Clear Sky Science · en
Deep learning for incidence rate prediction and radiation risk assessment of solid tumors
Why this matters to everyday life
We are all exposed to low levels of radiation from medical scans, airplane flights, and the environment. Regulators use models to estimate how much this radiation might raise our chances of developing cancer. This study asks whether modern artificial intelligence, specifically deep learning, can improve those estimates compared with the traditional formulas that have guided safety rules for decades.
A unique long-term human dataset
The research centers on the Life Span Study, a long-running investigation of more than 100,000 survivors of the atomic bombings in Hiroshima and Nagasaki. For each subgroup of survivors, scientists know how much radiation they received, how long they were followed, and how many solid tumors occurred. The authors use a person-year table, which summarizes cancer cases and time at risk across combinations of age, age at exposure, sex, city, and dose. This rich dataset has been the backbone of radiation protection guidelines worldwide, making it an ideal test bed for new modeling approaches.
Old rules versus new learning machines
Traditionally, radiation risk in this cohort has been estimated with so-called parametric models. These rely on pre-chosen mathematical formulas that describe how risk should change with dose, age, and other factors. They are transparent and relatively easy to interpret but can be wrong if the chosen formulas do not match the real patterns in the data. In contrast, deep neural networks learn relationships directly from data through multiple layers of connected “units,” without assuming a particular mathematical shape for the dose–response curve. The authors built a neural network that takes in six inputs—two age measures, sex, city, location at the time of the bombing, and dose—and predicts tumor incidence rates for each cell in the person-year table.
How well does deep learning predict cancer rates?
The team compared four models: a simple average-based “null” model, a standard linear model, a traditional parametric radiation risk model, and the deep neural network. Using repeated cross-validation, they judged performance with several standard error measures. The neural network yielded the lowest error across all metrics, but only slightly better than the sophisticated parametric model. Both advanced models closely matched observed tumor rates across age groups and most dose categories, although each showed larger mismatches at the very highest doses and oldest ages. In other words, deep learning did not dramatically outperform the best conventional model in terms of predicting how many tumors occur, but it was at least as good and often a bit better, at the cost of far greater computation time and complexity.
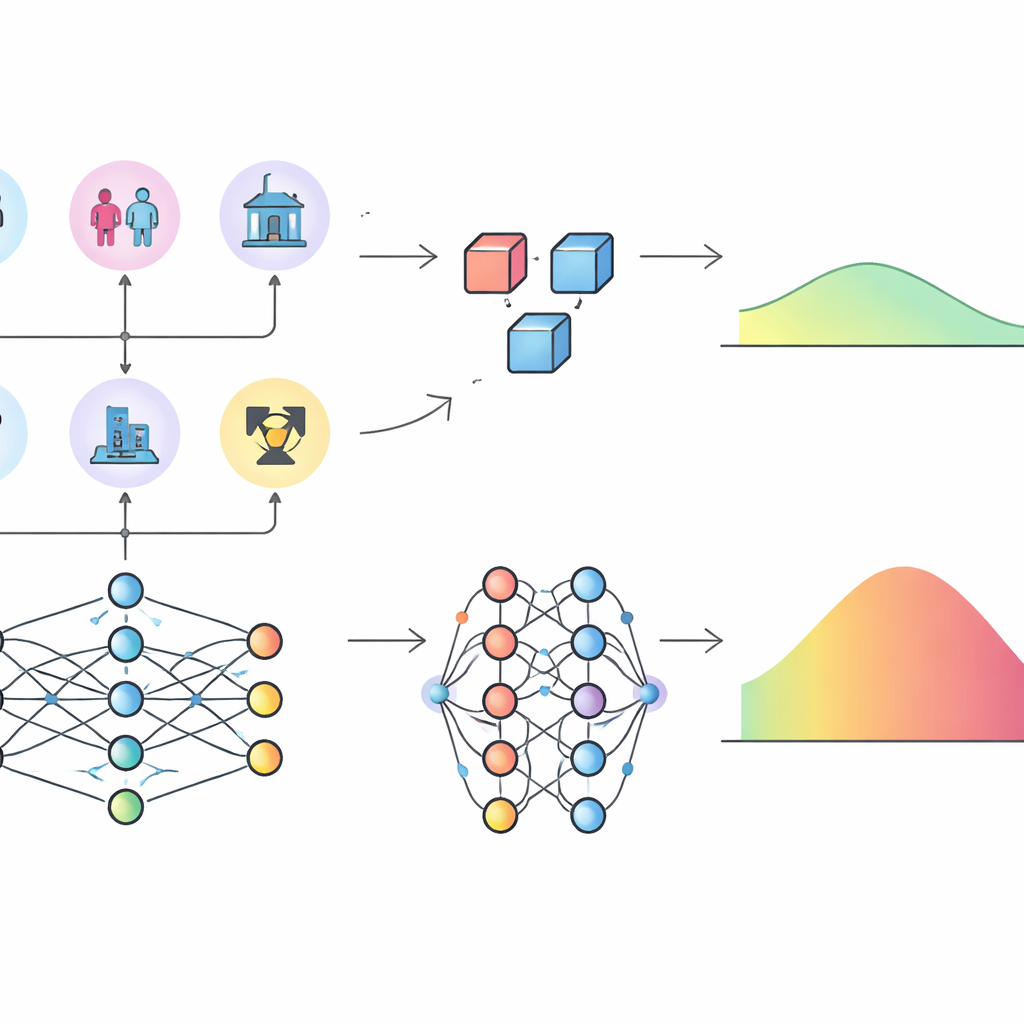
Different pictures of how radiation risk is built
The more striking difference emerged when the authors examined excess relative risk (ERR), a common way of expressing how much radiation multiplies someone’s baseline cancer risk. Using their neural network, they estimated ERR for each cell by comparing predicted tumor rates with and without radiation dose, holding other factors constant. Even though the neural network and the parametric model predicted similar tumor counts, the resulting ERR values differed notably across the dose range: the parametric model tended to give higher and more widely spread ERR estimates. To probe why, the researchers applied SHAP values, a game-theory-based method that assigns to each input variable a contribution to the model’s predictions. For overall tumor rates, both models agreed that attained age, age at exposure, dose, and sex were the most important influences. But for ERR, the neural network highlighted radiation dose as the dominant factor, with age playing a smaller supporting role, while the parametric model attributed a much stronger role to age at exposure and attained age because of the way its formula was specified in advance.
Limits, challenges, and future uses
The study underscores that deep learning, while flexible, is still a “black box” for many users. It does not naturally provide the simple summary numbers—such as “risk increase per unit dose”—that regulators are used to, and estimating uncertainty bands for its predictions is technically challenging, especially when using summarized person-year data. The models can also overfit subtle quirks in the data if not carefully controlled, and they require far more computing power than traditional approaches. The authors argue that deep learning should not replace well-crafted parametric models but can serve as a powerful companion: it can reveal hidden nonlinear patterns or interactions and suggest better functional forms for simpler models that remain easier to explain and regulate.
What this means for radiation safety
For a lay reader, the takeaway is that modern AI tools can match or slightly improve on traditional methods when predicting radiation-related cancer rates in a key human dataset. However, they may paint a different picture of which factors matter most, particularly how strongly age shapes radiation risk. Rather than overturning existing knowledge, this work highlights how model choices can shift the apparent importance of dose versus age and calls for combining deep learning with expert-guided, transparent models. In the long run, such a hybrid approach could support more nuanced and reliable radiation protection guidelines for medical care, workplaces, and the environment.
Citation: Liu, Z., Nakamizo, T., Misumi, M. et al. Deep learning for incidence rate prediction and radiation risk assessment of solid tumors. Sci Rep 16, 10577 (2026). https://doi.org/10.1038/s41598-026-46756-8
Keywords: radiation risk, deep learning, cancer incidence, atomic bomb survivors, risk modeling