Clear Sky Science · de
Kombinierter maschineller Lern- und 3D-physikalischer Ansatz zur Bewertung von Gebäudeschäden: der Fall L’Aquila 2009
Warum das für Menschen, die in Erdbebengebieten leben, wichtig ist
Nach einem starken Erdbeben ist die dringendste Frage, welche Gebäude wieder betreten werden können und welche gesperrt bleiben müssen. Traditionell erfordert das langsame Vor-Ort-Inspektionen und stützt sich auf großflächige Intensitätskarten, die lokale Besonderheiten von Gelände und Stadtgeometrie übersehen können. Diese Studie konzentriert sich auf das verheerende Erdbeben von 2009 in L’Aquila, Italien, und zeigt, wie die Kombination fortschrittlicher Computermodelle der Erschütterung mit künstlicher Intelligenz helfen kann, schnell die am stärksten beschädigten Gebäude zu kennzeichnen und die Vorbereitung auf künftige Beben zu verbessern.
Ein genauerer Blick auf eine italienische Stadt
Die Autorinnen und Autoren nutzen L’Aquila als Praxisfall, weil das Hauptbeben stark, gut aufgezeichnet und ausführlich untersucht wurde und weil die Geologie der Stadt in außergewöhnlicher Detailtiefe kartiert ist. Sie arbeiten mit Daten zu etwa 3.000 Gebäuden, deren Schäden nach dem Beben der Magnitude 6,1 sorgfältig erhoben wurden. Für jedes Bauwerk kennen sie nicht nur das Ausmaß der Schäden, sondern auch Bauweise, Größe, Baujahr und Lage in Bezug auf die Verwerfung und das lokale Gelände. Dieses reichhaltige Bild ermöglicht es ihnen zu untersuchen, welche Faktoren tatsächlich bestimmen, ob ein Gebäude ein Beben mit leichten Schäden übersteht oder an den Rand des Zusammenbruchs gerät.
Das Untergrundmodell zur Verbesserung der Erschütterungsschätzung
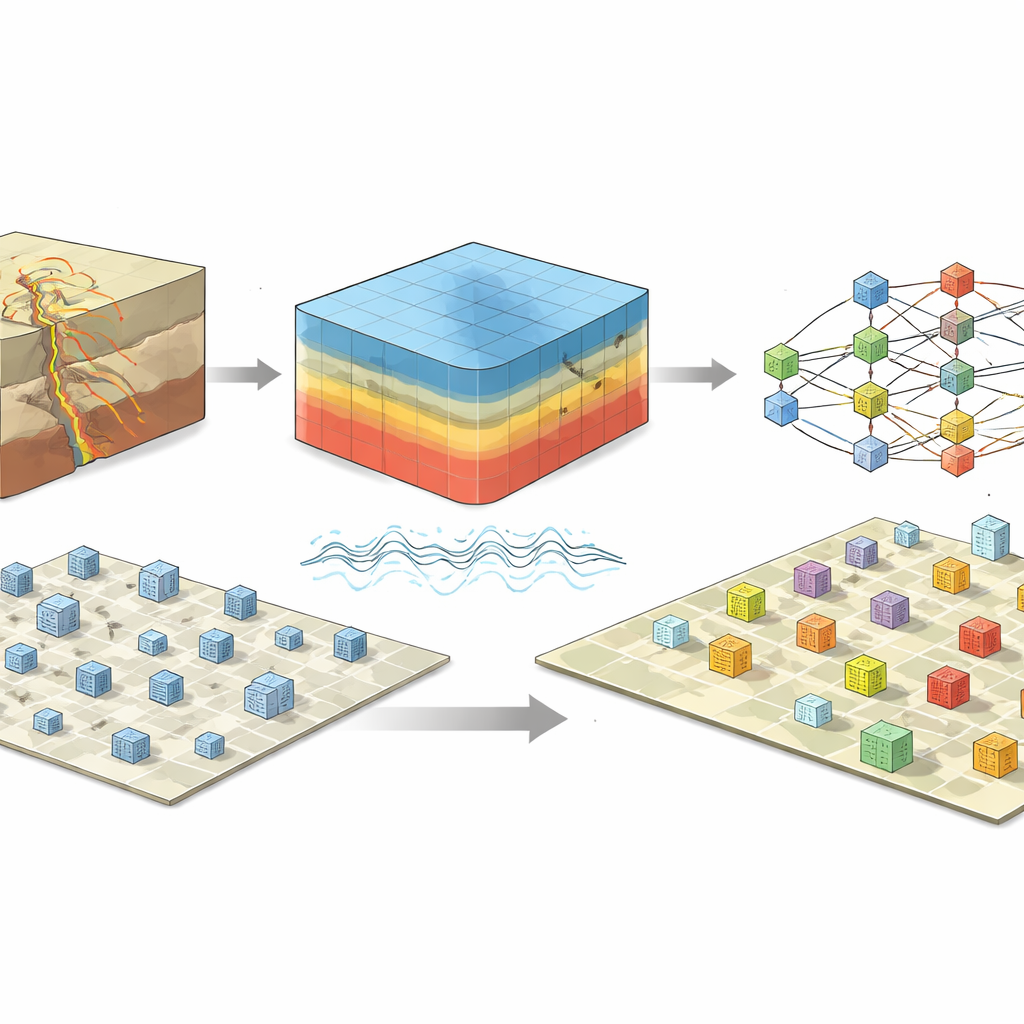
Übliche Instrumente zur Abschätzung von Erdbebenschäden beginnen oft mit ShakeMaps, die eine begrenzte Anzahl Bodenmessungen mit vereinfachten Formeln kombinieren, um die Bodenbewegung über eine Region zu schätzen. Das Team baut stattdessen ein detailliertes dreidimensionales digitales Modell der Kruste und der sedimentären Becken um L’Aquila, bis in etwa 20 Kilometer Tiefe und über rund 60 Kilometer in jede horizontale Richtung. Mit Hochleistungsrechnern und einem spezialisierten Code simulieren sie, wie sich seismische Wellen von der Verwerfung durch diese komplexe Untergrundlandschaft ausbreiteten. Anschließend erweitern sie die Simulationen, um sowohl niedrige als auch hohe Frequenzen der Bewegung abzudecken, und erzeugen realistische Größen für die Bodengeschwindigkeit und -beschleunigung an Tausenden von Punkten, an denen die Gebäude tatsächlich stehen.
Eine digitale Wald von Entscheidern darin schulen, Schäden zu erkennen
Mit diesem gebäudeweisen Bild der Erschütterung trainieren die Forschenden Modelle des maschinellen Lernens – konkret Ensembles von Entscheidungsbäumen, bekannt als Random Forests – zur Vorhersage von Schadensklassen. Um das Problem handhabbarer zu machen, fassen sie die ursprünglichen sechs Schadensgrade in zwei oder drei breitere Klassen zusammen, etwa „leicht versus mittel bis schwer“ oder „leicht bis mittel versus schwer“. Jedes Modell sieht eine Mischung aus gebäudebezogenen Merkmalen (wie Höhe, Grundfläche und Alter) und standortspezifischen Eigenschaften (wie Abstand zur Verwerfung und lokale Bodeneigenschaften) sowie entweder simulierte Erschütterungskennwerte oder solche aus ShakeMaps. Sie gehen auch mit fehlenden Angaben, etwa unbekannten Baujahren, durch sorgfältige Datenimputation um und gleichen ungleiche Klassenverteilungen mit synthetischen Beispielen aus, damit seltene, aber wichtige schwere Schäden nicht übersehen werden.
Was die Modelle über Risiko verraten
Die Analyse zeigt, dass die einflussreichsten Prädiktoren für Schäden die durchschnittliche Gebäudefläche oder Blockfläche, der Abstand zum Teil der Verwerfung mit den größten Verschiebungen, die lokale Bodensteifigkeit und – entscheidend – die aus physikbasierten Simulationen berechneten Erschütterungsgrößen sind. Im Gegensatz dazu spielen die entsprechenden Werte aus ShakeMaps unter den wichtigsten Variablen kaum eine Rolle. Wenn die Modelle auf den simulierten Erschütterungen basieren, erreichen sie Genauigkeiten von rund 80 Prozent bei den einfacheren Zwei-Klassen-Problemen und zeigen robuste Leistungen auf einem separaten, zuvor nicht gesehenen Testsatz von Gebäuden. Das legt nahe, dass die Erfassung des tatsächlichen dreidimensionalen Pfads seismischer Wellen, statt sie mit groben regionalen Formeln zu glätten, unsere Fähigkeit deutlich schärfen kann, leicht beschädigte Strukturen von ernsthaft beeinträchtigten zu unterscheiden.
Was das für künftige Erdbeben bedeutet
Für Nichtfachleute lautet die wichtigste Erkenntnis, dass die Kombination realistischer Computersimulationen der tatsächlichen Bodenbewegung mit modernen Mustererkennungsalgorithmen verstreute Messungen und Gebäudeakten in ein praktisches Werkzeug für den Kriseneinsatz verwandeln kann. Bei einem zukünftigen Erdbeben könnte ein nach diesem Prinzip aufgebautes System schnell Stadtteile hervorheben, in denen mit schweren Schäden zu rechnen ist, und so Inspektionen, Unterkunftsplanung und langfristigen Wiederaufbau lenken. Die Autorinnen und Autoren weisen darauf hin, dass ihr aktuelles Modell auf eine spezifische Region und die dortige Gebäudesubstanz abgestimmt ist und vor einer Übertragung auf andere Gebiete getestet und angepasst werden muss. Dennoch deuten ihre Ergebnisse auf eine Zukunft hin, in der detaillierte digitale Zwillinge des Untergrunds kombiniert mit datengetriebenen Modellen Gemeinschaften helfen, ihr Erdbebenrisiko besser zu verstehen und zu managen.
Zitation: Di Michele, F., Pera, D., Mazzieri, I. et al. Combined machine learning - 3D physics based approach for building damage evaluation: the case of L’Aquila 2009. Sci Rep 16, 10919 (2026). https://doi.org/10.1038/s41598-026-45377-5
Schlüsselwörter: Erdbebenschäden, maschinelles Lernen, physikalische Simulation, Gebäuderisiko, L’Aquila 2009