Clear Sky Science · de
SYN-OCT: Ein synthetischer Datensatz von okulären Optischen Kohärenztomographie-Bildern aus gesunden und glaukomatösen Augen
Warum gefälschte Augenuntersuchungen für reale Patienten wichtig sind
Glaukom ist eine führende Ursache für Erblindung, und moderne Augenkliniken verlassen sich auf detaillierte Aufnahmen des Augenhintergrunds, um die Erkrankung früh zu erkennen. Die Entwicklung intelligenter Programme zur Auswertung dieser Aufnahmen erfordert jedoch große Mengen an Patientendaten, die aus Datenschutzgründen nur schwer zu teilen sind. Dieser Artikel stellt SYN-OCT vor, eine umfangreiche Sammlung vollständig synthetischer Augenaufnahmen, die realistisch aussehen und sich wie echte verhalten. Dadurch erhalten Forschende eine neue Möglichkeit, Algorithmen zur Glaukomerkennung zu entwickeln und zu testen, ohne personenbezogene medizinische Daten preiszugeben.
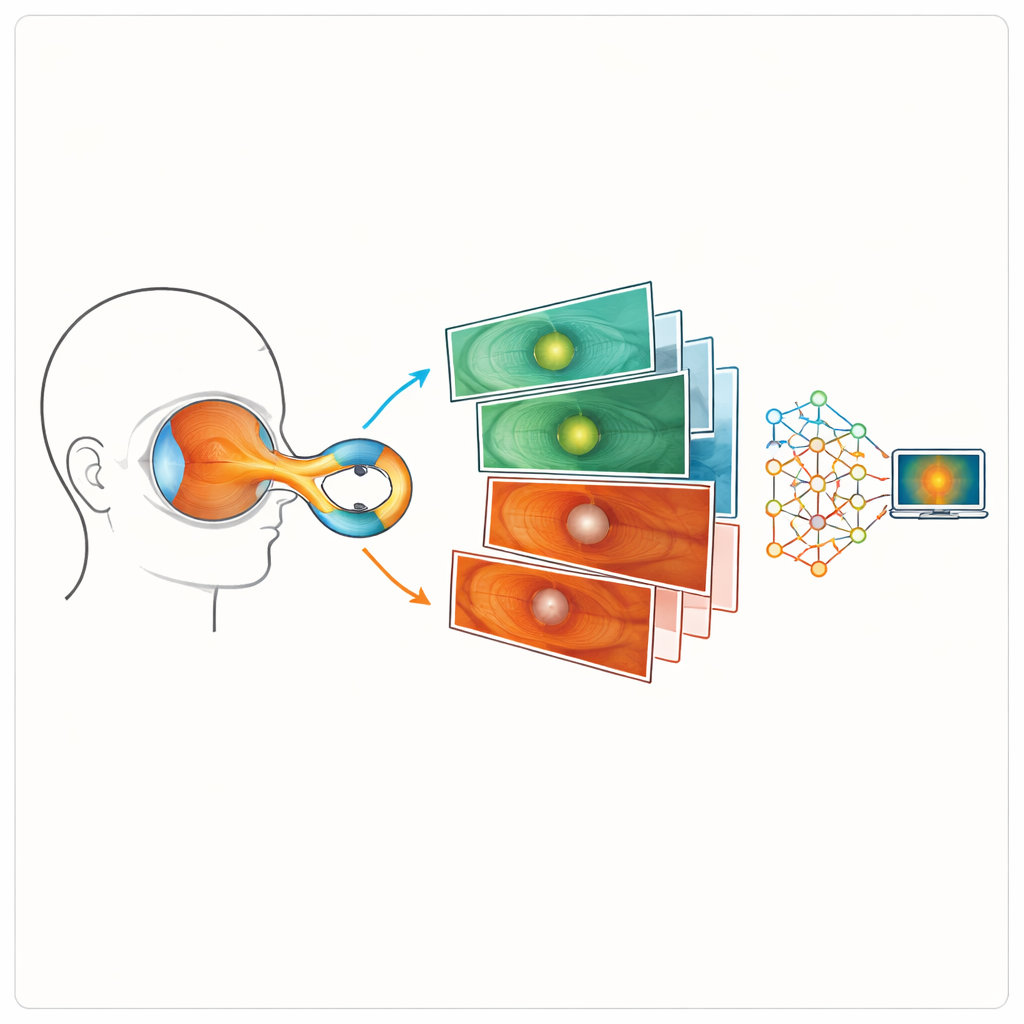
Das Auge im Querschnitt sehen
Im Mittelpunkt der Arbeit steht ein häufiges bildgebendes Verfahren der Augenheilkunde, die Optische Kohärenztomographie (OCT), die querschnittsartige „Scheiben“ der Netzhaut erfasst. Die Autorinnen und Autoren konzentrierten sich auf zirkumpapilläre Aufnahmen, dünne Ringe um den Sehnerv, an denen die Dicke der retinalen Nervenfaserschicht (RNFL) gemessen wird. Diese Schicht ist entscheidend, weil sie bei glaukomatösem Schaden des Sehnervs ausdünnt. Im klinischen Alltag vergleichen Ärztinnen und Ärzte RNFL‑Profile aus solchen Aufnahmen zwischen gesunden und glaukomatösen Patienten, um die Erkrankung zu diagnostizieren und ihren Verlauf zu überwachen.
Realistische Bilder aus dem Nichts schaffen
Um ihren synthetischen Datensatz zu erstellen, sammelte das Team zunächst reale OCT‑Aufnahmen von fast zweitausend Augen, die zwischen 2012 und 2021 am Singapore Eye Research Institute untersucht worden waren. Eine Gruppe umfasste Personen mit klinisch bestätigtem Glaukom; eine andere bestand aus Erwachsenen ohne relevante Augenerkrankung. Statt diese realen Bilder zu teilen, trainierten die Forschenden zwei getrennte bildgenerierende Systeme — eines für gesunde Augen und eines für glaukomatöse Augen — mithilfe einer Technik namens Generative Adversarial Network (GAN). Bei diesem Ansatz versucht ein Netzwerk, realistische Bilder zu erzeugen, während ein anderes zwischen echt und gefälscht zu unterscheiden versucht; durch dieses Gegenspiel verbessern sich beide, bis die erzeugten Bilder echten OCT‑Aufnahmen sehr ähnlich sind.
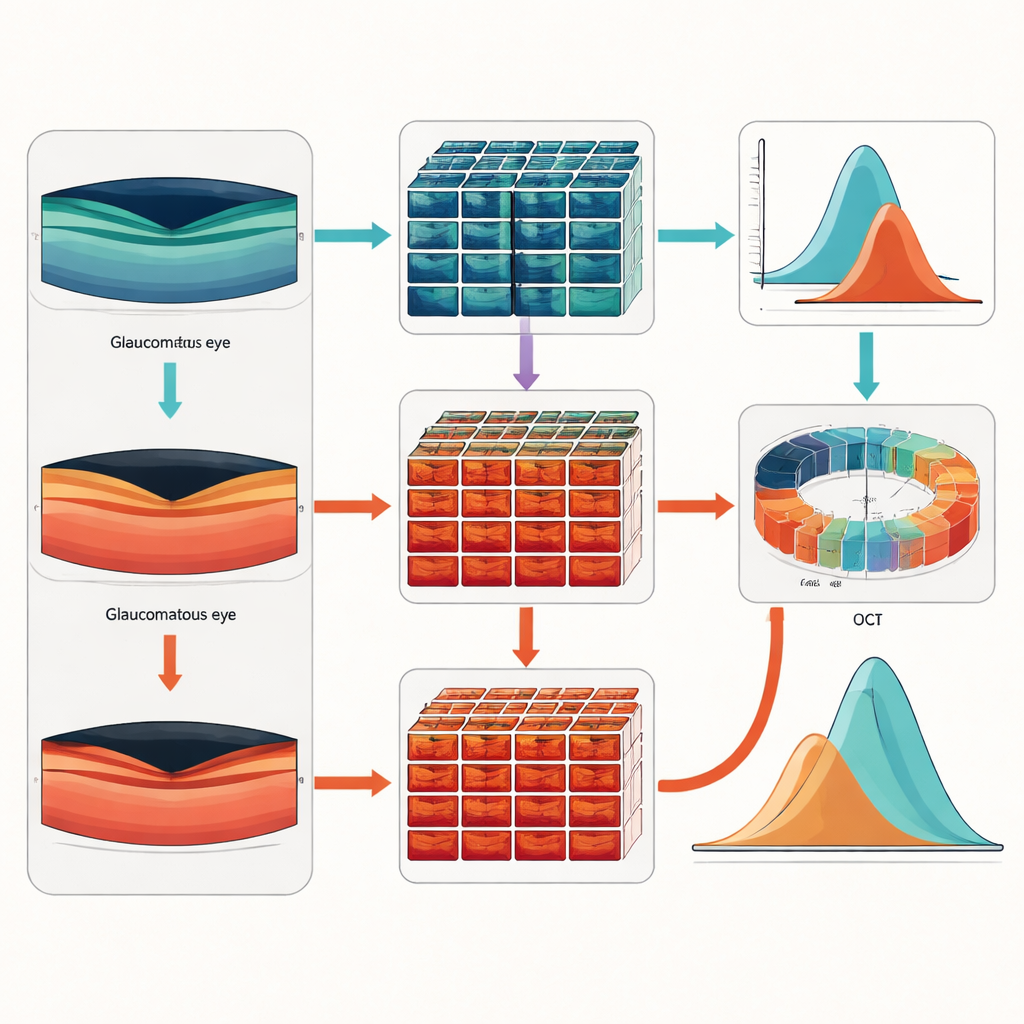
Prüfen, ob die Fälschungen sich wie das Original verhalten
Überzeugende Bilder zu erzeugen reicht nicht aus; sie müssen auch dieselbe medizinische Aussagekraft wie echte Aufnahmen haben. Die Autorinnen und Autoren nutzten zunächst einen standardisierten Bildqualitätswert, um zu bestätigen, dass die synthetischen Aufnahmen dem Original in der Erscheinung nahekommen, und baten dann erfahrene Augenärztinnen und -ärzte, eine Stichprobe zu begutachten. Die Spezialisten konnten echt und synthetisch nur geringfügig besser als zufällig unterscheiden, was zeigt, dass die Fälschungen visuell sehr überzeugend waren. Um noch tiefer zu prüfen, ließen die Forschenden alle Bilder — echte und synthetische — durch ein automatisiertes Werkzeug laufen, das die RNFL‑Dicke um den Sehnerv misst. Die allgemeinen Muster und die mittleren Dickenwerte der synthetischen Aufnahmen stimmten mit denen der realen Aufnahmen überein, und sie bewahrten ein zentrales medizinisches Merkmal: Glaukomaufnahmen zeigten durchgängig dünnere Nervenfaserschichten als gesunde.
Synthetische Daten auf die Probe stellen
Der anspruchsvollste Test war, ob diese künstlichen Aufnahmen reale Patientendaten beim Training diagnostischer Werkzeuge ersetzen können. Die Forschenden trainierten ein Deep‑Learning‑Modell, um zwischen glaukomatösen und gesunden Augen zu unterscheiden, ausschließlich mit realen Bildern, und ein weiteres ausschließlich mit synthetischen Bildern. Beide Modelle wurden anschließend mit unbekannten Daten von lokalen Patientinnen und Patienten sowie von einem unabhängigen Krankenhaus in Rumänien geprüft. Das ausschließlich mit synthetischen Aufnahmen trainierte Modell erzielte mindestens genauso gute Ergebnisse wie das mit realen Daten trainierte Modell und in einigen Fällen sogar leicht bessere, was darauf hindeutet, dass hochwertige synthetische Bilder beim Aufbau robuster, über verschiedene klinische Umgebungen generalisierender Werkzeuge helfen können.
Eine sichere Abkürzung zu besserer Augenversorgung
Für Laien lautet die zentrale Botschaft: SYN-OCT bietet eine Möglichkeit, die Vorteile großer medizinischer Datensätze zu „nutzen“, ohne die privaten Details realer Personen zu übertragen. Indem gezeigt wird, dass computergenerierte Augenaufnahmen sowohl das Aussehen als auch die medizinisch relevanten Messwerte echter Bilder nachahmen können — und sich erfolgreich zum Training von Glaukom‑Erkennungssystemen eignen — weist diese Arbeit in eine Zukunft, in der Krankenhäuser und Labore reichhaltige Bildressourcen freier teilen können. Das könnte die Entwicklung besserer, gerechter getesteter und weiter verbreiteter Werkzeuge zur Früherkennung von Glaukom beschleunigen, und zwar bei gleichzeitiger Wahrung des Patientendatenschutzes.
Zitation: Wong, D., Sreejith Kumar, A.J., Chong, R.S. et al. SYN-OCT:A synthetic dataset of ocular optical coherence tomography images from healthy and glaucoma eyes. Sci Data 13, 637 (2026). https://doi.org/10.1038/s41597-026-06946-5
Schlüsselwörter: Glaukom, synthetische medizinische Daten, Optische Kohärenztomographie, Deep Learning in der Ophthalmologie, Datenschutz bei medizinischen Bildern