Clear Sky Science · en
Rolling bearing fault diagnosis method based on fusion of STFT-statistical features and AL-SOA optimized bagging tree
Why keeping machine bearings healthy matters
From wind turbines to trains and aircraft engines, countless machines rely on rolling bearings to keep rotating parts running smoothly. When these bearings start to fail, the consequences can range from costly downtime to dangerous accidents. This paper introduces a smarter, lighter‑weight way to “listen” to bearings through their vibrations and spot early warning signs of damage, even when machines are noisy, operating conditions change, and computing resources are limited.
Listening to vibrations in two complementary ways
The authors focus on how vibration signals from a bearing change when its inner race, outer race, or rolling elements begin to wear or crack. Instead of relying on a single view of these signals, they combine two simple but powerful descriptions. One is a short‑time frequency view that reveals when energy gathers at particular tones over time, which is sensitive to the repeated impacts caused by defects. The other is a compact set of six time‑based statistics—such as average level, spread, and “spikiness”—that capture how erratic or energetic the motion is. Together, these views provide a richer picture of what is happening inside the bearing than either could alone. 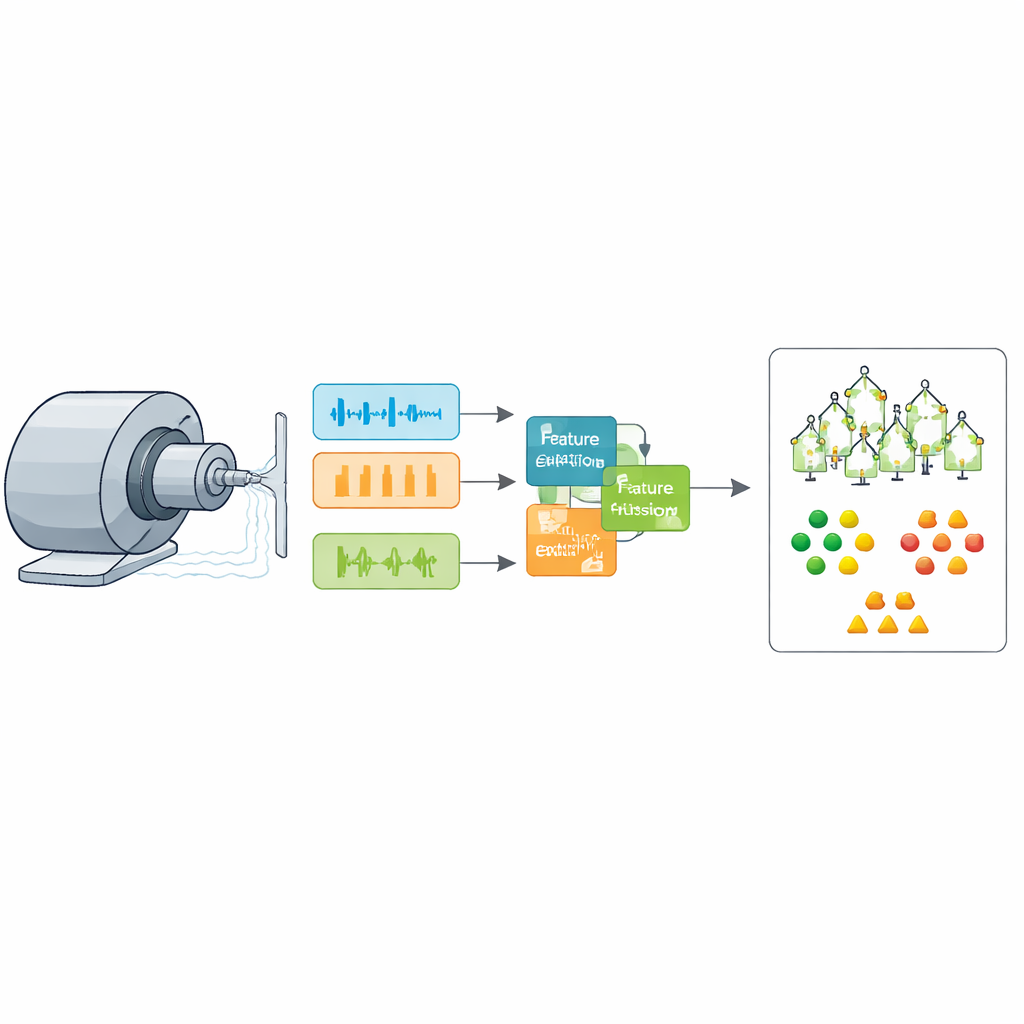
Cleaning, focusing, and fusing the signal information
Real machines rarely operate in laboratory silence, so the method begins with careful signal cleaning. The raw vibration is centered, filtered to keep only a band where bearing faults are most revealing, and denoised with wavelets that preserve short, sharp events. Overlapping time windows then slice the continuous signal into short, repeatable snippets that each represent about a fifth of a second of motion. For every snippet, the frequency‑based pattern and the six time‑based measures are extracted and normalized so that differences reflect bearing behavior rather than simple changes in overall energy.
Letting the data decide what matters most
Instead of hard‑coding how much to trust each type of feature, the authors introduce a small “attention” unit that learns to emphasize whichever parts of the frequency and time information are most helpful for telling different fault types apart. Conceptually, this unit behaves like a spotlight that brightens certain frequency bands and certain statistics when they align with known defect signatures, and dims those that carry mostly noise. After this adaptive fusion, a standard mathematical tool called principal component analysis compresses the 262‑value description of each snippet into a smaller set that still preserves almost all of the useful variation. This step trims redundancy, speeds up learning, and helps avoid overfitting without noticeably harming accuracy.
Building and tuning an efficient decision forest
For the final decision, the authors avoid heavyweight deep‑learning networks and instead use an ensemble of decision trees, a method known as bagging. Each tree learns simple rules that split the compressed feature space into regions associated with specific fault types or healthy operation, and the ensemble votes on the final label. The twist is how the structure of this forest is chosen. Rather than guessing the number and depth of trees, the team uses a population‑based search inspired by the flocking and hunting patterns of seabirds. This adaptive swarm explores combinations of model settings while juggling three goals at once: classify faults accurately, keep the forest compact, and reduce training time. Solutions that balance these goals form a “frontier” from which a practical operating point can be selected. 
Proving robustness across different test rigs
The complete pipeline—cleaning, dual‑view feature extraction, attention‑based fusion, compression, and optimized tree ensemble—was tested on three different bearing test benches: two well‑known public datasets and a custom experimental setup. Across these varied conditions, the method consistently identified bearing faults with around 97–99% accuracy. Careful experiments showed that each major ingredient mattered: removing the attention module, the multi‑objective optimizer, or the compression step all made performance slightly worse, while using only one type of feature caused a notable drop in reliability, especially under noise and changing loads.
What this means for real‑world machinery
To a non‑specialist, the key message is that the authors have built a diagnostic approach that combines simple, understandable building blocks—basic signal cleaning, two intuitive views of vibration, and transparent decision trees—but uses modern ideas like attention and swarm‑style search to tune how they work together. The result is a monitoring scheme that is accurate, relatively easy to interpret, and light enough to run close to the machines it protects. This makes it a promising candidate for keeping industrial bearings under constant watch, catching early signs of trouble before they become failures, even when conditions are noisy, variable, and computing power is at a premium.
Citation: Bai, H., Tong, W., Duan, C. et al. Rolling bearing fault diagnosis method based on fusion of STFT-statistical features and AL-SOA optimized bagging tree. Sci Rep 16, 10314 (2026). https://doi.org/10.1038/s41598-026-37914-z
Keywords: rolling bearing fault diagnosis, vibration signal analysis, attention-based feature fusion, ensemble learning, swarm optimization