Clear Sky Science · es
Aprendizaje profundo para la predicción de tasas de incidencia y la evaluación del riesgo por radiación de tumores sólidos
Por qué esto importa en la vida cotidiana
Todos estamos expuestos a bajos niveles de radiación procedentes de exploraciones médicas, vuelos en avión y el entorno. Los reguladores utilizan modelos para estimar cuánto puede aumentar esta radiación nuestras probabilidades de desarrollar cáncer. Este estudio plantea si la inteligencia artificial moderna, en concreto el aprendizaje profundo, puede mejorar esas estimaciones en comparación con las fórmulas tradicionales que han guiado las normas de seguridad durante décadas.
Un conjunto de datos humanos único y a largo plazo
La investigación se centra en el Life Span Study, una investigación de larga duración sobre más de 100.000 supervivientes de las bombas atómicas de Hiroshima y Nagasaki. Para cada subgrupo de supervivientes, los científicos conocen la dosis de radiación recibida, el tiempo de seguimiento y cuántos tumores sólidos ocurrieron. Los autores usan una tabla persona-año, que resume los casos de cáncer y el tiempo de riesgo a lo largo de combinaciones de edad, edad a la exposición, sexo, ciudad y dosis. Este rico conjunto de datos ha sido la columna vertebral de las guías de protección contra la radiación en todo el mundo, lo que lo convierte en un banco de pruebas ideal para nuevos enfoques de modelización.
Reglas antiguas frente a nuevas máquinas de aprendizaje
Tradicionalmente, el riesgo por radiación en esta cohorte se ha estimado con los llamados modelos paramétricos. Estos se basan en fórmulas matemáticas preseleccionadas que describen cómo debería cambiar el riesgo con la dosis, la edad y otros factores. Son transparentes y relativamente fáciles de interpretar, pero pueden equivocarse si las fórmulas elegidas no coinciden con los patrones reales de los datos. En contraste, las redes neuronales profundas aprenden las relaciones directamente de los datos a través de múltiples capas de “unidades” conectadas, sin asumir una forma matemática particular para la curva dosis–respuesta. Los autores construyeron una red neuronal que recibe seis entradas—dos medidas de edad, sexo, ciudad, ubicación en el momento de la bomba y dosis—y predice las tasas de incidencia de tumores para cada celda de la tabla persona-año.
¿Qué tan bien predice el aprendizaje profundo las tasas de cáncer?
El equipo comparó cuatro modelos: un modelo “nulo” simple basado en promedios, un modelo lineal estándar, un modelo paramétrico tradicional de riesgo por radiación y la red neuronal profunda. Usando validación cruzada repetida, evaluaron el rendimiento con varias medidas de error estándar. La red neuronal produjo el error más bajo en todos los métricos, pero solo ligeramente mejor que el modelo paramétrico sofisticado. Ambos modelos avanzados reprodujeron de forma cercana las tasas observadas de tumores a lo largo de grupos de edad y la mayoría de las categorías de dosis, aunque cada uno mostró discrepancias mayores en las dosis más altas y en las edades más avanzadas. En otras palabras, el aprendizaje profundo no superó de forma espectacular al mejor modelo convencional en cuanto a predecir cuántos tumores ocurren, pero fue al menos igual de bueno y a menudo algo mejor, a costa de un tiempo de cálculo y una complejidad mucho mayores.
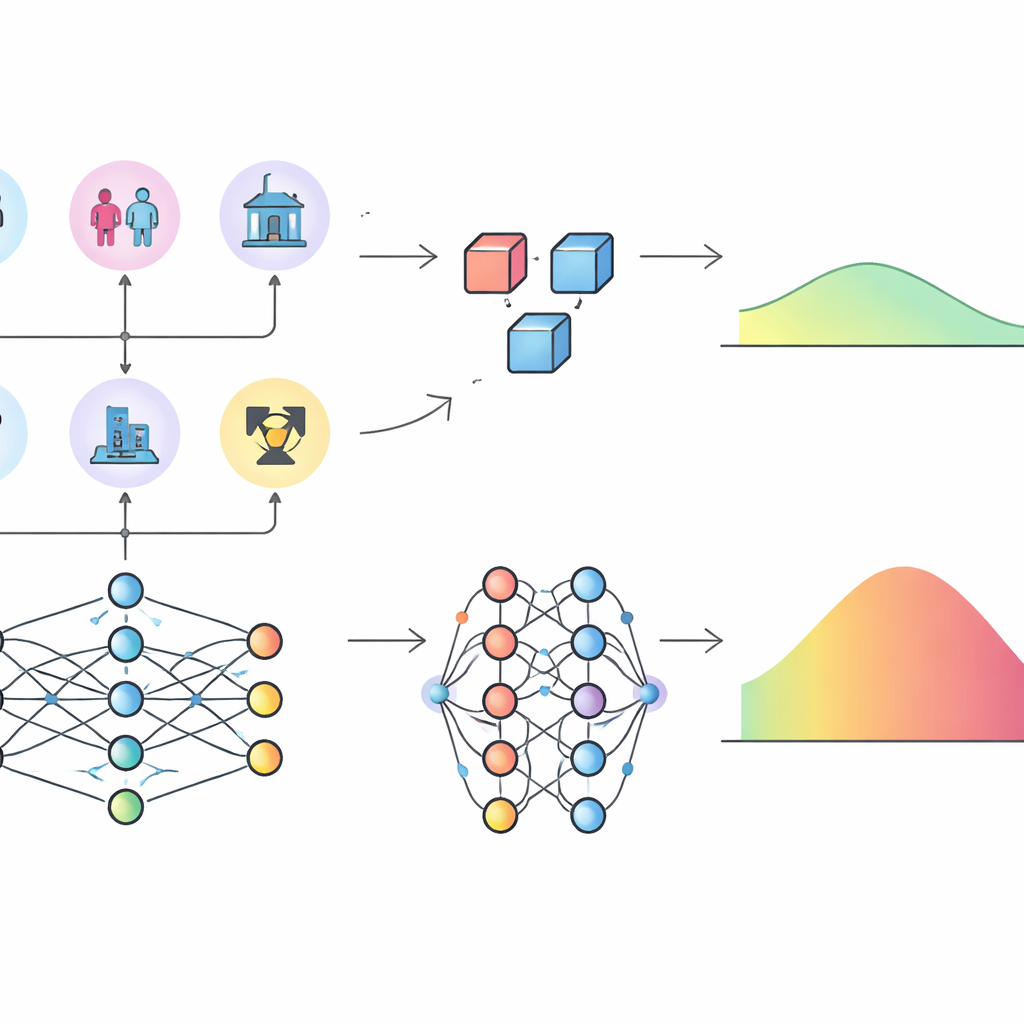
Diferentes imágenes de cómo se construye el riesgo por radiación
La diferencia más llamativa surgió cuando los autores examinaron el exceso de riesgo relativo (ERR), una forma común de expresar cuánto multiplica la radiación el riesgo basal de cáncer de una persona. Usando su red neuronal, estimaron el ERR para cada celda comparando las tasas de tumores predichas con y sin dosis de radiación, manteniendo constantes los demás factores. Aunque la red neuronal y el modelo paramétrico predijeron recuentos de tumores similares, los valores de ERR resultantes difirieron notablemente a lo largo del rango de dosis: el modelo paramétrico tendía a dar estimaciones de ERR más altas y más dispersas. Para indagar por qué, los investigadores aplicaron valores SHAP, un método basado en la teoría de juegos que asigna a cada variable de entrada una contribución a las predicciones del modelo. Para las tasas generales de tumores, ambos modelos coincidieron en que la edad alcanzada, la edad a la exposición, la dosis y el sexo eran las influencias más importantes. Pero para el ERR, la red neuronal destacó la dosis de radiación como el factor dominante, con la edad desempeñando un papel de apoyo menor, mientras que el modelo paramétrico atribuyó un papel mucho más fuerte a la edad a la exposición y a la edad alcanzada debido a la forma en que su fórmula se especificó de antemano.
Límites, desafíos y usos futuros
El estudio subraya que el aprendizaje profundo, aunque flexible, sigue siendo una “caja negra” para muchos usuarios. No proporciona de forma natural los números resumen sencillos—como “incremento de riesgo por unidad de dosis”—a los que están acostumbrados los reguladores, y estimar bandas de incertidumbre para sus predicciones es técnicamente desafiante, especialmente cuando se usan datos resumidos persona-año. Los modelos también pueden sobreajustarse a particularidades sutiles de los datos si no se controlan cuidadosamente, y requieren mucha más potencia de cálculo que los enfoques tradicionales. Los autores sostienen que el aprendizaje profundo no debería reemplazar a los modelos paramétricos bien diseñados, pero puede servir como un compañero potente: puede revelar patrones no lineales o interacciones ocultas y sugerir mejores formas funcionales para modelos más simples que sigan siendo más fáciles de explicar y regular.
Qué significa esto para la seguridad radiológica
Para un lector general, la conclusión es que las herramientas modernas de IA pueden igualar o mejorar ligeramente los métodos tradicionales al predecir las tasas de cáncer relacionadas con la radiación en un conjunto de datos humanos clave. Sin embargo, pueden ofrecer una imagen distinta sobre qué factores importan más, en particular cuánto influye la edad en el riesgo por radiación. En lugar de derribar el conocimiento existente, este trabajo pone de relieve cómo las elecciones de modelo pueden cambiar la importancia aparente de la dosis frente a la edad y solicita combinar el aprendizaje profundo con modelos transparentes dirigidos por expertos. A largo plazo, un enfoque híbrido de este tipo podría respaldar guías de protección radiológica más matizadas y fiables para la atención médica, los lugares de trabajo y el medio ambiente.
Cita: Liu, Z., Nakamizo, T., Misumi, M. et al. Deep learning for incidence rate prediction and radiation risk assessment of solid tumors. Sci Rep 16, 10577 (2026). https://doi.org/10.1038/s41598-026-46756-8
Palabras clave: riesgo por radiación, aprendizaje profundo, incidencia de cáncer, supervivientes de la bomba atómica, modelización del riesgo