Clear Sky Science · en
A bimodal dataset for diabetes research
Why this matters for people living with or worried about diabetes
Diabetes affects hundreds of millions of people worldwide, yet researchers still struggle to predict who will develop serious complications such as kidney failure, blindness, or heart disease. One major obstacle is the lack of large, detailed, real-world data that capture how diabetes interacts with the rest of the body over time. This paper introduces a rich new dataset of nearly six thousand patients that could help scientists build better prediction tools and deepen our understanding of how diabetes unfolds in everyday clinical settings.
A big pool of real patients, not just small research samples
The authors collected information from 5,922 people treated at a major diabetes center in Shanghai over a two‑month period. Unlike many earlier studies that followed only a few dozen or a few hundred volunteers, this dataset reflects the kind of patients doctors actually see: adults aged 18 to 91, with a wide range of body sizes, blood sugar levels, disease durations, and complications. All personal identifiers were removed to protect privacy, and variable names were standardized so that researchers around the world can easily understand and reuse the information.
Two kinds of data that tell a fuller story
This resource is described as “bimodal,” meaning it combines numerical measurements with structured, text-like information about people’s medical histories and lifestyles. In total, there are 190 different attributes for each patient. These include body measurements such as body mass index (BMI); multiple blood sugar readings; detailed panels of liver, kidney, and blood tests; and markers of insulin production. Alongside these numbers are records about smoking and drinking habits, work type, awareness of diabetes symptoms, family history, and the presence of complications such as heart disease, stroke, nerve damage, vision problems, or diabetic foot. Together, these layers provide a more complete picture of how diabetes interacts with the whole body and daily life.
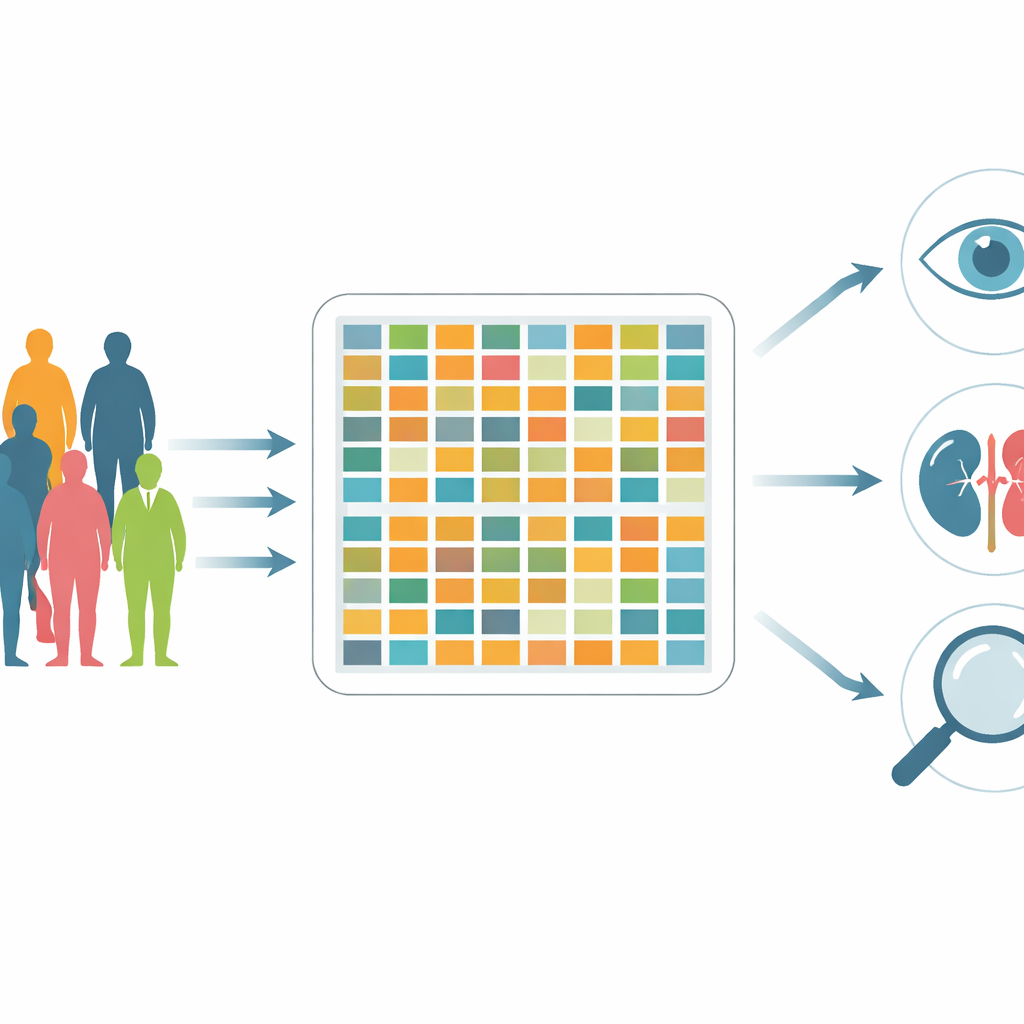
Filling gaps left by earlier diabetes datasets
The paper places this new dataset in context by comparing it with several well-known public resources. Some existing collections follow patients with advanced diabetes technology and track blood sugar around the clock, but they often lack information on complications. Others focus on molecular details from a tiny number of people, making it hard to generalize to real clinics. Still others offer continuous glucose measurements but omit key background factors, such as how long someone has had diabetes or whether they have kidney disease. By contrast, the new dataset brings together many systems at once—blood sugar control, liver and kidney function, blood counts, lifestyle, and complication history—making it especially suitable for building machine‑learning models that aim to predict future risks or classify different patterns of disease.
Checking that the numbers make medical sense
To show that the data are trustworthy, the researchers performed a series of reality checks that mirror what clinicians expect to see. They examined how body weight relates to blood sugar, finding that higher BMI tends to go hand in hand with higher fasting and after‑meal glucose levels, with most values falling within plausible clinical ranges. They looked at how blood sugar measurements are distributed across the patient group and observed patterns typical of type 2 diabetes: many individuals clustered in higher weight categories and a skew toward elevated two‑hour post‑meal glucose. They also checked that fasting and post‑meal sugar readings agree with each other within the same person, and explored how kidney function stages line up with average glucose levels. Finally, they confirmed that measures of insulin in the blood are strongly tied to a standard index of insulin resistance, as expected from basic physiology.
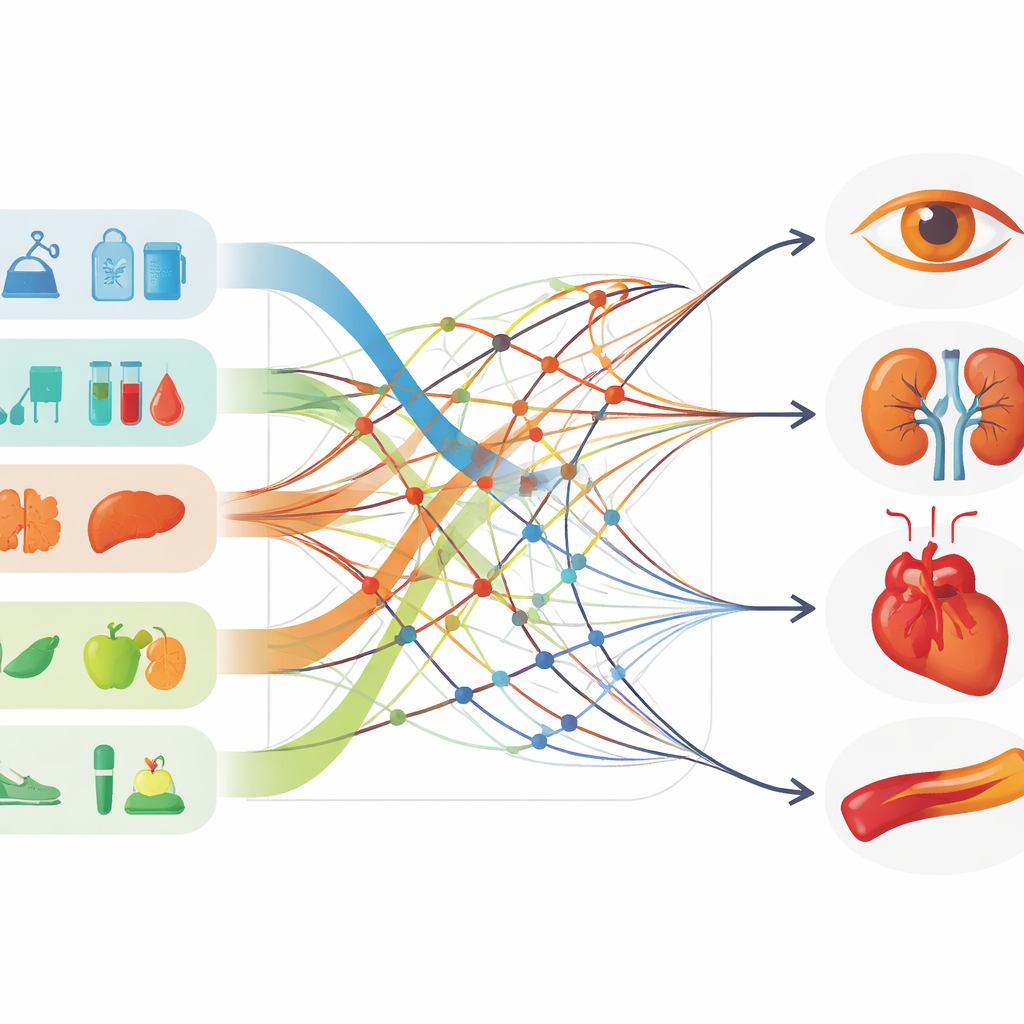
What this means for future care and research
In plain terms, this paper does not test a new drug or diet; instead, it delivers the raw material needed to build and evaluate smarter tools for diabetes care. Because the dataset is large, detailed, and publicly available, scientists can use it to train algorithms that spot high‑risk patients earlier, understand which combinations of risk factors matter most, or compare subgroups of people with different complication patterns. If used wisely and in combination with other sources, this kind of data resource can help move diabetes care from one‑size‑fits‑all toward more personalized predictions and, ultimately, better prevention of the most feared consequences of the disease.
Citation: Li, J., Zheng, H., Zhou, Y. et al. A bimodal dataset for diabetes research. Sci Data 13, 652 (2026). https://doi.org/10.1038/s41597-026-06923-y
Keywords: diabetes dataset, clinical data, machine learning, diabetic complications, risk prediction