Clear Sky Science · es
Un conjunto de datos bimodal para la investigación de la diabetes
Por qué esto importa para las personas que viven con diabetes o se preocupan por ella
La diabetes afecta a cientos de millones de personas en todo el mundo, pero los investigadores siguen teniendo dificultades para predecir quién desarrollará complicaciones graves, como insuficiencia renal, ceguera o enfermedad cardíaca. Un obstáculo importante es la falta de datos reales, extensos y detallados que capten cómo la diabetes interactúa con el resto del cuerpo a lo largo del tiempo. Este artículo presenta un nuevo y rico conjunto de datos de casi seis mil pacientes que podría ayudar a los científicos a construir mejores herramientas de predicción y a profundizar en la comprensión de cómo se desarrolla la diabetes en la práctica clínica cotidiana.
Una gran muestra de pacientes reales, no solo pequeñas muestras de investigación
Los autores recopilaron información de 5.922 personas tratadas en un importante centro de diabetes de Shanghái durante un período de dos meses. A diferencia de muchos estudios anteriores que siguieron solo a unas decenas o unos pocos cientos de voluntarios, este conjunto de datos refleja el tipo de pacientes que los médicos ven en la práctica: adultos de 18 a 91 años, con una amplia variedad de tamaños corporales, niveles de glucosa, duraciones de la enfermedad y complicaciones. Se eliminaron todos los identificadores personales para proteger la privacidad, y los nombres de las variables se estandarizaron para que investigadores de todo el mundo puedan comprender y reutilizar fácilmente la información.
Dos tipos de datos que cuentan una historia más completa
Este recurso se describe como “bimodal”, lo que significa que combina mediciones numéricas con información estructurada, similar a texto, sobre los antecedentes médicos y el estilo de vida de las personas. En total hay 190 atributos diferentes por paciente. Estos incluyen medidas corporales como el índice de masa corporal (IMC); múltiples lecturas de glucosa; paneles detallados de pruebas hepáticas, renales y sanguíneas; y marcadores de producción de insulina. Junto a estos números hay registros sobre hábitos de fumar y beber, tipo de trabajo, conocimiento de los síntomas de la diabetes, antecedentes familiares y la presencia de complicaciones como enfermedad cardíaca, accidente cerebrovascular, daño nervioso, problemas de visión o pie diabético. En conjunto, estas capas ofrecen una imagen más completa de cómo la diabetes interactúa con el cuerpo y la vida diaria.
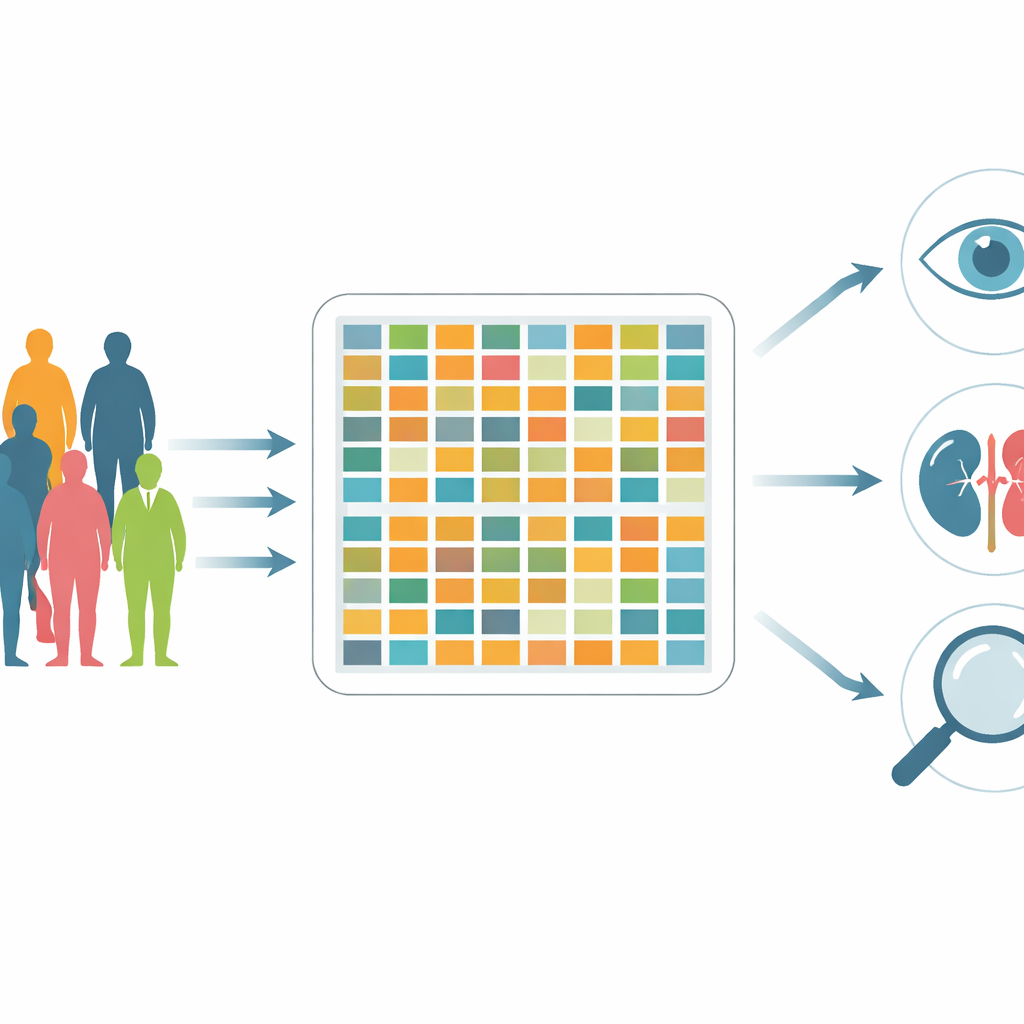
Supliendo lagunas dejadas por conjuntos de datos anteriores sobre diabetes
El artículo sitúa este nuevo conjunto de datos en contexto comparándolo con varios recursos públicos bien conocidos. Algunas colecciones existentes siguen a pacientes con tecnología avanzada y registran la glucosa las 24 horas, pero a menudo carecen de información sobre complicaciones. Otras se centran en detalles moleculares de un número muy reducido de personas, lo que dificulta la generalización a clínicas reales. Algunas ofrecen medidas continuas de glucosa pero omiten factores de contexto clave, como la duración de la diabetes o la existencia de enfermedad renal. En cambio, el nuevo conjunto de datos reúne múltiples sistemas a la vez: control glucémico, función hepática y renal, analíticas sanguíneas, estilo de vida e historial de complicaciones, lo que lo hace especialmente adecuado para construir modelos de aprendizaje automático destinados a predecir riesgos futuros o clasificar diferentes patrones de la enfermedad.
Verificar que los números tienen sentido médico
Para mostrar que los datos son fiables, los investigadores realizaron una serie de comprobaciones que reflejan lo que los clínicos esperan ver. Examinaron cómo el peso corporal se relaciona con la glucosa, encontrando que un IMC más alto suele ir de la mano con niveles de glucosa en ayunas y posprandiales más elevados, con la mayoría de valores dentro de rangos clínicamente plausibles. Observaron cómo se distribuyen las mediciones de glucosa en el conjunto de pacientes y detectaron patrones típicos de la diabetes tipo 2: muchos individuos agrupados en categorías de peso más alto y una asimetría hacia glucemias elevadas a las dos horas posprandiales. También comprobaron que las lecturas en ayunas y posprandiales concuerdan entre sí en la misma persona, y exploraron cómo las etapas de función renal se alinean con los niveles medios de glucosa. Por último, confirmaron que las medidas de insulina en sangre están fuertemente correlacionadas con un índice estándar de resistencia a la insulina, tal como cabría esperar por la fisiología básica.
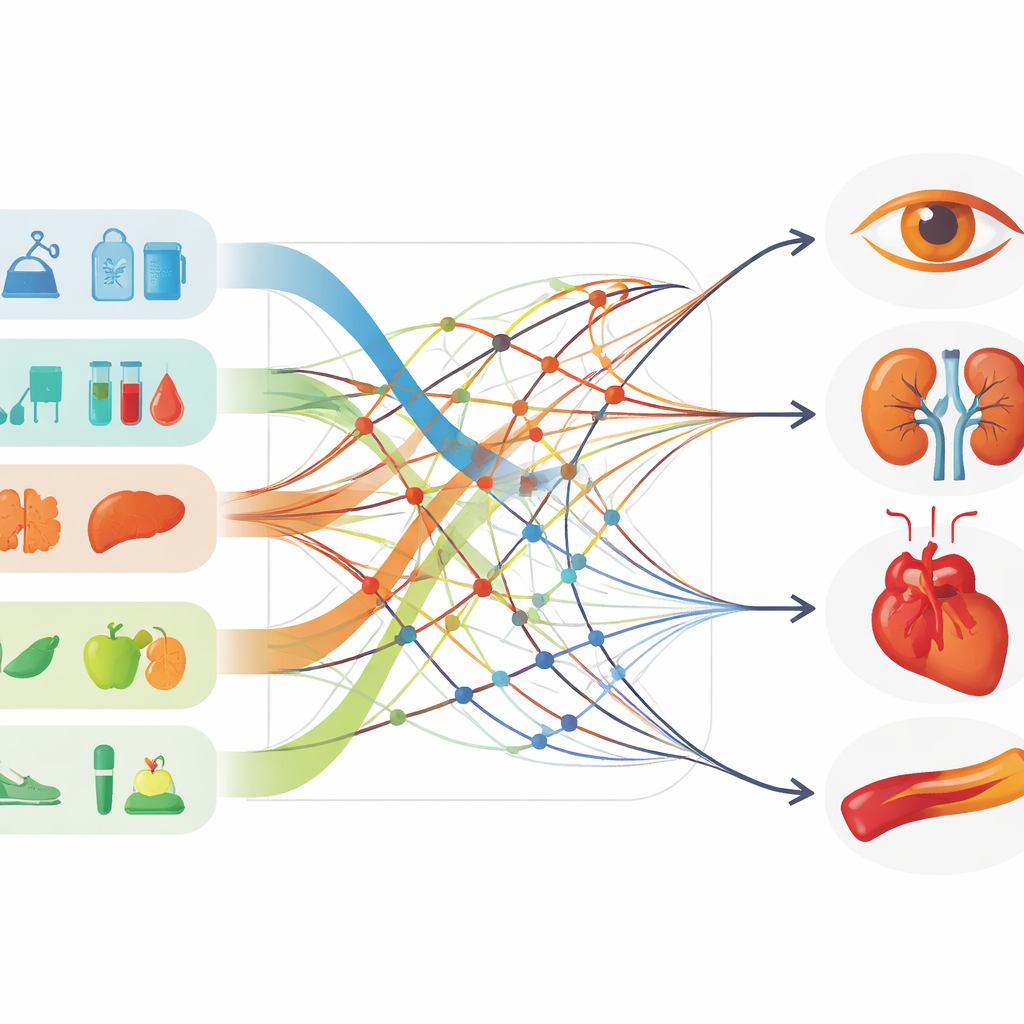
Qué significa esto para la atención y la investigación futuras
En términos sencillos, este artículo no prueba un nuevo fármaco o dieta; en cambio, aporta la materia prima necesaria para construir y evaluar herramientas más inteligentes para el cuidado de la diabetes. Debido a que el conjunto de datos es grande, detallado y de acceso público, los científicos pueden usarlo para entrenar algoritmos que identifiquen a pacientes de alto riesgo antes, entender qué combinaciones de factores de riesgo son más relevantes o comparar subgrupos de personas con diferentes patrones de complicaciones. Si se usa con criterio y en combinación con otras fuentes, este tipo de recurso de datos puede ayudar a desplazar la atención de la diabetes desde soluciones uniformes hacia predicciones más personalizadas y, en última instancia, a mejorar la prevención de las consecuencias más temidas de la enfermedad.
Cita: Li, J., Zheng, H., Zhou, Y. et al. A bimodal dataset for diabetes research. Sci Data 13, 652 (2026). https://doi.org/10.1038/s41597-026-06923-y
Palabras clave: conjunto de datos de diabetes, datos clínicos, aprendizaje automático, complicaciones diabéticas, predicción de riesgo