Clear Sky Science · de
Fehlerdiagnose bei Wälzlagern basierend auf der Fusion von STFT‑statistischen Merkmalen und AL‑SOA‑optimiertem Bagging‑Tree
Warum die Gesundheit von Maschinenlagern wichtig ist
Von Windturbinen über Züge bis zu Flugzeugtriebwerken: unzählige Maschinen sind auf Wälzlager angewiesen, damit rotierende Bauteile reibungslos laufen. Beginnt ein Lager auszufallen, reichen die Folgen von kostspieligen Stillständen bis zu gefährlichen Unfällen. Dieser Beitrag stellt eine intelligentere, ressourcenschonendere Methode vor, um Wälzlager über ihre Vibrationen „abzuhören“ und frühe Schadensanzeichen zu erkennen – selbst wenn Maschinen laut sind, Betriebsbedingungen wechseln und Rechenressourcen begrenzt sind.
Vibrationen auf zwei sich ergänzenden Wegen hören
Die Autoren konzentrieren sich darauf, wie sich Vibrationssignale eines Lagers ändern, wenn Innenring, Außenring oder Wälzkörper zu verschleißen oder zu reißen beginnen. Statt nur auf eine Sichtweise dieser Signale zu setzen, kombinieren sie zwei einfache, aber aussagekräftige Beschreibungen. Die eine ist eine kurzzeit‑frequente Ansicht, die zeigt, wann sich Energie über die Zeit bei bestimmten Frequenzen sammelt – empfindlich gegenüber den wiederkehrenden Stößen, die Defekte erzeugen. Die andere ist ein kompakter Satz von sechs zeitbasierten Statistikgrößen – etwa Mittelwert, Streuung und „Spitzenhaftigkeit“ –, die erfassen, wie unregelmäßig oder energiegeladen die Bewegung ist. Zusammen liefern diese Perspektiven ein reichhaltigeres Bild des Lagerzustands, als es jede für sich könnte. 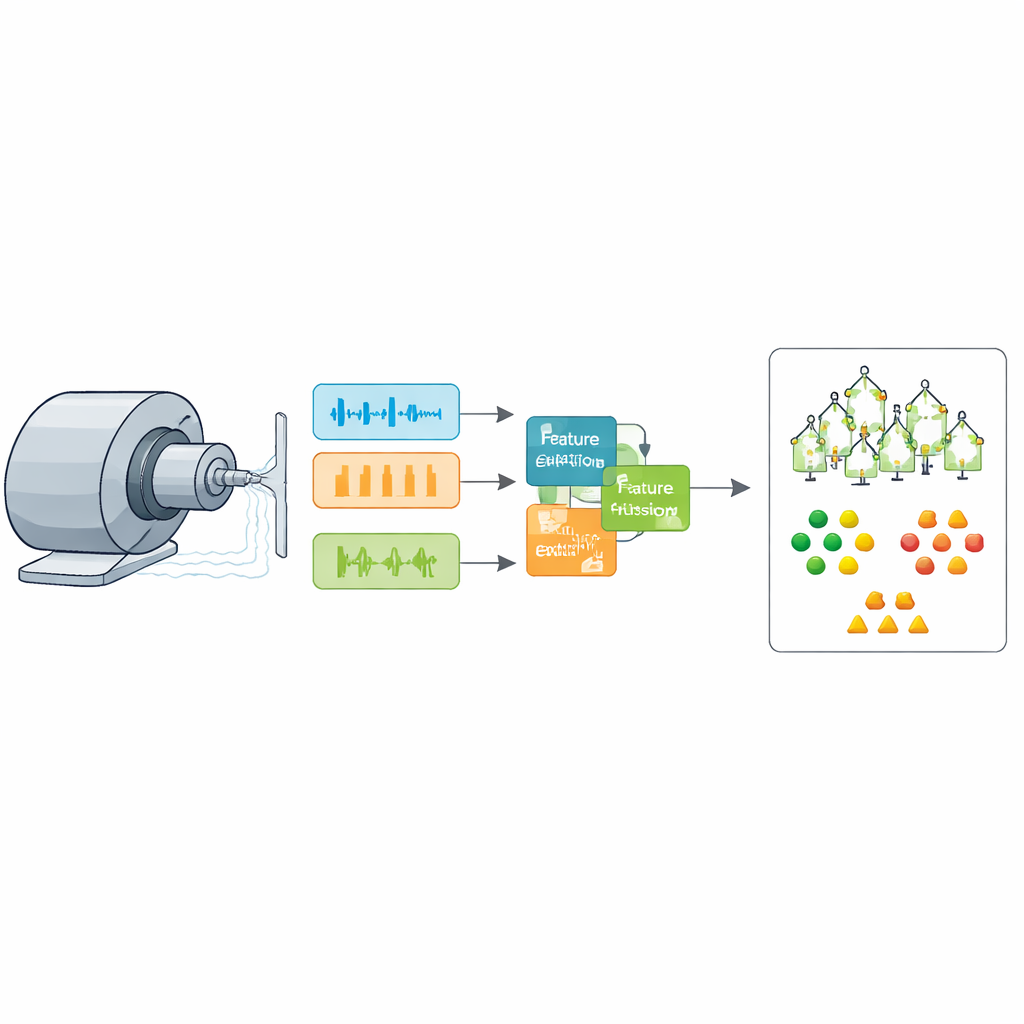
Signal säubern, fokussieren und verschmelzen
Reale Maschinen laufen selten in Laborstille, daher beginnt die Methode mit sorgfältiger Signalreinigung. Das Rohvibrationssignal wird zentriert, auf ein Frequenzband gefiltert, in dem Lagerfehler am aussagekräftigsten sind, und mit Wavelets entrauscht, die kurze, scharfe Ereignisse bewahren. Überlappende Zeitfenster zerschneiden das kontinuierliche Signal in kurze, reproduzierbare Ausschnitte, von denen jeder etwa ein Fünftel Sekunde Bewegung repräsentiert. Für jeden Ausschnitt werden das frequenzbasierte Muster und die sechs zeitbasierten Kennwerte extrahiert und normalisiert, sodass Unterschiede das Lagerverhalten und nicht bloß Änderungen der Gesamtenergie widerspiegeln.
Die Daten entscheiden lassen, was wichtig ist
Statt festzulegen, wie viel Vertrauen jeder Merkmalsart entgegengebracht wird, führen die Autoren eine kleine „Attention“-Einheit ein, die lernt, jene Teile der Frequenz‑ und Zeitinformationen zu betonen, die am hilfreichsten sind, um verschiedene Fehlerarten zu unterscheiden. Konzeptuell verhält sich diese Einheit wie ein Scheinwerfer, der bestimmte Frequenzbänder und bestimmte Statistiken aufhellt, wenn sie mit bekannten Fehlersignaturen übereinstimmen, und diejenigen abdunkelt, die überwiegend Rauschen enthalten. Nach dieser adaptiven Fusion komprimiert ein standardmäßiges Verfahren namens Hauptkomponentenanalyse die 262‑wertige Beschreibung jedes Ausschnitts zu einem kleineren Satz, der dennoch nahezu die gesamte nützliche Variation erhält. Dieser Schritt reduziert Redundanz, beschleunigt das Lernen und hilft, Überanpassung zu vermeiden, ohne die Genauigkeit merklich zu beeinträchtigen.
Aufbau und Abstimmung eines effizienten Entscheidungswaldes
Für die finale Entscheidung verzichten die Autoren auf schwere Deep‑Learning‑Netze und nutzen stattdessen ein Ensemble aus Entscheidungsbäumen, bekannt als Bagging. Jeder Baum lernt einfache Regeln, die den komprimierten Merkmalsraum in Regionen aufteilen, die mit bestimmten Fehlerarten oder gesundem Betrieb assoziiert sind, und das Ensemble stimmt über das finale Label ab. Die Besonderheit liegt in der Wahl der Waldstruktur. Statt Anzahl und Tiefe der Bäume zu raten, verwendet das Team eine populationsbasierte Suche, inspiriert von Schwarm‑ und Jagdbewegungen von Seevögeln. Dieser adaptive Schwarm erkundet Kombinationen von Modellparametern, während er drei Ziele gleichzeitig ausbalanciert: Fehler genau klassifizieren, den Wald kompakt halten und Trainingszeit reduzieren. Lösungen, die diese Ziele balancieren, bilden eine „Front“, aus der ein praxisnaher Betriebspunkt ausgewählt werden kann. 
Robustheit an verschiedenen Prüfständen nachweisen
Die vollständige Pipeline – Reinigung, Dual‑View‑Merkmalextraktion, aufmerksamkeitsbasierte Fusion, Kompression und optimiertes Baumensemble – wurde an drei verschiedenen Lagerprüfständen getestet: zwei bekannten öffentlichen Datensätzen und einem eigenen Versuchsaufbau. Unter diesen unterschiedlichen Bedingungen identifizierte die Methode Fehler an Lagern durchgängig mit etwa 97–99 % Genauigkeit. Sorgfältige Experimente zeigten, dass jede Hauptkomponente wichtig ist: Das Entfernen der Attention‑Einheit, des Multi‑Objective‑Optimierers oder des Kompressionsschritts verschlechterte die Leistung leicht, während die Verwendung nur eines Merkmalsatzes die Zuverlässigkeit merklich reduzierte, besonders bei Rauschen und wechselnden Lasten.
Was das für reale Maschinen bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft: Die Autoren haben einen Diagnoseansatz entwickelt, der einfache, verständliche Bausteine kombiniert – grundlegende Signalreinigung, zwei intuitive Sichtweisen auf Vibrationen und transparente Entscheidungsbäume – und moderne Ideen wie Attention und schwarmähnliche Suche nutzt, um ihr Zusammenspiel zu optimieren. Das Ergebnis ist ein Überwachungskonzept, das genau, relativ leicht interpretierbar und schlank genug ist, um nahe an den geschützten Maschinen betrieben zu werden. Damit ist es ein vielversprechender Kandidat, industrielle Wälzlager dauerhaft zu überwachen und frühe Störsignale zu entdecken, bevor sie zu Ausfällen werden, selbst unter lauten, variablen Bedingungen und bei begrenzter Rechenleistung.
Zitation: Bai, H., Tong, W., Duan, C. et al. Rolling bearing fault diagnosis method based on fusion of STFT-statistical features and AL-SOA optimized bagging tree. Sci Rep 16, 10314 (2026). https://doi.org/10.1038/s41598-026-37914-z
Schlüsselwörter: Fehlerdiagnose von Wälzlagern, Vibrationssignalanalyse, aufmerksamkeitsbasierte Merkmalsfusion, Ensemble‑Lernen, Schwarmoptimierung