Clear Sky Science · es
Modelo de reconocimiento de bocetos basado en una red CycleGAN mejorada y un mecanismo de atención dual
Enseñar a las computadoras a entender garabatos
Desde bocetos en servilletas hasta garabatos en pizarras, los dibujos rápidos son una de las formas más naturales en que las personas comparten ideas. Pero para las computadoras, estas líneas escasas son sorprendentemente difíciles de interpretar. Este artículo presenta un nuevo modelo de inteligencia artificial capaz de reconocer bocetos hechos a mano con una precisión notable, acercándonos a aplicaciones que pueden convertir instantáneamente garabatos en imágenes pulidas, iconos buscables o diseños interactivos.
Por qué los bocetos son tan difíciles para las máquinas
A diferencia de las fotografías a todo color, los bocetos están compuestos por solo unos pocos trazos. Diferentes personas dibujan el mismo objeto de formas muy dispares, y los detalles importantes pueden estar ausentes, ser tenues o estar colocados de manera desigual en la página. Los sistemas de reconocimiento tradicionales dependen de reglas cuidadosamente diseñadas o de características estándar de imagen, y a menudo confunden variaciones sutiles en las líneas con diferencias significativas. Como resultado, pueden confundir objetos similares, como un zorro y un perro, o tener dificultades con dibujos desordenados o casuales. Los investigadores han recurrido al aprendizaje profundo para aprender patrones directamente de los datos, pero incluso los sistemas modernos pueden tropezar cuando los bocetos son demasiado simples, ruidosos o variados.

Una forma más inteligente de mirar los dibujos lineales
Los autores abordan estos desafíos con un modelo que trata la comprensión de bocetos como un proceso en dos pasos: primero, facilitar que la computadora “vea” el boceto, y luego enfocar su atención en las partes más informativas. En el corazón de su enfoque está una versión mejorada de un potente marco de traducción de imágenes conocido como CycleGAN. En lugar de analizar el dibujo una sola vez, la red lo somete a múltiples filtros direccionales que ven los trazos desde varios ángulos, capturando bordes y contornos de forma más completa. Un módulo de balance de brillo nivela luego las áreas claras y oscuras para que las diferencias de sombreado o una iluminación deficiente no confundan al sistema. En conjunto, estos pasos convierten los garabatos crudos en representaciones internas más ricas que resaltan la estructura subyacente del objeto.
Enseñar a la red en qué prestar atención
Incluso con mejores características, un boceto sigue conteniendo una mezcla de trazos útiles y detalles que distraen. Para separar la señal del ruido, el modelo utiliza un mecanismo de atención dual inspirado en cómo los humanos dirigen su mirada. Una parte, llamada atención por canal, examina diferentes conjuntos de características extraídas y potencia aquellas que mejor distinguen una categoría de otra, como el contorno circular de una rueda o el pico de un pájaro. La otra parte, atención espacial, se concentra en regiones específicas del boceto, enfatizando dónde se encuentran los trazos más informativos mientras atenúa las áreas en blanco o desordenadas. Estas dos formas de atención trabajan conjuntamente para que el modelo no solo vea más, sino que también sepa qué ignorar.
Poner el modelo a prueba
Tras extraer y refinar las características del boceto, el sistema las introduce en un clasificador compacto que combina un promedio global con capas convolucionales adicionales para tomar la decisión final sobre lo que representa el boceto. Los investigadores entrenaron y evaluaron su modelo en dos colecciones de bocetos ampliamente usadas: TU-Berlin, con 25.000 dibujos de objetos cotidianos, y QuickDraw, con millones de garabatos casuales recogidos de jugadores en línea. Para mantener la prueba realista, redimensionaron las imágenes, eliminaron el ruido y dividieron los datos en conjuntos separados de entrenamiento y prueba. En estos puntos de referencia, el nuevo modelo superó consistentemente a los métodos existentes, alcanzando una precisión superior al 97% en ambos conjuntos y venciendo a varios competidores de última generación en precisión, recall y en una puntuación combinada conocida como medida F1.
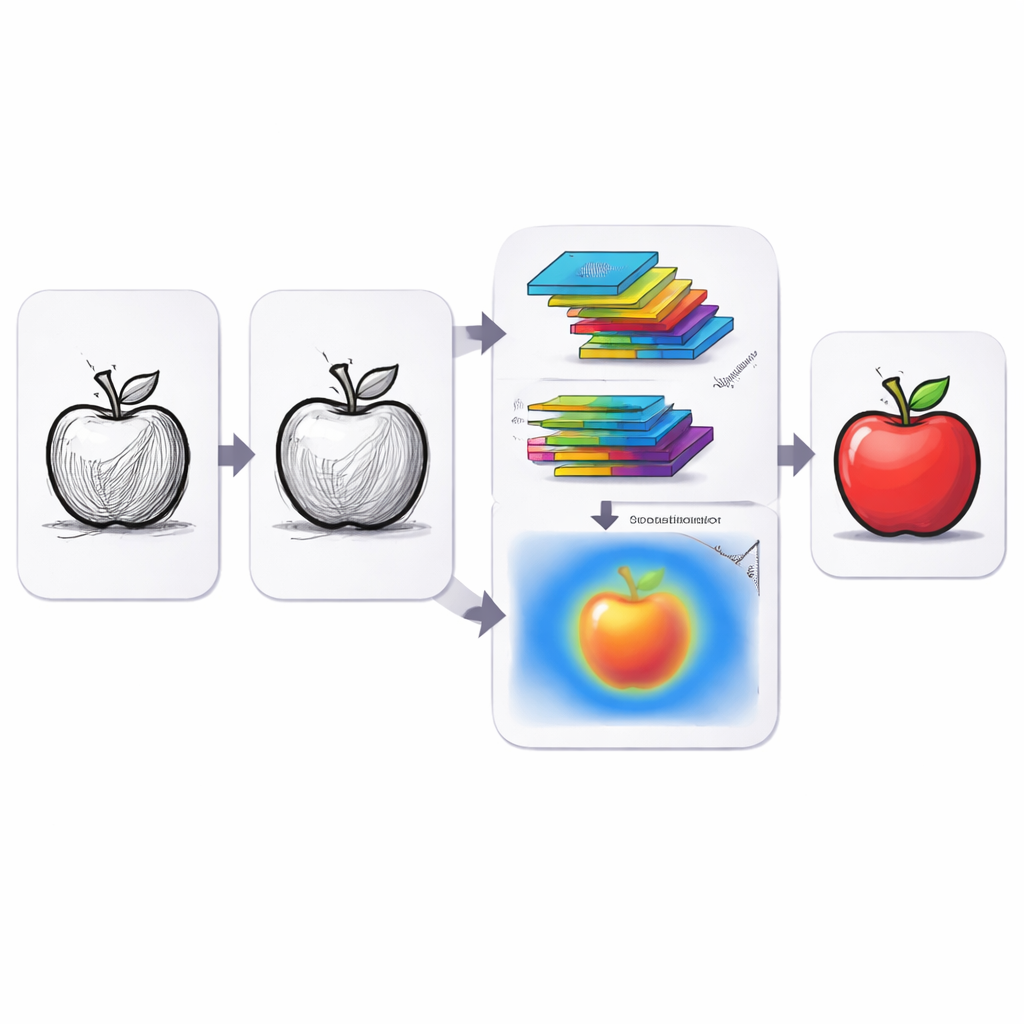
Qué significa esto para las herramientas cotidianas
Para quienes no son expertos, los detalles técnicos se reducen a un mensaje simple: este modelo hace que las computadoras sean mucho mejores para entender dibujos aproximados. Al rediseñar cómo el sistema extrae las líneas, nivela el brillo y dirige su atención, los autores demuestran que las máquinas pueden reconocer de forma fiable incluso bocetos escasos y peculiares. Esto abre la puerta a motores de búsqueda basados en dibujos, software de diseño que convierte garabatos rápidos en obras pulidas y formas más naturales de interactuar con dispositivos sin clics precisos del ratón ni habilidades artísticas profesionales. Aunque el sistema todavía puede confundir categorías muy similares, trabajos futuros que combinen el análisis de bocetos con señales lingüísticas podrían cerrar esa brecha, haciendo del dibujo a mano alzada una interfaz verdaderamente universal entre personas y máquinas.
Cita: Wang, Y., Xie, L. & Huang, M. Sketch recognition model based on improved CycleGAN network and dual attention mechanism. Sci Rep 16, 14014 (2026). https://doi.org/10.1038/s41598-026-44146-8
Palabras clave: reconocimiento de bocetos, aprendizaje profundo, CycleGAN, mecanismo de atención, interacción humano-computadora