Clear Sky Science · de
Physikalisch basierte Modellierung zur retrospektiven Erkennung archäologischer Indikatoren (Cropmarks)
Verborgene Geschichten in alltäglichen Feldern
In vielen Regionen der Welt verbergen ganz gewöhnliche Ackernutzungen leise Spuren alter Gräber, Mauern und Siedlungen. Diese vergrabenen Strukturen können das Pflanzenwachstum darüber subtil verändern und so schwache Muster erzeugen, die als Cropmarks bezeichnet werden und aus der Luft oder von Satelliten aus sichtbar werden. Diese Studie zeigt, wie physikbasierte Modelle und modernes maschinelles Lernen zusammenarbeiten können, um solche Muster zu erkennen – auch in alten Archivbildern – und eröffnet so neue Wege, vergangene Landschaften zu erforschen, ohne den Boden zu stören.
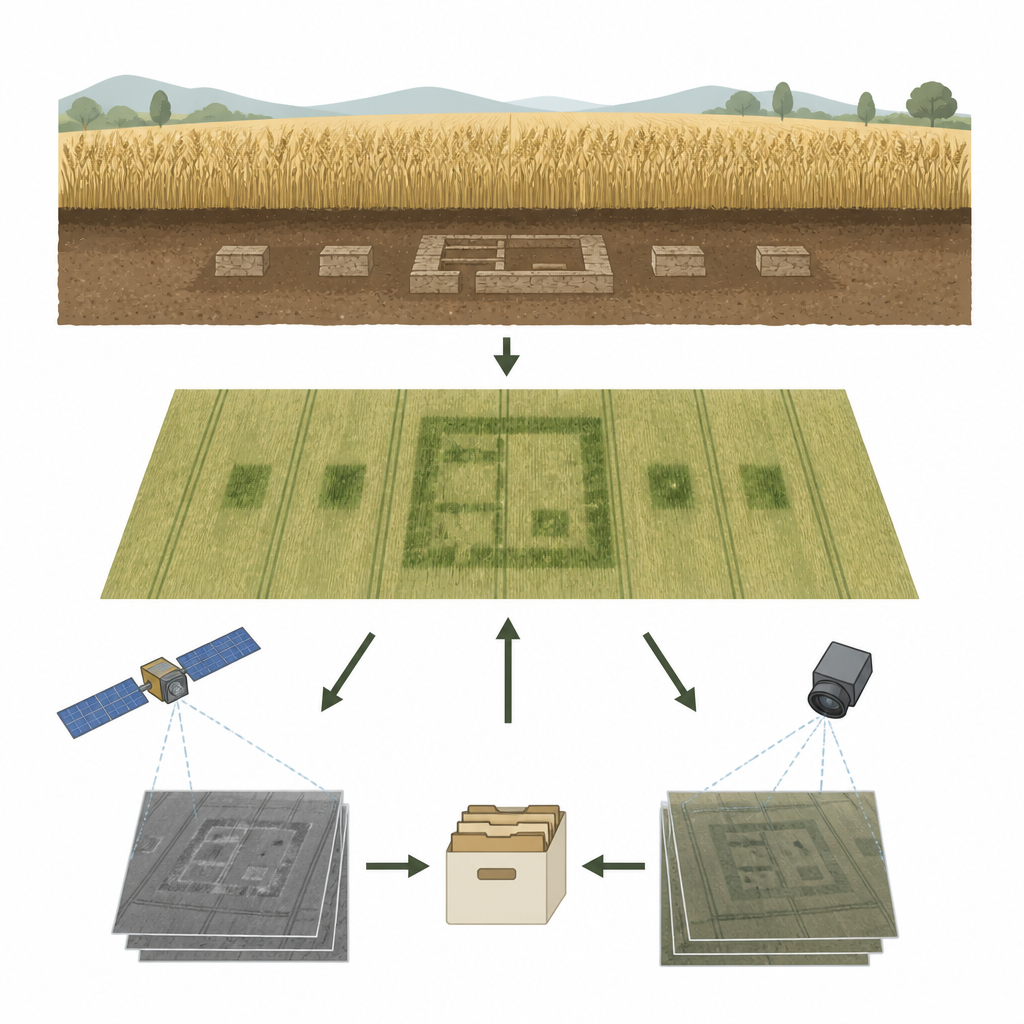
Wie vergrabene Überreste das Pflanzenwachstum beeinflussen
Wenn steinerne Strukturen knapp unter der Oberfläche liegen, verändern sie, wie Wasser und Nährstoffe durch den Boden fließen. An manchen Stellen werden Pflanzen gestaucht und gestresst; an anderen wachsen sie üppiger und erzeugen negative oder positive Cropmarks. Diese Unterschiede sind für das bloße Auge oft zu subtil, beeinflussen jedoch, wie Blätter Sonnenlicht im sichtbaren und im nahen Infrarotbereich reflektieren. Durch Messung dieses reflektierten Lichts können Forschende spektrale „Fingerabdrücke“ von Stress entdecken, die Hinweise auf das darunterliegende verbergen.
Ein Versuchsfeld, das eine antike Stätte nachbildet
Um diese Signale unter kontrollierten Bedingungen zu untersuchen, nutzte das Team ein kleines Gerstenfeld nahe dem Dorf Alampra auf Zypern. Unter diesem fünf mal fünf Meter großen Versuchsareal wurden Strukturen in geringer Tiefe errichtet, die antiken Gräbern nachempfunden sind, wobei die natürliche Bodenlagerung sorgfältig erhalten blieb. Über zwei Vegetationsperioden, getrennt durch dreizehn Jahre, sammelten sie detaillierte Messungen des von den Pflanzen über den vergrabenen Merkmalen reflektierten Lichts, von gesunden Pflanzen in der Umgebung und von nacktem Boden. Die jüngere Kampagne konzentrierte sich auf die wichtigen Wintermonate, in denen die Pflanzen ihre größte Grünheit zeigen, und verfolgte später deren Altern und Austrocknen.
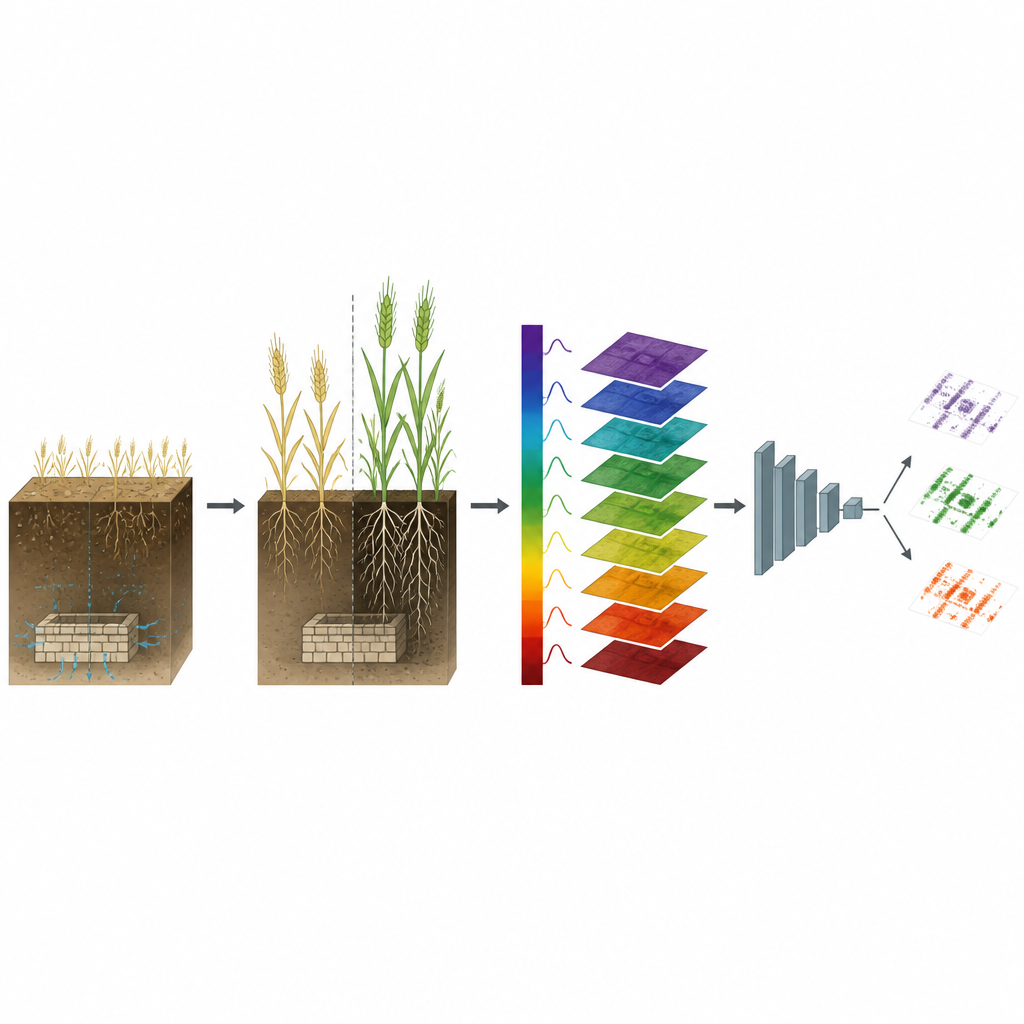
Pflanzenlicht simulieren, um virtuelle Daten zu erzeugen
Der Kern des Ansatzes ist ein Computermodell namens PROSAIL, das die Physik des Lichts berücksichtigt, das durch Blätter und Pflanzenbestände hindurchtritt, und so das, was ein Sensor sieht, mit Pflanzenmerkmalen wie Blattpigmenten, Wassergehalt und Dichte verknüpft. Die Forschenden „invertierten“ das Modell: Sie fütterten es mit den gemessenen Spektren und fragten, welche Kombinationen von Pflanzenparametern diese erklären könnten, wobei sie die Lösungen behutsam in Richtung realistischer Werte aus der Pflanzenwissenschaft steuerten. Aus diesen geschätzten Parametern erstellten sie statistische Beschreibungen darüber, wie sich jede Eigenschaft variierte und wie Eigenschaften untereinander für sowohl Cropmarks als auch gesunde Pflanzen an jedem Beobachtungsdatum verknüpft waren.
Aufbau synthetischer Felder für das maschinelle Lernen
Mithilfe dieser statistischen Muster generierte das Team große synthetische Mengen an Pflanzenparametern und ließ PROSAIL vorwärts laufen, um tausende realistische „virtuelle“ Spektren für jede Pflanzenbedingung und jedes Datum zu erzeugen. Jedes synthetische Spektrum trug ein bekanntes Label: über vergrabenem Merkmal oder gesunder Bereich. Anschließend trainierten sie ein Ensemble verschiedener Klassifikatoren des maschinellen Lernens mit diesen synthetischen Daten und fügten gelegentlich kleine Mengen Rauschen hinzu, um reale Sensorbedingungen besser nachzuahmen. Der entscheidende Test war retrospektiv: Modelle, die aus der Kampagne 2025 aufgebaut wurden, sollten Signaturen von Cropmarks in den Messungen von 2012 identifizieren und simulierten damit, wie solche Werkzeuge alte Luft- oder Satellitenaufnahmen durchsuchen könnten.
Was die Modelle über Timing und Zuverlässigkeit zeigten
Die retrospektiven Tests zeigten, dass die Methode unter günstigen Bedingungen mehr als 90 Prozent vergangener Signaturen korrekt klassifizieren kann. Am besten funktionierten die Modelle, wenn die Pflanzen in ihrer Phase maximaler Grünheit waren, wenn der Wuchsdeckel dicht ist und Blattparameter relativ einheitlich sind. In diesem Zeitraum lieferten sogar einfache, nahezu lineare Klassifikatoren gute Ergebnisse, und das Hinzufügen von Rauschen machte die Modelle etwas robuster. Mit dem Übergang in die Seneszenz, wenn Pflanzen ungleichmäßiger in Farbe und Struktur werden, wurden die Vorhersagen instabiler und stärker abhängig davon, wie viele synthetische Trainingsdaten verwendet wurden. Dennoch blieben die synthetischen Spektren den realen nahe, und maschinelle Lernmodelle konnten weiterhin nützliche Muster finden, besonders wenn sie sorgfältig abgestimmt wurden.
Warum das für die Erforschung der Vergangenheit wichtig ist
Diese Forschung demonstriert eine reproduzierbare Pipeline, die bei physikalischen Modellen der Pflanzen-Licht-Interaktion beginnt, diese Modelle nutzt, um synthetische Trainingsdaten zu konstruieren, und anschließend maschinelles Lernen anwendet, um subtile Spuren menschlicher Aktivität zu erkennen. Für Nicht-Spezialisten ist die zentrale Idee: Wir können unser Verständnis der Pflanzenphysik verwenden, um Computern beizubringen, wie vergrabene Überreste spektral aussehen sollten, und diese trainierten Detektoren dann retrospektiv auf Archivbilder anzuwenden. Obwohl die aktuelle Arbeit auf einem einzigen Versuchsfeld basiert und auf andere Kulturen, Böden und Klimata ausgeweitet werden muss, bietet sie einen Weg, systematisch Luft- und Satellitenarchive nach langvergessenen Cropmarks zu durchsuchen und Archäologen dabei zu helfen, verborgene Stätten wiederzuentdecken, die die heutige Landschaft nicht mehr offenbart.
Zitation: Gravanis, E., Agapiou, A. Physically-based modelling for retrospective detection of archaeological proxies (cropmarks). Sci Rep 16, 15089 (2026). https://doi.org/10.1038/s41598-026-45441-0
Schlüsselwörter: cropmarks, archäologische Prospektion, Fernerkundung, synthetische Daten, maschinelles Lernen