Clear Sky Science · de
Vorbereitungsphase großer Erdbeben durch unüberwachte Kategorisierung von Merkmalen in Erdbebenkatalogen beleuchtet
Warum das für Menschen in erdbebengefährdeten Regionen wichtig ist
Weltweit leben Gemeinschaften mit der Angst vor verheerenden Erdbeben, doch Wissenschaftler können immer noch nicht genau sagen, wann und wo das nächste große Ereignis eintreten wird. Diese Studie untersucht, ob subtile Veränderungen bei alltäglichen kleinen Erdbeben zeigen können, wann eine Verwerfung still vorbereitet wird, ein viel größeres Ereignis zu erzeugen. Indem sie fortschrittliche Mustererkennungsverfahren auf Erdbebenkataloge anwenden, prüfen die Forschenden, ob es möglich ist, einen echten „Anlauf“ zu großen Beben zu erkennen — und zugleich festzustellen, wann eine solche Warnung nicht vorhanden ist.
Der Verwerfung zuhören durch viele kleine Beben
Große Erdbeben treten meist nicht völlig überraschend auf. Vor einer größeren Bruchbildung erleben Verwerfungen oft Veränderungen wie Vorbeben, Schwärme kleiner Beben oder langsame Kriechbewegungen. Diese Vorbereitungsphasen variieren jedoch stark von Ort zu Ort und fehlen in manchen Fällen offenbar ganz. Die Autorinnen und Autoren sammeln detaillierte Kataloge kleiner und mäßiger Erdbeben aus fünf gut untersuchten Regionen, darunter das Kahramanmaraş-Erdbeben 2023 in Türkiye, das L’Aquila-Beben 2009 in Italien und das Iquique-Megathrust-Ereignis 2014 in Chile. Für jede Region untersuchen sie Jahre der Seismizität vor dem Hauptbeben und suchen nach Mustern, die auf eine bevorstehende Versagensbereitschaft der Verwerfung hinweisen könnten.
Von Rohkatalogen zu Familien verwandter Ereignisse
Statt jedes Erdbeben als isolierten Punkt zu behandeln, gruppiert das Team Ereignisse in „Familien“, die räumlich, zeitlich und in der Magnitude nahe beieinanderliegen. Jede Familie enthält ein Hauptbeben (das größte Ereignis) sowie zugehörige Vor- und Nachbeben. Um jedes Ereignis herum berechnen die Forschenden dutzende beschreibender Kennwerte: wie schnell Beben auftreten, wie eng sie in Raum und Zeit gehäuft sind, wie viel Spannung sie freisetzen und wie die Größenverteilung der Beben aussieht. Diese auf Ereignisebene erfassten Messwerte werden innerhalb jeder Familie gemittelt und mit einfachen Beschreibungen der internen Struktur der Familie kombiniert (zum Beispiel, ob sie eher wie eine klassische Nachbebenfolge oder wie ein diffuser Schwarm aussieht). Das Ergebnis ist ein kompaktes Fingerabdruckprofil für jede Familie, das das Verhalten des lokalen Verwerfungssegments einfängt. 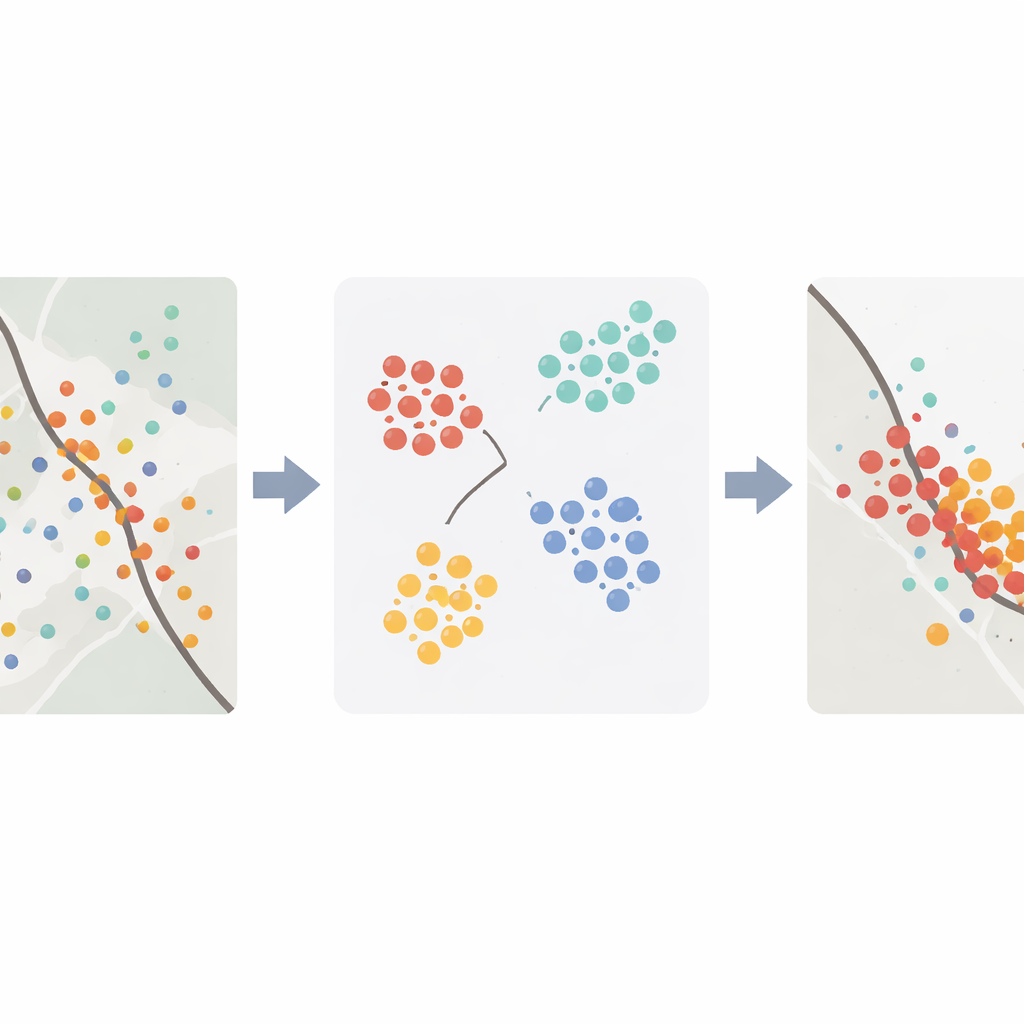
Die Daten sich selbst ordnen lassen
Statt dem Computer im Vorhinein vorzugeben, wie ein „Warnmuster“ aussehen muss, verwenden die Autorinnen und Autoren unüberwachtes maschinelles Lernen. Konkret wenden sie einen k‑means-Algorithmus an, der Erdbebenfamilien automatisch in Kategorien mit ähnlichen Fingerabdrücken sortiert. Diese Kategorien reichen von stabilerem Verhalten — Ereignisse, die über Zeit und Raum verteilt sind und wenig Spannung freisetzen — bis zu kritischerem Verhalten, gekennzeichnet durch enge Clusterbildung, starke Wechselwirkungen zwischen Ereignissen und konzentrierte Spannungsfreisetzung. Entscheidend ist, dass der Algorithmus nicht weiß, wann das große Erdbeben stattfindet; er gruppiert Familien ausschließlich nach ihren Merkmalen. Die Forschenden untersuchen anschließend, wann und wo die am stärksten „kritischen“ Kategorien im Verhältnis zu den späteren Hauptbeben auftreten.
Wo die Verwerfung sich wirklich aufheizt — und wo nicht
Für drei Erdbeben, die bekanntermaßen klare Vorbereitungsphasen hatten — Kahramanmaraş, L’Aquila und Iquique — identifiziert die Methode erfolgreich langlebige, stark lokalisierte Familien, die kurz vor dem Hauptbeben auftreten und sich von früherer Aktivität abheben. In diesen Fällen sind die kritischen Kategorien mit dichten Ereignisclustern, schrumpfenden räumlichen Ausdehnungen und erhöhter Spannungsfreisetzung verbunden, was zu einem Bild passt, in dem ein Verwerfungssegment vor dem Versagen Spannung und Schäden fokussiert. Im Gegensatz dazu findet der Ablauf bei zwei anderen Ereignissen — dem Amatrice-Beben 2016 in Italien und dem Noto-Beben 2024 in Japan — keine eindeutig kritische Familie, die bis zum Hauptbeben anhält. Amatrice scheint von relativer Ruhe vorhergegangen zu sein, Noto hingegen von komplexer Schwarmaktivität und Fluidprozessen, was nahelegt, dass nicht alle großen Erdbeben eine klare seismische Vorwarnung im Katalog zeigen. 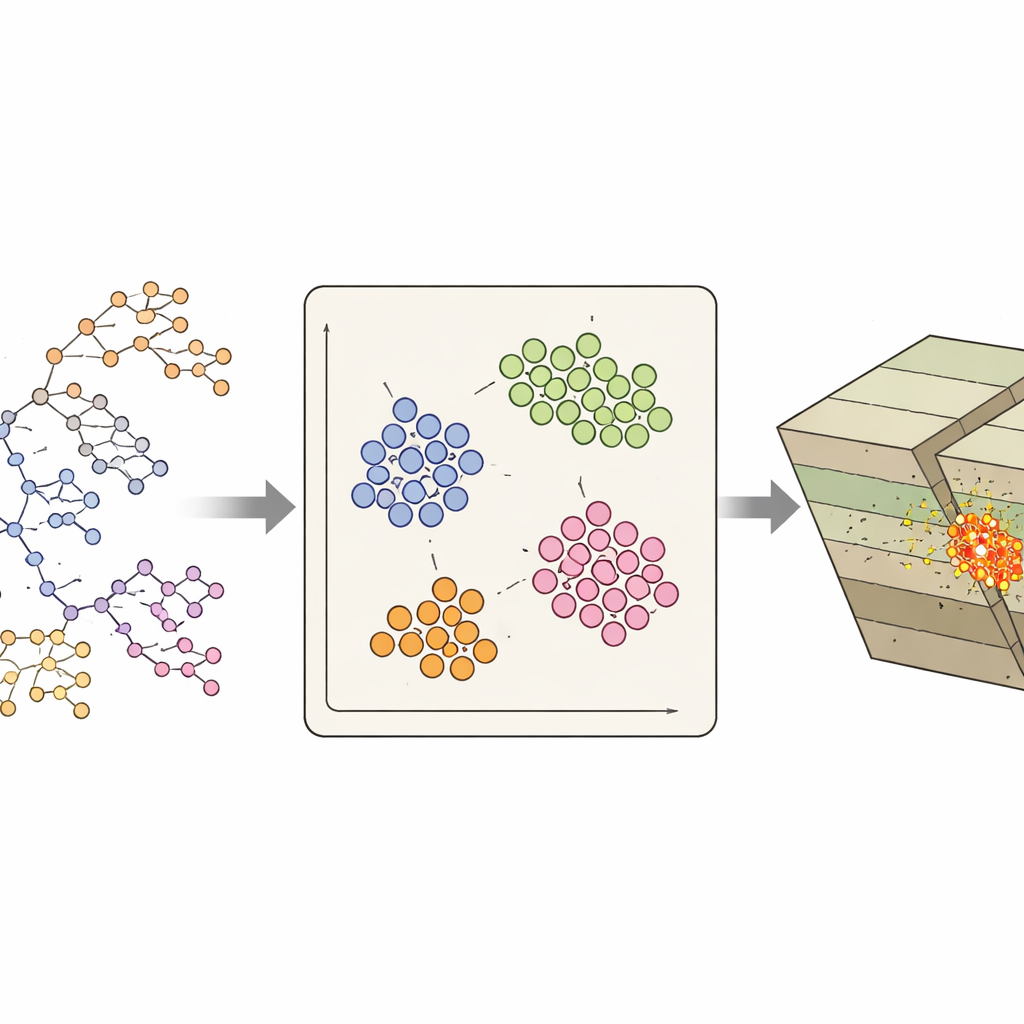
Auf dem Weg zu praktisch nutzbaren Vorinformationen, mit Vorsicht
Abschließend prüfen die Autorinnen und Autoren, ob ihr Ansatz in etwas näher an Echtzeit funktionieren könnte. Sie trainieren ihre Kategorisierung an einem früheren Datenzeitraum und schieben dann das Fenster durch den Katalog, um zu sehen, wann eine neue, unterscheidbare Kategorie auftaucht. In den drei Fällen mit bekannten Vorbereitungsphasen tritt eine deutliche Änderung im Clustering-Maß Wochen bis Monate vor dem großen Beben auf, was auf einen möglichen Nutzen für operative Erdbebenvorhersage hinweist. Die Studie betont jedoch wichtige Grenzen: Die Methode kann nur Vorbereitungsphasen entdecken, die tatsächlich nachweisbare Seismizität erzeugen, sie ist auf hochwertige Kataloge angewiesen und erfordert fachliche Interpretation, um zu beurteilen, ob eine neu auftauchende Kategorie wirklich kritisch ist. Kurz gesagt, dieses Rahmenwerk „sagt“ Erdbeben nicht voraus, bietet aber einen physikalisch fundierten Weg, um hervorzuheben, wann und wo kleine Beben darauf hindeuten könnten, dass eine Verwerfung in einen gefährlicheren Zustand übergeht.
Zitation: Karimpouli, S., Martínez-Garzón, P., Núñez-Jara, S. et al. Preparatory phase of large earthquakes illuminated by unsupervised categorization of earthquake catalog features. Nat Commun 17, 4024 (2026). https://doi.org/10.1038/s41467-026-72279-x
Schlüsselwörter: Erdbebenvorhersage, Seismizitätsmuster, Maschinelles Lernen, Vorbeben, Störungsmechanik