Clear Sky Science · en
Frequency-aware vision transformers for high-fidelity super-resolution of Earth system models
Why Sharper Climate Maps Matter
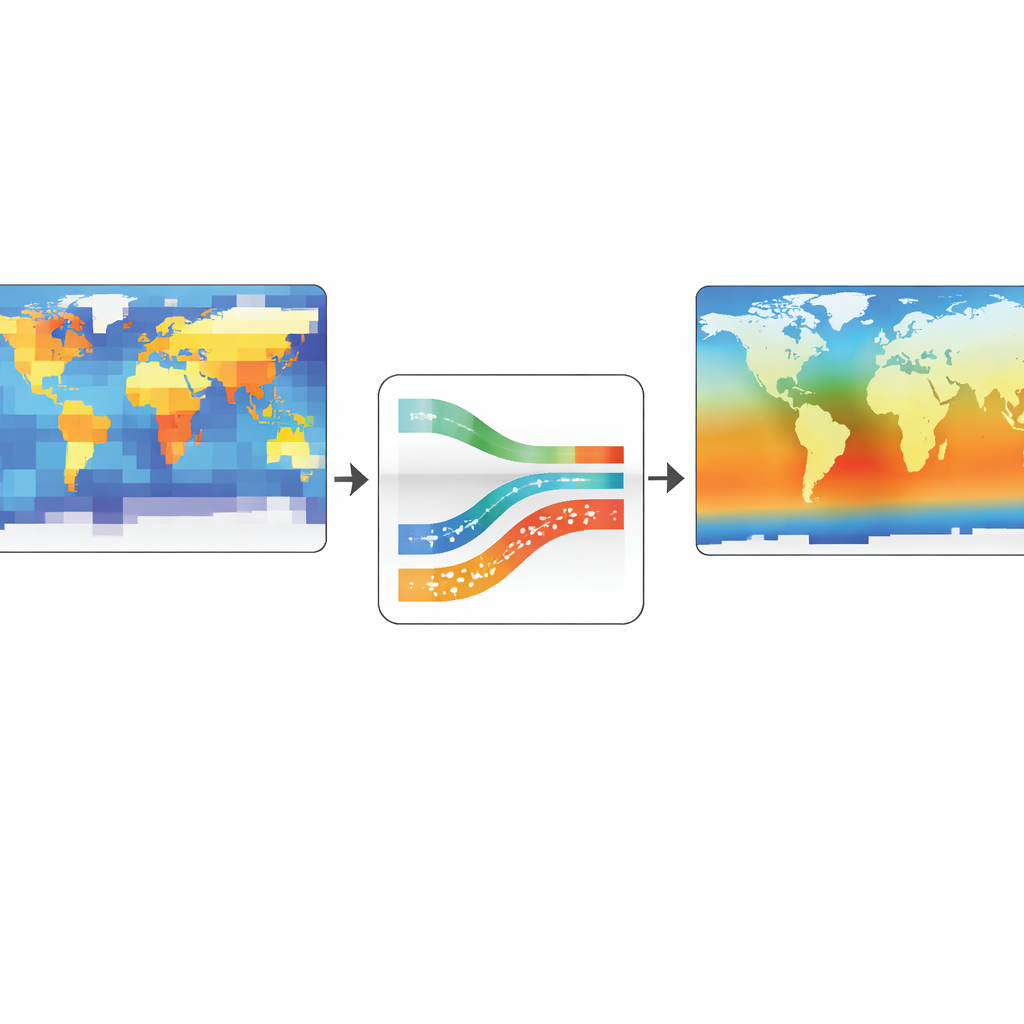
Weather and climate decisions—like planning reservoirs, flood defenses, or heat action plans—depend on seeing local details: sharp coastlines, mountain shadows, storm tracks, and hot spots. Yet most global climate simulations run on relatively coarse grids, blurring these fine patterns. This paper presents new artificial intelligence tools that can take blurry climate model output and “sharpen” it into detailed maps, doing so in a way that preserves the tiny but crucial features that standard approaches tend to smooth away.
From Blurry Global Models to Clear Local Views
Earth System Models simulate the coupled behavior of the atmosphere, oceans, land, and ice, but running them at very high spatial resolution is so computationally expensive that it is rarely feasible. As a result, many simulations are produced on grids too coarse to resolve sharp temperature gradients, intense heat fluxes, or small-scale structures that matter for local risk assessments. A growing field called super-resolution aims to bridge this gap by using machine learning to infer what a high-resolution field would look like given a low-resolution input. The authors focus on applying super-resolution to three key variables—surface temperature and incoming and outgoing radiation—using data from the high-resolution E3SM climate model, and treating the task as a statistical enhancement of existing simulations rather than a replacement for physical modeling.
The Hidden Bias Against Fine Details
Most modern image-enhancement tools, including convolutional neural networks and newer vision transformers, have a built-in bias toward learning smooth, slowly varying patterns more easily than sharp edges and fine textures. In technical terms, they favor low-frequency content and struggle with high-frequency information, which is exactly where many important climate features live: steep temperature contrasts along fronts, sharp boundaries at coastlines and mountains, and localized extremes. Earlier work with special neural networks that use sinusoidal (wave-like) activations showed that this bias can be reduced, but off-the-shelf versions were not tailored to the multiscale, physical structure of climate data. The paper identifies this “spectral bias” as a central obstacle to using generic vision models for climate super-resolution.
A New Way to Teach AI About Climate Scales
To address this, the authors introduce two related models, ViSIR and ViFOR, that embed frequency awareness directly into a vision transformer pipeline. ViSIR (Vision Transformer–Tuned Sinusoidal Implicit Representation) uses a transformer to capture global context from a coarse climate map, then passes this information to a decoder built from sinusoidal units that can represent high-frequency patterns more faithfully. The decoder is “implicit,” meaning it can generate values at arbitrary coordinates, allowing flexible output resolutions. ViFOR (Vision Transformer Fourier Representation Network) takes the idea further by explicitly splitting information into low-frequency and high-frequency streams using Fourier-based filters, then recombining them. This lets the model learn smooth background patterns and sharp details separately, rather than forcing a single setting to work for all scales and variables.
How the New Models Perform in Practice
The researchers train and test their methods on decades of monthly E3SM simulations that have both coarse and fine versions available. They compare ViSIR and ViFOR against classic convolutional networks, a generative model, a basic vision transformer, a leading transformer restoration model, and a sinusoidal network without transformers. Across surface temperature and both shortwave and longwave radiation, the new models deliver smaller errors and higher similarity to the fine-resolution reference, with ViFOR consistently on top. Gains of a few decibels in signal quality correspond to visibly crisper gradients and more faithful small-scale structures. Spectral analyses show that ViFOR not only restores more high-frequency energy, but does so in a controlled way that avoids spurious noise and maintains the correct balance across scales. The benefits are especially strong when the models are trained on full global maps rather than on cropped regions, underscoring the importance of preserving large-scale climate context.
What This Means for Climate Decisions
In everyday terms, ViSIR and especially ViFOR are specialized microscopes for climate maps: they take a blurred global picture and statistically fill in the missing fine features in a way that respects how real climate fields vary across scales. They do not invent new physics or replace high-resolution simulations and regional models. Instead, they act as smart post-processing tools that make existing coarse simulations more useful for geosensing, hazard mapping, and planning. By directly attacking the tendency of standard AI models to wash out sharp features, these frequency-aware transformers offer climate scientists and practitioners sharper, more reliable spatial detail from the simulations they already run, helping bridge the gap between global models and local decisions.
Citation: Zeraatkar, E., Faroughi, S.A. & Tešić, J. Frequency-aware vision transformers for high-fidelity super-resolution of Earth system models. Sci Rep 16, 10363 (2026). https://doi.org/10.1038/s41598-026-41020-5
Keywords: climate super-resolution, earth system models, vision transformers, frequency-aware AI, downscaling