Clear Sky Science · es
Resiliencia superior frente al envenenamiento y facilidad para el olvido en el aprendizaje automático cuántico
Por qué limpiar datos malos importa para la IA
Los sistemas modernos de inteligencia artificial aprenden a partir de colecciones masivas de ejemplos, pero esos ejemplos a menudo son imperfectos. Algunos están mal etiquetados por accidente, otros pueden ser manipulados a propósito. Una vez que esos datos “envenenados” se introducen en el entrenamiento, pueden deformar silenciosamente el comportamiento de un modelo de forma perjudicial. Este artículo plantea una pregunta sorprendente: si construimos sistemas de aprendizaje con ordenadores cuánticos en lugar de clásicos, ¿reaccionan de forma distinta ante datos corruptos —y pueden olvidarlos más fácilmente cuando hace falta?
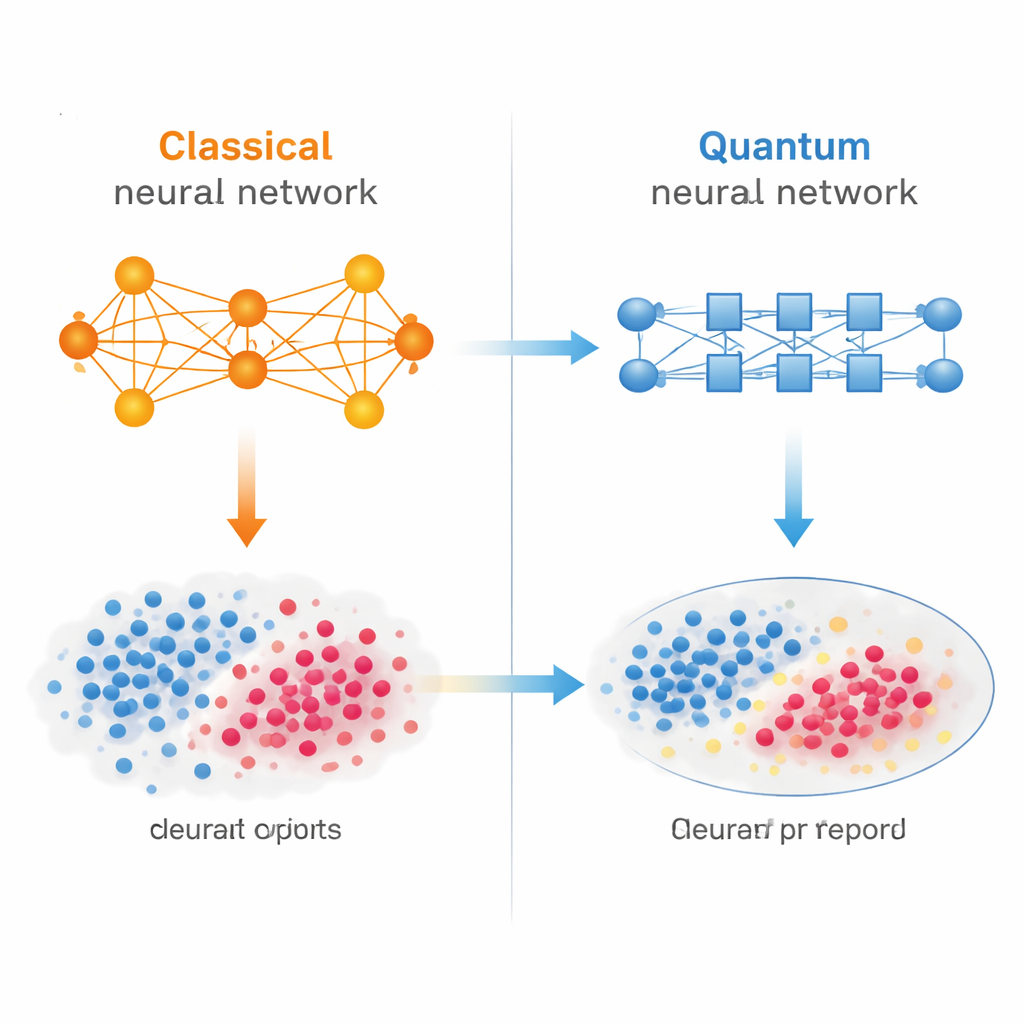
Dos maneras de aprender a partir de información desordenada
Los autores comparan dos tipos de redes neuronales entrenadas en las mismas tareas. Una es una red clásica familiar, una pila de conexiones ponderadas que se ejecuta en un ordenador ordinario. La otra es una red neuronal cuántica que utiliza qubits y puertas cuánticas para procesar información en superposición. A ambas se les pide resolver dos tipos de problemas de clasificación: distinguir dígitos manuscritos en el conjunto de datos MNIST y diferenciar entre dos fases de la materia en un modelo de física cuántica. En cada caso, los investigadores contaminan deliberadamente parte de los datos de entrenamiento, ya sea invirtiendo las etiquetas en algunos ejemplos o sustituyendo las características de entrada por ruido aleatorio, y luego observan cómo afronta cada modelo la situación.
Cuando las etiquetas mienten, los modelos cuánticos mantienen su posición
La diferencia más marcada aparece cuando se invierten las etiquetas. La red clásica intenta satisfacer cada ejemplo de entrenamiento, incluidos los contradictorios, y gradualmente retuerce su frontera de decisión interna para ajustarlos. Su rendimiento en datos nuevos y no vistos se deteriora de forma progresiva a medida que se corrompen más etiquetas. En contraste, la red cuántica muestra una meseta robusta: en un amplio rango de niveles de ruido, sigue clasificando bien los datos limpios de validación, ignorando de hecho los outliers mal etiquetados. Sólo cuando las etiquetas corruptas se vuelven dominantes —alrededor del punto en que la mitad de las etiquetas están erróneas— su rendimiento colapsa de forma abrupta, similar a una transición de fase. Este comportamiento sugiere que el aprendiz cuántico favorece el patrón más simple y coherente en los datos y trata las contradicciones dispersas como perturbaciones irrelevantes hasta que ahogan la señal verdadera.
Olvidar un mal entrenamiento es más fácil para los modelos cuánticos
Más allá de resistir la corrupción, los autores estudian el “desaprendizaje de máquinas”: con qué eficiencia se puede forzar a un modelo entrenado a olvidar la influencia de datos dañinos sin empezar desde cero. Exploran varias estrategias, como volver a entrenar sólo con la porción limpia de los datos, ajustar finamente a partir del modelo envenenado, empujar explícitamente las predicciones del modelo lejos de lo aprendido sobre el subconjunto malo y usar pasos de gradiente que deshagan el efecto de esos ejemplos. Para la red clásica, todos los métodos aproximados eficientes se quedan por detrás del reentrenamiento completo, lo que indica que su representación interna se ha endurecido alrededor de las muestras envenenadas. La red cuántica se comporta de forma distinta. Partiendo incluso de un estado envenenado, puede ser dirigida mediante métodos aproximados de desaprendizaje para igualar o superar el rendimiento de un costoso reentrenamiento dentro del mismo intervalo temporal. Esto muestra que su representación aprendida es más plástica: lo bastante estructurada para ser útil, pero lo bastante flexible para ser corregida.

El paisaje oculto tras la resiliencia y la plasticidad
Para explicar estos comportamientos contrastantes, los autores examinan el “paisaje de pérdida”, una superficie de alta dimensión que mide qué tan bien el modelo ajusta los datos para cada configuración de sus parámetros. Se sabe que una buena generalización está vinculada a valles amplios y planos en este paisaje, mientras que el sobreajuste frágil suele corresponder a mínimos agudos y estrechos. Al analizar cómo cambia la curvatura de este paisaje cuando los datos son envenenados, encuentran que las redes clásicas experimentan un dramático rugosamiento: una región que antes era plana alrededor de la solución se vuelve extremadamente aguda a medida que el modelo memoriza puntos mal etiquetados. Salir de ese valle empinado durante el desaprendizaje resulta difícil, lo que explica la terquedad de las memorias clásicas. Las redes cuánticas, en cambio, mantienen casi la misma curvatura suave incluso después del envenenamiento. Sus paisajes son estructuralmente estables, acotados por las matemáticas de las operaciones cuánticas, lo que previene la formación de mínimos extremadamente agudos y orienta de forma natural el aprendizaje hacia soluciones suaves y generalizables.
Qué significa esto para una IA confiable en el futuro
Para un lector no especialista, la conclusión es que el aprendizaje automático cuántico no se trata solo de velocidad o hardware exótico. En estos experimentos, los modelos cuánticos actúan más como editores cuidadosos que como escribas obsesivos: extraen la trama principal en datos desordenados, resisten ser influenciados por unos pocos ejemplos malos y pueden ser inducidos a olvidar influencias nocivas sin reconstruirse desde cero. Esta combinación de resiliencia al envenenamiento y disposición a desaprender sugiere un nuevo tipo de ventaja cuántica —una basada en fiabilidad y seguridad más que en pura potencia de cálculo— y apunta a que futuros sistemas de IA potenciados por lo cuántico podrían ser mejores socios en un paisaje informativo ruidoso y en constante cambio.
Cita: Chen, YQ., Zhang, SX. Superior resilience to poisoning and amenability to unlearning in quantum machine learning. Nat Commun 17, 3716 (2026). https://doi.org/10.1038/s41467-026-70420-4
Palabras clave: aprendizaje automático cuántico, envenenamiento de datos, desaprendizaje de máquinas, IA robusta, paisaje de pérdida