Clear Sky Science · de
Entwicklung und Bewertung eines effektiven Löslichkeitsvorhersagemodells für Arzneimittel in organischen Lösungsmitteln mittels maschinellen Lernens auf Basis von eXtreme Gradient Boosting
Warum das Auflösen von Arzneimitteln wirklich wichtig ist
Wenn eine Tablette in den Körper gelangt, muss sich der Wirkstoff zunächst auflösen, bevor er wirken kann. Wie leicht ein Wirkstoff in einer Flüssigkeit löst, beeinflusst die Herstellung eines Medikaments, seine Stabilität und seine Wirksamkeit. Das Messen dieser „Löslichkeit“ in vielen verschiedenen Flüssigkeiten und bei unterschiedlichen Temperaturen ist zeitaufwendig und teuer. Diese Studie untersucht, wie ein modernes Datenwerkzeug — maschinelles Lernen — Wissenschaftlern helfen kann, schnell abzuschätzen, wie gut arzneimittelähnliche Verbindungen in gängigen organischen Lösungsmitteln löslich sind, und zwar mit nur wenigen leicht erhältlichen Informationen.
Das richtige Lösungsmittel für die Kristallbildung wählen
In der Arzneimittelherstellung züchten Hersteller oft Kristalle eines Wirkstoffs aus einem organischen Lösungsmittel. Das Lösungsmittel steuert nicht nur, wie viel Feststoff gewonnen wird; es beeinflusst auch Größe und Form der Kristalle, was wiederum das Verhalten des Medikaments beeinflussen kann. Traditionell führen Chemiker viele Experimente durch oder verwenden komplexe thermodynamische Gleichungen zur Vorhersage der Löslichkeit. Diese etablierten Methoden können genau sein, erfordern jedoch häufig viele anzupassende Parameter oder detaillierte molekulare Daten, die in frühen Entwicklungsstadien nicht vorliegen. Die Autorinnen und Autoren dieser Arbeit fragen daher, ob ein sorgfältig gestaltetes maschinelles Lernmodell die wichtigsten Trends der Löslichkeit erfassen kann, ohne aufwändige Eingabedaten — sondern mit einfachen, physikalisch sinnvollen Eingangsgrößen.
Ein kompakter datengetriebener Ansatz mit physikalischem Bezug
Das Team entwickelte ein Löslichkeitsvorhersagemodell mit einer verbreiteten Methode des maschinellen Lernens, genannt eXtreme Gradient Boosting bzw. XGBoost. Sie sammelten veröffentlichte Löslichkeitsdaten für vier arzneimittelähnliche Moleküle in neun gängigen organischen Lösungsmitteln über einen weiten Temperaturbereich und erhielten so 224 Datenpunkte. Anstatt dem Algorithmus beliebige Deskriptoren zu übergeben, wählten sie zehn Merkmale, die Chemiker bereits verstehen: Eigenschaften des Feststoffs (wie Schmelztemperatur, Schmelzenthalpie, Wärmekapazität und ein bekannter Löslichkeitsparameter), grundlegende Flüssigkeitseigenschaften (Polarität über die Dielektrizitätskonstante und Siedetemperatur) sowie die Temperatur selbst und einfache Kodierungen der Namen von Feststoff und Lösungsmittel. Um zu berücksichtigen, dass sich die meisten Feststoffe bei Erwärmung besser lösen, legten sie eine Regel fest, die die Vorhersagen des Modells mit steigender Temperatur zunehmen lässt und so physikalisch sinnvolles Verhalten sicherstellt.
Wie gut das Modell mit realen Messungen übereinstimmt
Nach Abstimmung des Modells mittels Kreuzvalidierung prüften die Autorinnen und Autoren, wie eng die Vorhersagen mit den Messwerten übereinstimmen. Sie bewerteten die Leistung, indem sie den Logarithmus der gemessenen und vorhergesagten Löslichkeiten verglichen, was geeignet ist, da die Löslichkeiten mehrere Größenordnungen umspannten. Für die vier Verbindungen, die zum Training und Testen verwendet wurden, reproduzierte das Modell die Daten mit sehr geringen durchschnittlichen Fehlern und hoher Korrelation, was darauf hindeutet, dass es die temperaturabhängige Löslichkeit in vielen flüssigen Umgebungen zuverlässig beschreiben kann. Wichtig ist, dass das Modell selbst für eine sehr schlecht lösliche Verbindung, Risperidon, deren Verhalten mit einfacheren Gleichungen schwer zu erfassen ist, genau blieb.
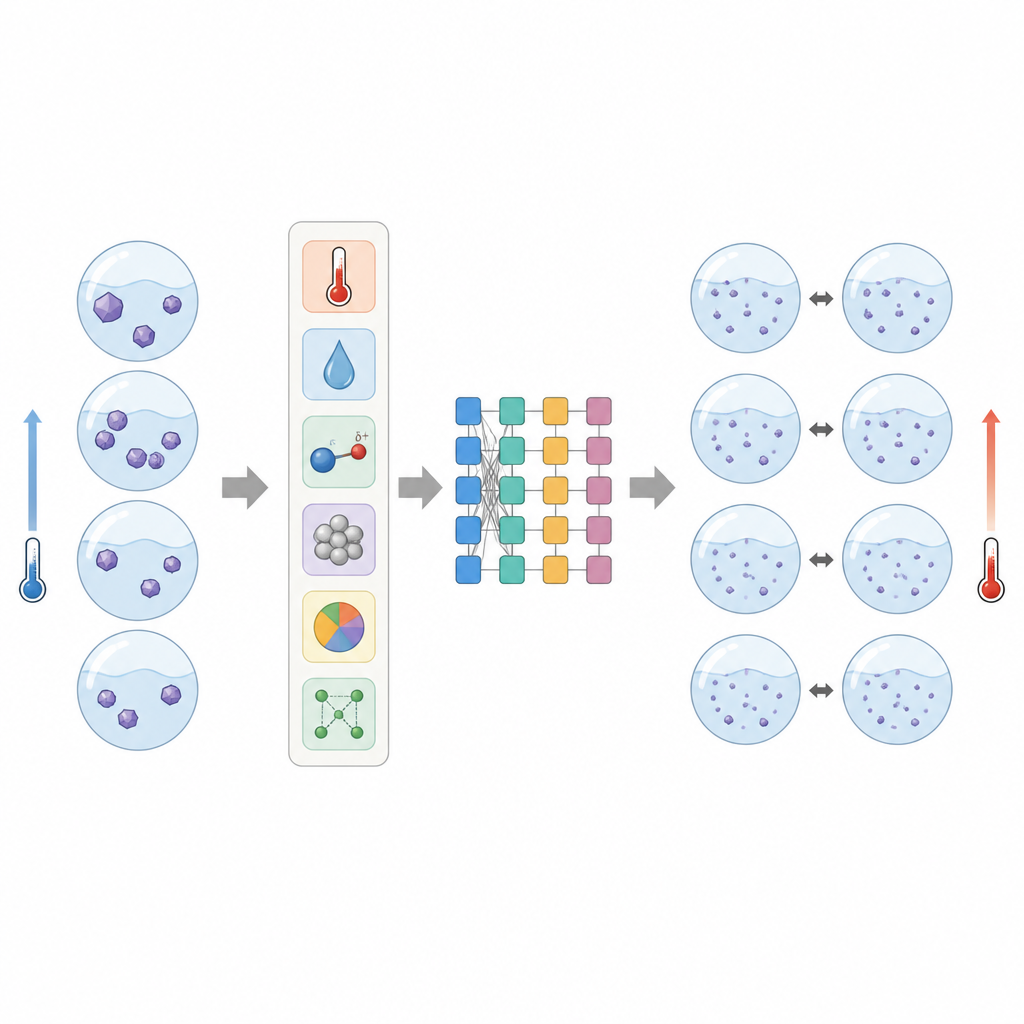
Vorhersage einer völlig neuen Verbindung
Die entscheidende Frage war, ob das Modell mit einem Wirkstoff umgehen kann, den es nie zuvor gesehen hatte. Um dies zu testen, legten die Forschenden alle Daten für eine fünfte Verbindung, Butamben, beiseite und verwendeten diese 50 Messwerte erst nach Abschluss des Trainings. Die Fehler des Modells waren bei dieser echten Vorhersageaufgabe größer als bei den zuvor gesehenen Daten, blieben aber dennoch in einem Bereich, der mit typischer experimenteller Unsicherheit vergleichbar ist, insbesondere für mehrere der getesteten Lösungsmittel. Im Vergleich mit zwei weit verbreiteten semi-vorhersagenden thermodynamischen Methoden, Flory–Huggins und temperaturabhängigem NRTL-SAC, lieferte das XGBoost-Modell insgesamt durchgehend kleinere Fehler und zeigte besonders gute Leistungen bei den anspruchsvollsten Systemen.
Was das für die zukünftige Arzneimittelentwicklung bedeutet
Für Nichtfachleute lautet die Kernbotschaft, dass ein vergleichsweise kleines, physikalisch informiertes Maschinenlernmodell zuverlässig abschätzen kann, wie gut arzneimittelähnliche Moleküle in gängigen organischen Lösungsmitteln über einen Temperaturbereich löslich sind. Es nutzt dazu eine überschaubare Menge messbarer Eigenschaften, ohne die umfangreichen Parameteranpassungen, die in traditionellen Ansätzen oft nötig sind. Die Autorinnen und Autoren weisen darauf hin, dass eine weitere Verfeinerung der gewählten Deskriptoren und breitere Datensätze die Leistung verbessern würden, doch die Studie zeigt bereits, dass solche Modelle die Auswahl von Lösungsmitteln und die Prozessgestaltung unterstützen können und Chemikerinnen und Chemikern helfen, vielversprechende Optionen einzugrenzen, bevor detaillierte Laborarbeiten durchgeführt werden.
Zitation: Valavi, M., Assareh, M., Khoshsima, A. et al. Development and evaluation of an effective solubility prediction model for pharmaceuticals in organic solvents using machine learning based on eXtreme Gradient Boosting. Sci Rep 16, 16592 (2026). https://doi.org/10.1038/s41598-026-53038-w
Schlüsselwörter: Wirkstofflöslichkeit, organische Lösungsmittel, maschinelles Lernen, XGBoost, Kristallisation