Clear Sky Science · de
U-Trans: ein Foundation-Modell zur Darstellung seismischer Wellenformen und zur Verbesserung nachgelagerter Erdbebenaufgaben
Warum klügeres Lauschen auf Erdbeben wichtig ist
Erdbeben können ohne Vorwarnung auftreten, aber die Vibrationen, die sie durch die Erde senden, enthalten eine Fülle von Informationen. Diese Schwingungssignale schnell und zuverlässig in Antworten umzuwandeln — Wo ist es passiert? Wie stark war es? Welche Verwerfung hat sich bewegt? — ist die Aufgabe moderner Erdbebenüberwachungssysteme. Diese Studie stellt eine neue Art vor, seismische Wellen mit einem leistungsfähigen, allgemeingültigen KI-Modell zu „hören“, das darauf ausgelegt ist, viele verschiedene Erdbebenaufgaben gleichzeitig zu verbessern und auch dann gut zu funktionieren, wenn nur wenige gelabelte Daten verfügbar sind.
Ein neues gemeinsames Gehirn für Erdbebendaten
Die meisten bestehenden KI-Werkzeuge für Erdbeben sind Spezialisten: Ein Netzwerk erkennt das Eintreffen wichtiger Wellen, ein anderes schätzt die Magnitude, ein drittes bestimmt den Ort usw. Sie werden oft für eine einzelne Region trainiert und haben Schwierigkeiten, wenn sie woanders eingesetzt werden. Die Autoren schlagen eine andere Strategie vor, inspiriert von Foundation-Modellen in Sprache und Bildverarbeitung: ein großes Modell entwickeln, genannt U-Trans, das aus Millionen von Beispielen eine reiche innere Darstellung seismischer Wellenformen lernt und diese Darstellung dann mit vielen nachgelagerten Werkzeugen teilt. Anstatt bestehende Modelle zu ersetzen, fungiert U-Trans als gemeinsamer „Feature-Motor“, der ihnen zusätzliche, informative Signale liefert.
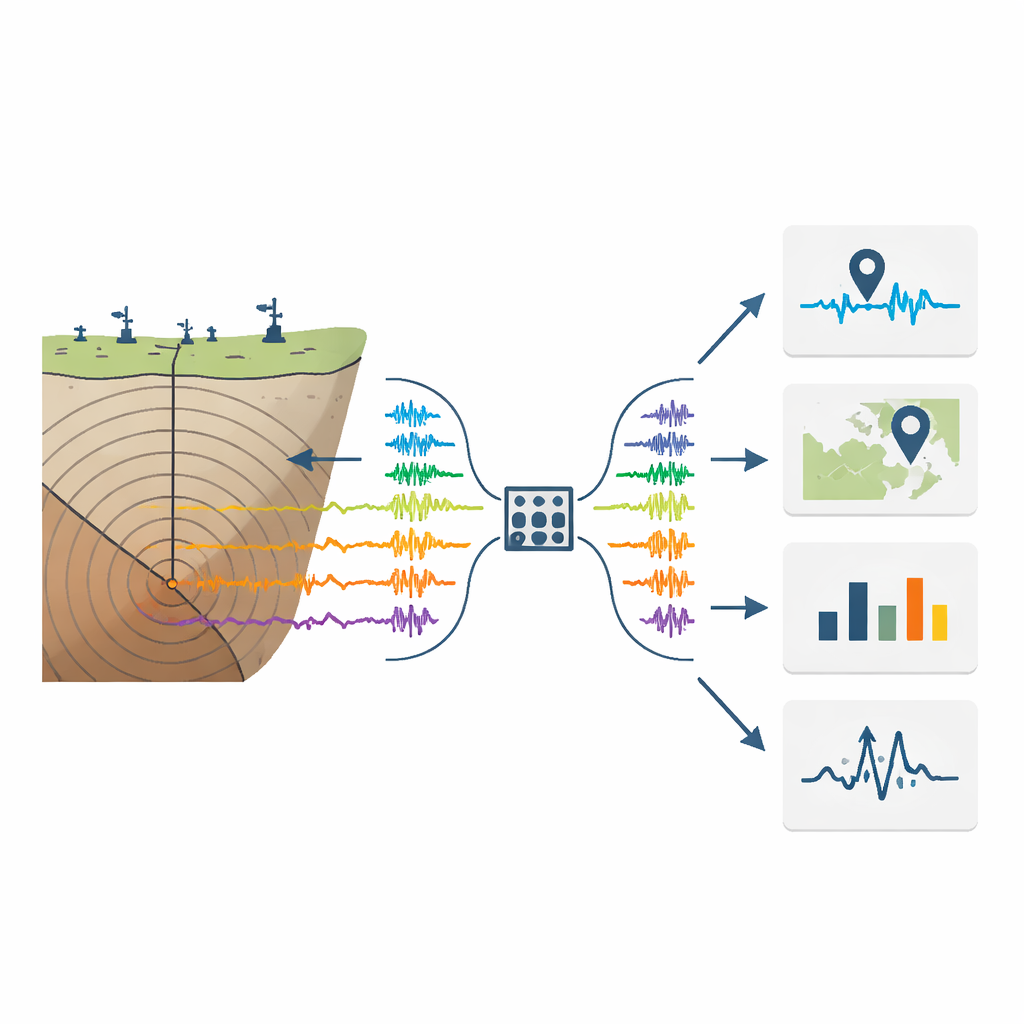
Das Modell durch Verbergen von Teilen lehren
Zum Trainieren von U-Trans benötigen die Forscher keine menschlichen Labels wie Ereigniszeit oder Magnitude. Stattdessen verwenden sie eine selbstüberwachte Aufgabe: Sie nehmen reale dreikomponentige Seismogramme aus mehreren globalen Datensätzen, entfernen absichtlich bis zu etwa ein Drittel ihres Inhalts in Zeit und Frequenz und fordern das Netzwerk auf, das Fehlende zu rekonstruieren. Architekturbedingt kombiniert U-Trans einen U-förmigen Encoder–Decoder, der feine lokale Ausschläge in den Spuren erfasst, mit einem kompakten Transformer-Modul in der Mitte, das langreichweitige Beziehungen über die Wellenform hinweg lernt. Das Erlernen des „Ausfüllens der Lücken“ zwingt das Modell dazu, die zugrundeliegende Physik von P‑ und S‑Wellen zu internalisieren und sinnvolle Signale von Rauschen zu unterscheiden.
Verborgene Muster, die die Ankünfte wichtiger Wellen verfolgen
Nach dem Training an etwa 2,5 Millionen Seismogrammen kann U-Trans beschädigte Wellenformen glaubwürdig rekonstruieren, was zeigt, dass es die wesentliche Struktur der Daten erfasst hat. Wenn die Autoren die internen latenten Merkmale untersuchen — im Grunde das komprimierte innere Bild, das das Modell von jeder Wellenform bildet —, stellen sie fest, dass diese Merkmale rund um die Ankunftszeiten von P‑ und S‑Wellen aufleuchten, den Hauptwellentypen, die in der Erdbebenüberwachung verwendet werden. Bei verrauschten Aufzeichnungen ohne echte Ereignisse sind die latenten Muster diffus und unstrukturiert. Eine separate Visualisierungstechnik zeigt, dass sich die internen Repräsentationen des Modells auf natürliche Weise so gruppieren, dass Erdbebensignale vom Rauschen getrennt werden, obwohl dem Modell nie explizit gesagt wurde, welches welches ist.
Viele Erdbebenaufgaben gleichzeitig verbessern
Um zu testen, ob diese gelernten Merkmale tatsächlich nützlich sind, koppeln die Autoren U-Trans an mehrere etablierte Deep‑Learning‑Werkzeuge: eines zum Bestimmen von P‑ und S‑Wellenankunftszeiten, eines zum Lokalisieren von Ereignissen aus Ein‑Stations‑Daten, eines zur Magnitudenschätzung und eines zur Klassifizierung der ersten Aufwärts‑ oder Abwärtsbewegung einer P‑Welle. Für jede Aufgabe fügen sie die latenten Merkmale von U-Trans als vierten Eingabekanal neben dem rohen dreikomponentigen Seismogramm hinzu und feintunen das kombinierte System. Über Datensätze aus Kalifornien, Texas, Italien und Japan hinweg — einschließlich Regionen, die nicht im ursprünglichen Training verwendet wurden — reduziert diese einfache Ergänzung konstant die Fehler. Die Bestimmung der Ankunftszeiten wird präziser, Entfernungen und Tiefen werden genauer geschätzt, Magnitudenvorhersagen stimmen besser mit Katalogwerten überein und die Polaritätsklassifikation verbessert sich, selbst wenn nur ein kleiner Bruchteil gelabelter Daten verfügbar ist.

Was das für die zukünftige Erdbebenüberwachung bedeutet
Die Studie zeigt, dass ein einziges, selbstüberwachtes Foundation‑Modell eine allgemeine „Sprache“ seismischer Schwingungen lernen kann, die vielen verschiedenen Überwachungsaufgaben zugutekommt. Indem es sich auf die Rekonstruktion teilweise verborgener Wellenformen konzentriert, legt U-Trans natürlicherweise Gewicht auf die Wellenankünfte, die Seismologen am meisten interessieren, und gibt diese destillierten Informationen an nachgelagerte Modelle weiter. Praktisch verspricht dieser Ansatz genauere und robustere Erdbebenkataloge, bessere Leistung in Regionen mit begrenzten Trainingsdaten und ein flexibles Framework, das erweitert werden kann, wenn neue Aufgaben entstehen. Für die Öffentlichkeit ist es ein Schritt hin zu schnelleren, zuverlässigeren Einschätzungen, wann, wo und wie stark sich die Erde gerade bewegt hat.
Zitation: Saad, O.M., Chen, Y. & Alkhalifah, T. U-Trans: a foundation model for seismic waveform representation and enhanced downstream earthquake tasks. Sci Rep 16, 12657 (2026). https://doi.org/10.1038/s41598-026-41454-x
Schlüsselwörter: Erdbebenüberwachung, seismische Wellenformen, Deep Learning, Foundation-Modelle, selbstüberwachtes Lernen