Clear Sky Science · es
Voces de personas anteriormente esclavizadas: Un nuevo corpus de textos de relatos por personas anteriormente esclavizadas
Escuchar historias largamente silenciadas
Durante generaciones, las vidas cotidianas de las personas esclavizadas y anteriormente esclavizadas se han contado con frecuencia a través de registros de plantaciones, tablas del censo y las voces de los propietarios de esclavos. Este artículo presenta una nueva manera de escuchar directamente a quienes vivieron la esclavitud: una colección amplia y de acceso abierto de historias de vida y entrevistas en formato digital. Al convertir con cuidado libros frágiles y viejos tipos escritos en un recurso consultable, el proyecto facilita enormemente que cualquiera —desde historiadores hasta lectores curiosos— explore cómo las personas describieron sus propias experiencias de cautiverio y libertad.
Reunir muchas voces en un solo lugar
El núcleo del proyecto es un corpus de texto llamado “Voces de las personas anteriormente esclavizadas”. Reúne dos tipos principales de fuentes de Estados Unidos y de partes del Caribe. El primero consiste en casi doscientas autobiografías en primera persona de personas que habían sido esclavizadas, la mayoría publicadas originalmente en el siglo XIX y preservadas en la colección Documenting the American South. El segundo consiste en más de dos mil entrevistas realizadas en la década de 1930 por el Federal Writers’ Project, en las que hombres y mujeres mayores recordaron su infancia bajo la esclavitud. Todos estos textos están en dominio público, y el equipo ha conseguido permisos para reutilizar las versiones digitalizadas cuando ha sido necesario.
De páginas antiguas a datos inteligentes
Convertir páginas históricas en texto digital fiable está lejos de ser sencillo. Los esfuerzos de digitalización anteriores introdujeron muchos errores: letras leídas como números, orden de palabras confuso y limpiezas de ortografía inconsistentes. Por ello, los investigadores volvieron a procesar el material con una herramienta moderna de reconocimiento óptico de caracteres y compararon varias versiones, incluidas las de la Library of Congress y Project Gutenberg. Midieron la frecuencia con la que se leían mal caracteres y palabras completas, y luego usaron transcripciones “oro” cuidadosamente verificadas para afinar el proceso. Esto les permitió identificar qué enfoques producían las versiones más precisas y dónde todavía era necesaria la corrección manual.
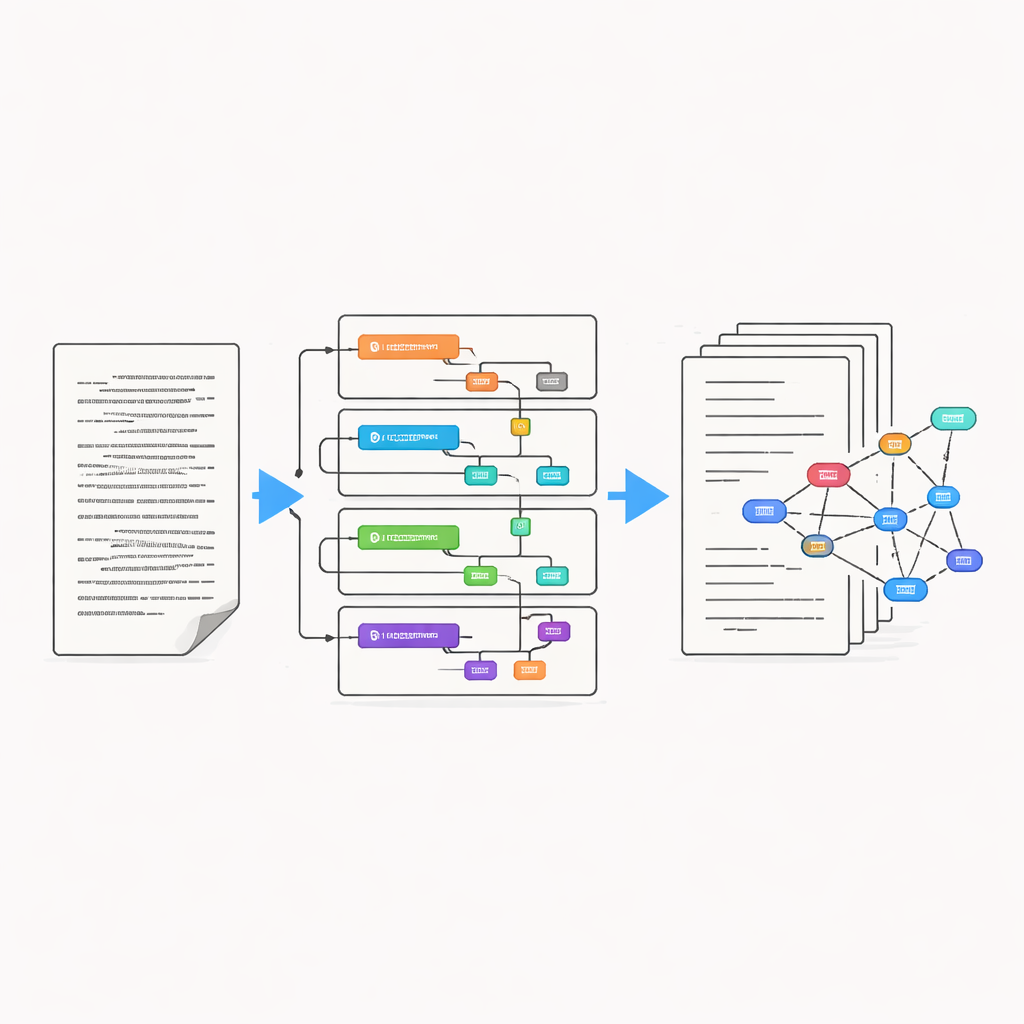
Añadir capas de significado
Una vez que el texto básico estuvo en buen estado, el equipo lo enriqueció con numerosas capas adicionales de información. Usando un canal de procesamiento de lenguaje, marcaron límites de oración, tipos de palabras, formas de diccionario y relaciones gramaticales. También comenzaron a identificar nombres de personas y lugares y crearon metadatos detallados, como cuándo y dónde se grabó una entrevista, el género del principal hablante y si una página reflejaba inglés estándar impreso o un intento de capturar el vernáculo hablado. Se prestó atención especial a la forma en que los entrevistadores registraron el habla afroamericana de la época, que a menudo aparece en grafías no estándar como “gwine” por “going” y puede ser difícil de analizar para las computadoras.
Explorar el lenguaje y la experiencia
Estas capas técnicas abren nuevas ventanas tanto sobre la historia como sobre el lenguaje. Con millones de palabras ahora organizadas y anotadas, los investigadores pueden realizar búsquedas a gran escala para hallar patrones: cómo la gente hablaba sobre trabajo, familia, castigo o libertad, y cómo esos patrones cambiaron a lo largo del tiempo o de un lugar a otro. Experimentos iniciales con modelos de incrustación de palabras —herramientas que agrupan palabras por significados similares— ya han revelado distinciones sutiles. Por ejemplo, en relatos en primera persona de personas anteriormente esclavizadas, términos como “man” y “person” tienden a referirse a personas sin distinción de procedencia, mientras que en otros textos contemporáneos “man” está más vinculado a sujetos blancos y “person” a afroamericanos. Hallazgos como ese sugieren que el corpus puede arrojar luz sobre cómo el lenguaje codificó la raza y el estatus.
Un recurso vivo para un patrimonio compartido
El resultado principal del artículo no es una única afirmación histórica sino un recurso de investigación duradero y compartido públicamente. La versión 0.1 del corpus ya está disponible, completa con documentación, análisis de ejemplo y código para reproducir o ampliar el trabajo. Las próximas versiones añadirán más entrevistas, información geográfica más rica, análisis de temas y de sentimiento, y herramientas adicionales para la exploración. Para un lector general, el mensaje clave es que voces largamente confinadas en archivos dispersos ahora se están reuniendo, limpiando y amplificando con cuidado. Este corpus digital preserva las palabras de las personas anteriormente esclavizadas como parte de nuestro patrimonio cultural común y facilita mucho que académicos, estudiantes y el público aprendan de lo que eligieron decir sobre sus propias vidas.
Cita: Elmerot, I., Olsson, LJ. & Rönnbäck, K. Volces of formerly enslaved: A new text corpus of narratives by formerly enslaved persons. Sci Data 13, 682 (2026). https://doi.org/10.1038/s41597-026-07340-x
Palabras clave: relatos de esclavos, humanidades digitales, lingüística histórica, historia afroamericana, corpus de texto