Clear Sky Science · en
Volces of formerly enslaved: A new text corpus of narratives by formerly enslaved persons
Hearing Long-Silenced Stories
For generations, the everyday lives of enslaved and formerly enslaved people have often been told through plantation records, census tables, and the voices of slaveholders. This article introduces a new way to listen directly to those who lived through slavery: a large, openly available collection of life stories and interviews in digital form. By carefully turning fragile books and old typescripts into a searchable resource, the project makes it far easier for anyone—from historians to curious readers—to explore how people described their own experiences of bondage and freedom.
Gathering Many Voices Into One Place
The heart of the project is a text corpus called “Voices of the Formerly Enslaved.” It brings together two major kinds of sources from the United States and parts of the Caribbean. The first consists of nearly two hundred first-person autobiographies by people who had been enslaved, most originally published in the 1800s and preserved in the Documenting the American South collection. The second consists of more than two thousand interviews conducted in the 1930s by the Federal Writers’ Project, in which elderly men and women looked back on their childhoods in slavery. All of these texts are in the public domain, and the team has secured permission to reuse the digitized versions where needed.
From Old Pages to Smart Data
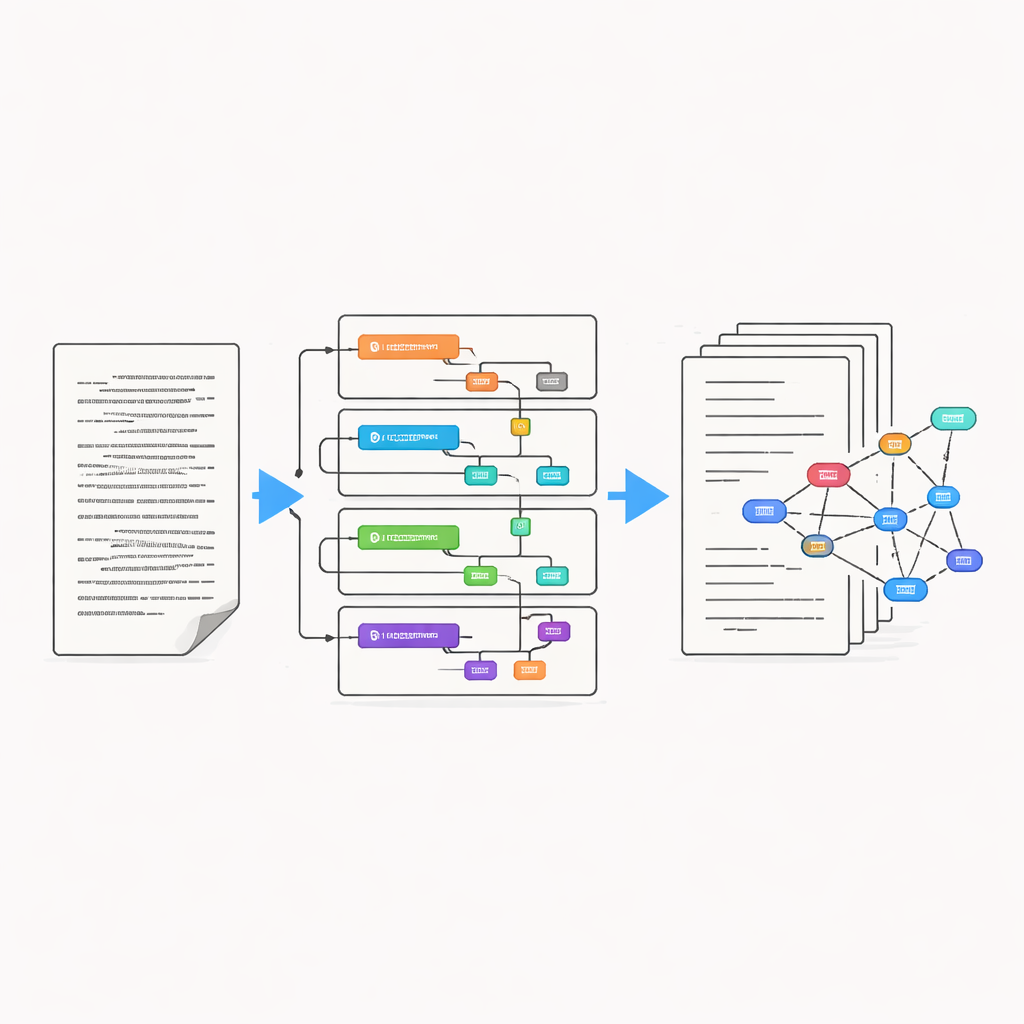
Turning historical pages into reliable digital text is far from straightforward. Earlier digitization efforts introduced many mistakes: letters read as numbers, jumbled word order, and inconsistent spelling cleanups. The researchers therefore re-ran the material through a modern optical character recognition tool and compared several versions, including those from the Library of Congress and Project Gutenberg. They measured how often characters and entire words were misread, then used carefully checked “gold” transcriptions to fine-tune the process. This allowed them to identify which approaches produced the most accurate versions and where further manual correction was still needed.
Adding Layers of Meaning
Once the basic text was in good shape, the team enriched it with many extra layers of information. Using a language-processing pipeline, they marked sentence boundaries, word types, dictionary forms, and grammatical relationships. They also began identifying names of people and places and created detailed metadata, such as when and where an interview was recorded, the gender of the main speaker, and whether a page reflected printed standard English or an attempt to capture spoken vernacular. Special attention was paid to the way interviewers wrote down African American speech of the time, which often appears in nonstandard spellings like “gwine” for “going” and can be difficult for computers to analyze.
Exploring Language and Experience
These technical layers open new windows onto both history and language. With millions of words now organized and annotated, researchers can run large-scale searches for patterns: how people spoke about work, family, punishment, or freedom, and how those patterns changed over time or from place to place. Early experiments using word-embedding models—tools that cluster words by similar meanings—have already revealed subtle distinctions. For instance, in first-person narratives by formerly enslaved people, terms like “man” and “person” tend to refer to people regardless of background, whereas in other contemporary texts “man” is more closely tied to white subjects and “person” to African Americans. Such findings suggest that the corpus can shed light on how language encoded race and status.
A Living Resource for Shared Heritage
The article’s main outcome is not a single historical claim but a durable, openly shared research resource. Version 0.1 of the corpus is already available, complete with documentation, example analyses, and code for reproducing or extending the work. Future releases will add more interviews, richer geographic information, topic and sentiment analyses, and additional tools for exploration. For a lay reader, the key message is that voices long confined to scattered archives are now being carefully gathered, cleaned, and amplified. This digital corpus preserves the words of formerly enslaved people as part of our common cultural heritage and makes it much easier for scholars, students, and the public to learn from what they chose to say about their own lives.
Citation: Elmerot, I., Olsson, LJ. & Rönnbäck, K. Volces of formerly enslaved: A new text corpus of narratives by formerly enslaved persons. Sci Data 13, 682 (2026). https://doi.org/10.1038/s41597-026-07340-x
Keywords: slave narratives, digital humanities, historical linguistics, African American history, text corpus