Clear Sky Science · es
RDE-DR: redes neuronales convolucionales profundas en ensamblaje robusto para la detección automatizada de retinopatía diabética a partir de imágenes del fondo de ojo
Por qué importan las exploraciones oculares en personas con diabetes
La retinopatía diabética es una complicación de la diabetes que daña lentamente el tejido sensible a la luz en la parte posterior del ojo. Si se detecta a tiempo, a menudo puede tratarse antes de que se pierda visión. Pero revisar miles de fotografías retinianas a mano lleva mucho tiempo para los especialistas. Este estudio explora cómo una combinación cuidadosamente diseñada de modelos de inteligencia artificial puede ayudar a cribar estas imágenes de forma más fiable, de modo que las personas en riesgo sean señaladas antes y los pacientes sanos eviten seguimientos innecesarios.
Buscando signos de alarma en fotografías oculares
Los investigadores se centran en fotografías en color de la retina, conocidas como imágenes de fondo de ojo, procedentes de una colección pública llamada conjunto de datos APTOS 2019. Estas imágenes muestran diminutos vasos sanguíneos y manchas de sangrado o filtración que señalan daño diabético. El equipo convierte las cinco categorías médicas originales en una pregunta más simple que importa para el cribado a gran escala: ¿muestra este ojo retinopatía diabética o no? Esto convierte la tarea en una decisión de sí o no que un sistema automatizado podría tomar rápidamente para miles de pacientes.
Haciendo los detalles ocultos más fáciles de ver para los ordenadores
Las fotografías oculares del mundo real varían mucho en nitidez, brillo y color, lo que puede confundir a los modelos computacionales. Para reducir este problema, los autores usan una técnica de realce de contraste llamada CLAHE que aclara detalles locales sin exagerar el ruido. Redimensionan todas las imágenes a un cuadrado pequeño estándar, normalizan los colores y aplican rotaciones y volteos aleatorios durante el entrenamiento para que el sistema no se sobreajuste a un único ángulo de cámara o condición de iluminación. El conjunto de datos se divide de modo que cuatro quintas partes de las imágenes entrenan a los modelos y una quinta se reserva para probar qué tan bien generaliza el sistema a casos nuevos.
Muchos ojos en lugar de uno
En lugar de depender de un único modelo de aprendizaje profundo, el estudio entrena cuatro redes neuronales convolucionales populares que se desarrollaron inicialmente con una gran colección de fotos cotidianas. Estos modelos, conocidos en el campo como VGG16, VGG19, ResNet50 y DenseNet121, se reentrenan para reconocer retinas sanas y enfermas. Cada uno ya rinde muy bien por sí solo, clasificando correctamente alrededor del 98 por ciento de las imágenes de prueba y fallando solo en unos pocos ojos enfermos. La idea clave del trabajo es combinar sus fortalezas mediante varios esquemas de fusión de decisiones, incluyendo votación simple, promedio de confianza y reglas más avanzadas inspiradas en la lógica difusa.
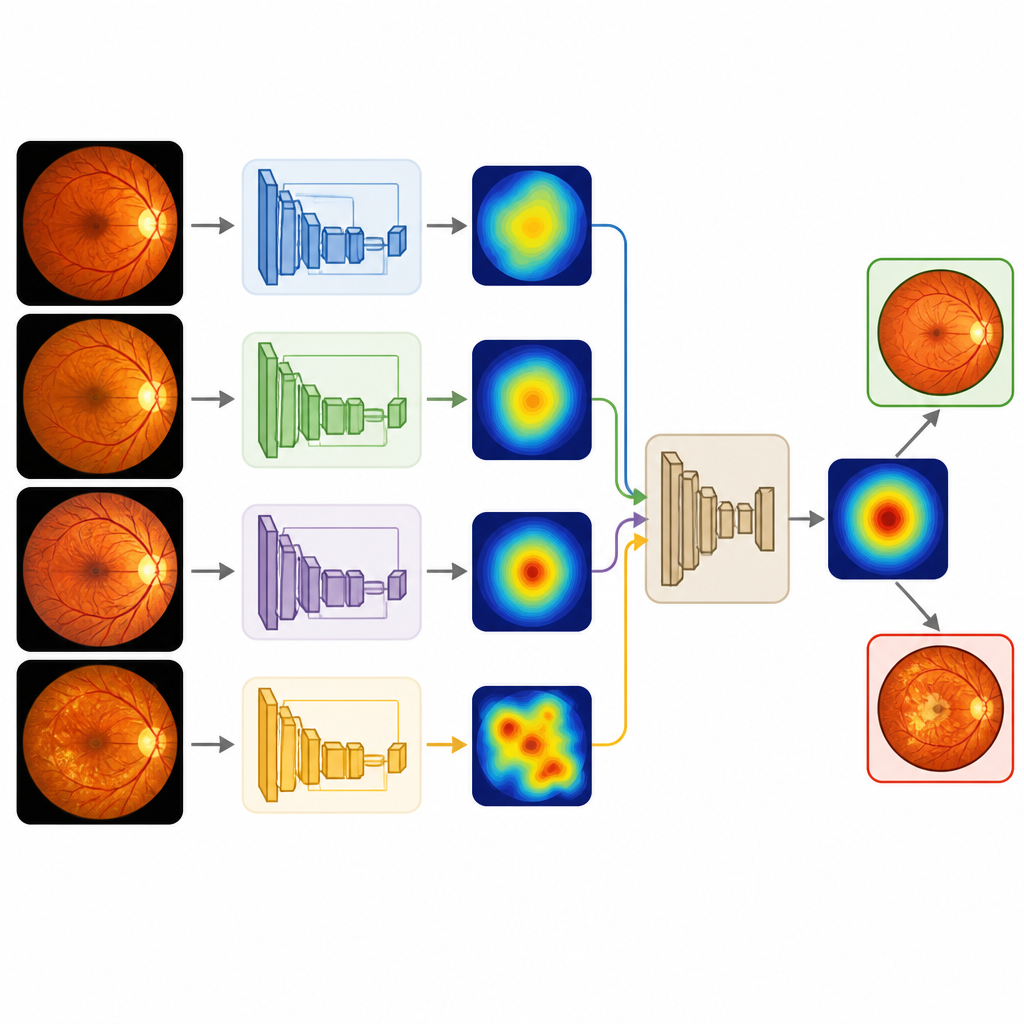
Combinando las opiniones de los modelos con cuidado
El equipo estudia sistemáticamente siete formas de mezclar las salidas de los cuatro modelos, siempre bajo la misma receta de entrenamiento. También ajustan finamente el punto de corte donde una probabilidad se convierte en una predicción de sí o no, en lugar de asumir un umbral fijo en la mitad. Al explorar muchos umbrales, miden cómo se compensan precisión, sensibilidad y valor predictivo, lo cual es crucial para herramientas de cribado que deben evitar tanto detecciones perdidas como alarmas falsas excesivas. Luego van más allá de la simple exactitud, examinando con qué confianza los modelos separan imágenes sanas de las enfermas usando curvas ROC y gráficos de densidad de probabilidad.
Qué significan los resultados para el cribado ocular futuro
En general, los métodos en ensamblaje mantienen o mejoran ligeramente los ya sólidos resultados de los modelos individuales, alcanzando alrededor del 98,6 por ciento de exactitud y una puntuación muy alta en la separación de clases. Esquemas simples como la votación mayoritaria o el promedio de las confidencias resultan notablemente estables, mientras que uno de los métodos difusos resulta más sensible a las elecciones de diseño y ofrece un rendimiento menos equilibrado. Para un público general, el mensaje principal es que combinar varios lectores de imágenes bien entrenados, tras limpiar cuidadosamente las fotos y ajustar cómo se fusionan sus votos, conduce a un asistente automatizado más fiable. Tal herramienta no reemplazará a los oftalmólogos, pero podría ayudarles a clasificar rápidamente grandes cantidades de fotografías retinianas, enfocando el tiempo de clínica en los pacientes cuyos ojos muestran signos tempranos de problemas.
Cita: Aiche, I., Brik, Y., Attallah, B. et al. RDE-DR: robust deep ensemble CNNs for automated diabetic retinopathy detection from fundus images. Sci Rep 16, 15226 (2026). https://doi.org/10.1038/s41598-026-48669-y
Palabras clave: retinopatía diabética, imágenes del fondo de ojo, aprendizaje profundo, modelos en ensamblaje, cribado médico