Clear Sky Science · en
Diagnostic accuracy, fairness and clinical implementation of AI for breast cancer screening: results of multicenter retrospective and prospective technical feasibility studies
Smarter Screening for Everyday Women
Breast cancer screening saves lives, but it also strains health systems and can miss cancers or trigger stressful false alarms. This study asks a simple question with big implications: can an artificial intelligence (AI) program safely help read mammograms in the UK’s national screening program, catching more dangerous cancers while easing pressure on busy specialists—and doing so fairly for women from different backgrounds?
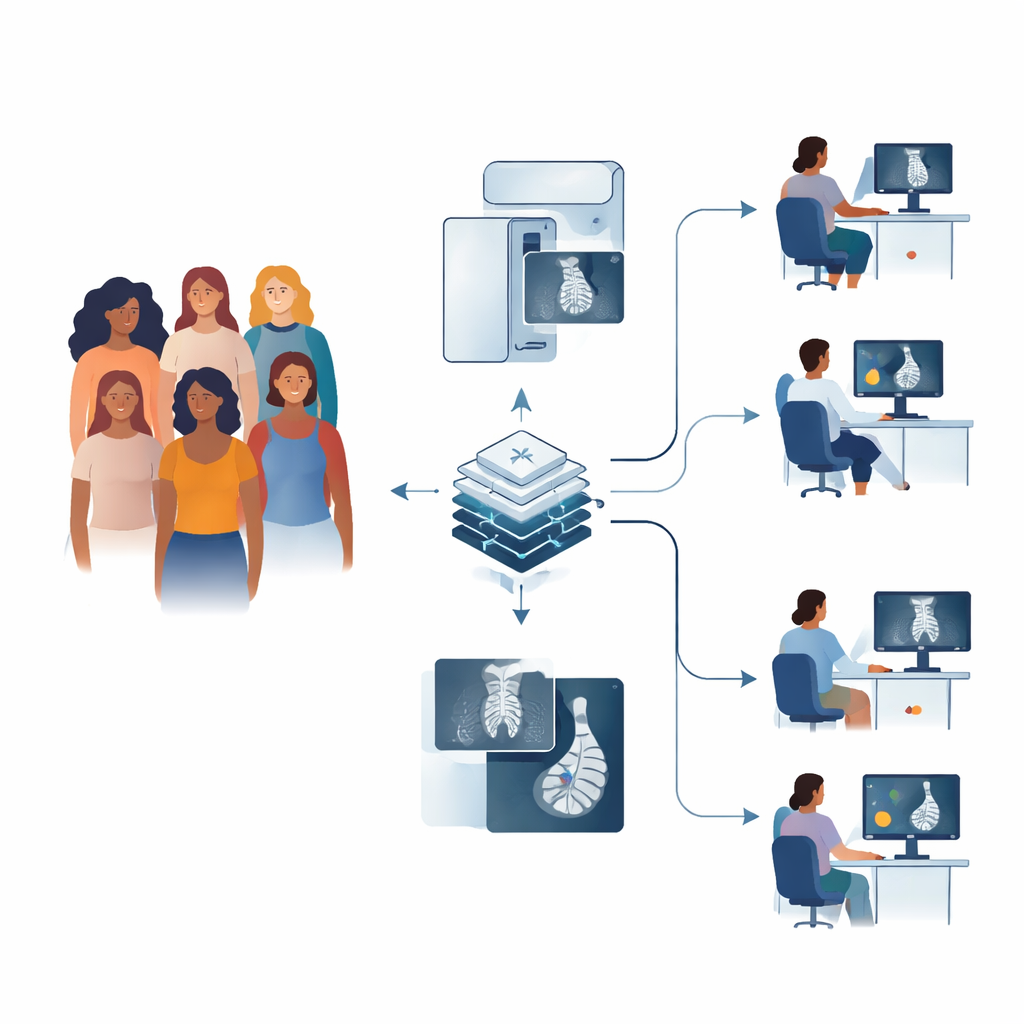
How Screening Works Today
In many countries, including the United Kingdom, women aged 50 to 70 are invited for regular mammograms. In the UK, each scan is usually read independently by two human experts; if they disagree, a panel reviews the case. This double-reading system is designed to be safe, but it is time‑consuming and depends on having enough trained readers—something many health systems struggle with. Earlier computer tools offered limited help and sometimes added noise rather than clarity, so health authorities have demanded strong new evidence before trusting modern AI inside national programs.
Putting AI to the Test in Real Clinics
The researchers evaluated Google’s updated mammography AI in two major phases across the UK’s National Health Service. First, they ran the system on nearly 116,000 past screening exams from five different regions, following women for more than three years to see which cancers actually emerged. They then compared the AI’s performance with that of the first human reader, the second reader and the final panel decision. In a second phase, they quietly installed the AI in 12 screening sites and let it process over 9,000 new exams in real time—without influencing care—to study how it behaved in day‑to‑day practice and how its settings might need tuning.
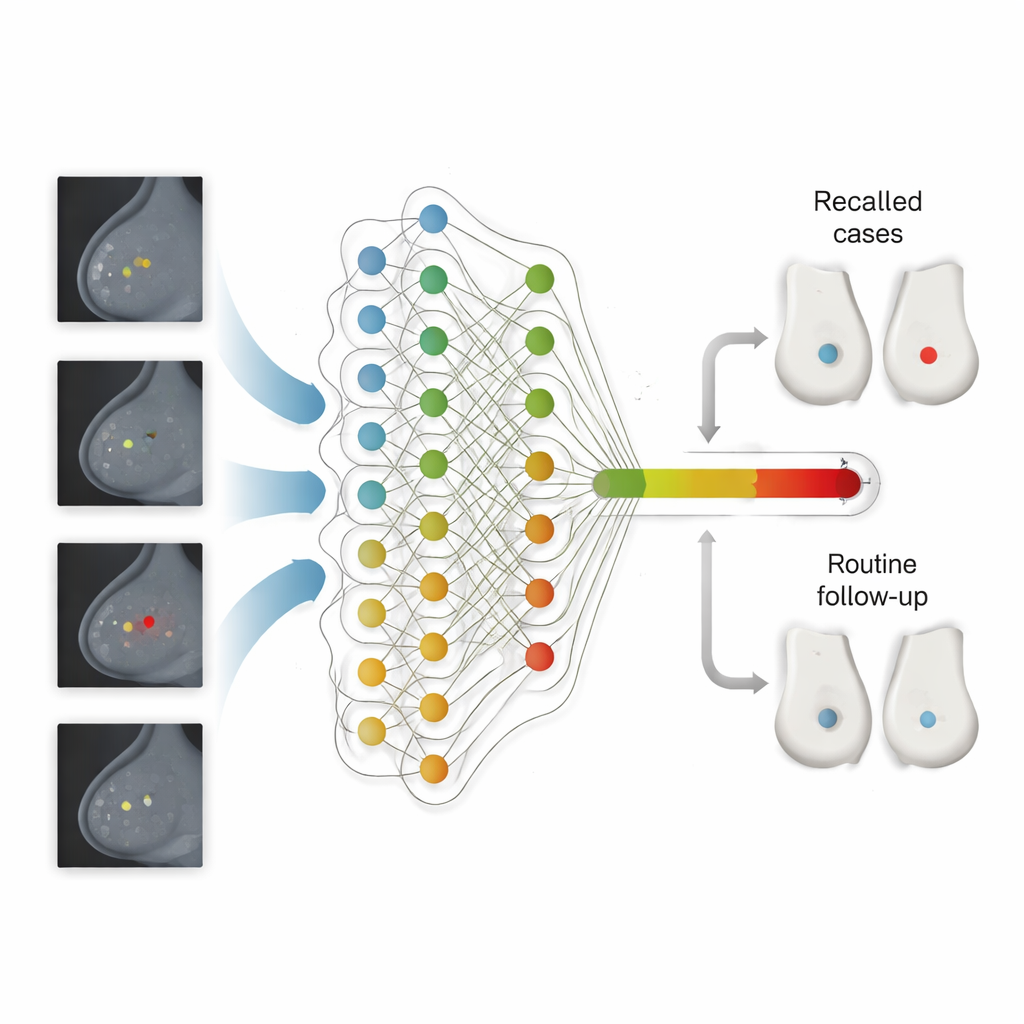
What the AI Saw—and What It Caught
Across the large retrospective dataset, the AI was more sensitive than the first human reader: it picked up more cancers overall while keeping its rate of false alarms within a pre‑set safety margin. If used as one reader in the double‑reading workflow, the system would have raised the cancer detection rate from about 7.5 to 9.3 cancers per 1,000 women, and it correctly flagged one in four cancers that were originally missed and only discovered later, either between screenings or at the next routine visit. The gains were especially strong in women coming for their first screen—usually the hardest group to interpret because there are no prior images. In these first‑time visits, the AI both called back fewer women and still detected slightly more cancers, particularly invasive tumors that pose the greatest threat.
Fairness, Workload, and Real-World Hurdles
The team looked carefully at whether the AI treated different groups of women equitably. Across age, breast density, socioeconomic status and the limited ethnicity data available, they saw no consistent signs of harmful bias: sensitivity and specificity stayed within tight margins compared with human readers, although some very small subgroups had wide uncertainty. They also modeled how using AI as the second reader would reshape work. The number of human screening reads before panel review could drop by almost half, cutting reader time by about one‑third, even though more cases would be escalated to the panel. In the live feasibility phase, the AI delivered results within minutes—far faster than routine human reading—but the team discovered a shift in how recent images looked compared with older training data. An initial operating threshold proved too sensitive, causing higher recall rates, and had to be recalibrated downward using fresh local data.
Building an AI-Ready Screening System
Beyond accuracy, the study exposed practical barriers to safe deployment. Many screening centers still rely on paper forms and legacy software that cannot automatically store AI results or explain why a scan was recalled—features regulators and clinicians need. The authors argue that fully digital, standardized workflows and better collection of demographic data will be crucial for monitoring performance and fairness over time. They also stress that AI thresholds cannot be “set and forget”: image equipment, reader behavior and population mix all change, so the system must be continuously checked and adjusted, with clear national rules and technical support.
What This Means for Patients
The findings suggest that a carefully deployed AI system could help national breast screening programs spot more serious cancers earlier, especially in women attending for their first mammogram, while easing the workload on overstretched specialists. Yet the authors emphasize that success depends on more than an accurate algorithm. Health services will need ongoing calibration, rigorous monitoring for drift and bias, upgraded IT infrastructure and thoughtful integration into existing human workflows. With these safeguards in place, AI could become a trusted extra reader that improves both the efficiency and the equity of breast cancer screening rather than a black box that adds new risks.
Citation: Kelly, C.J., Wilson, M., Warren, L.M. et al. Diagnostic accuracy, fairness and clinical implementation of AI for breast cancer screening: results of multicenter retrospective and prospective technical feasibility studies. Nat Cancer 7, 494–506 (2026). https://doi.org/10.1038/s43018-026-01127-0
Keywords: breast cancer screening, medical artificial intelligence, mammography, healthcare fairness, clinical implementation