales, aún pueden surgir, y el método es en gran medida agnóstico al problema. No obstante, ofrece pautas concretas y conscientes del hardware para construir algoritmos variacionales cuánticos análogos más escalables y apunta hacia un programa más amplio donde conceptos como la localización, los cristales temporales o el orden topológico ayuden a moldear los paisajes de aprendizaje de los ordenadores cuánticos del futuro.
Cita: Srimahajariyapong, K., Thanasilp, S. & Chotibut, T. Connecting phases of matter to the flatness of the loss landscape in analog variational quantum algorithms. Commun Phys 9, 111 (2026). https://doi.org/10.1038/s42005-026-02528-4
Palabras clave: algoritmos variacionales cuánticos, simulación cuántica análoga, localización many-body, llanuras estériles, aprendizaje automático cuántico