Clear Sky Science · de
Präzise und schnelle ereignisbasierte Formvermessung von Szenen mit gemischter Reflexion
Glatte und matte Welten gemeinsam sehen
Von der Gesichtserkennung im Smartphone bis zu Fabrikrobotern verlassen sich viele Geräte heute auf Kameras, die Tiefe wahrnehmen, nicht nur Farbe. In der Praxis geraten diese Systeme jedoch oft ins Stocken, weil stumpfe Wände, glänzende Kunststoffe und spiegelnde Metalle nebeneinander existieren. Diese Arbeit stellt eine neue Methode vor, um die 3D-Form solcher gemischten Szenen schnell und mit hoher Genauigkeit zu erfassen, indem eine spezielle „ereignisbasierte“ Kamera und ein abtastender Laser eingesetzt werden, sodass selbst glänzende und sich bewegende Objekte detailliert vermessen werden können.
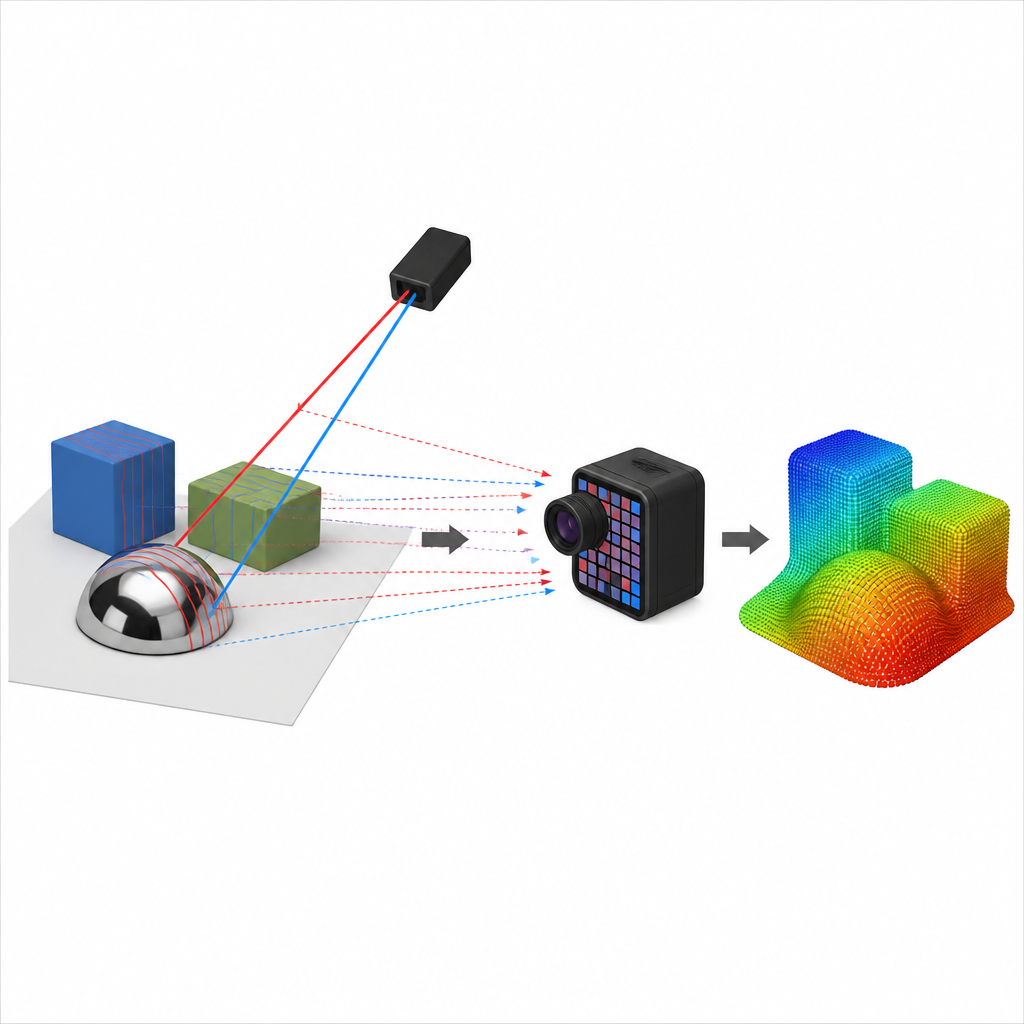
Warum glänzende Dinge so schwer zu messen sind
Die meisten 3D-Kameras sind für einen Oberflächentyp zugleich ausgelegt. Verfahren, die Muster projizieren und deren Verformung beobachten, funktionieren gut bei matten Objekten, weil das Licht in viele Richtungen gestreut wird und für die Kamera leicht zu erkennen ist. Bei Spiegeln und poliertem Metall versagen sie jedoch, weil das Licht nur in einer Richtung wie eine Billardkugel auf dem Tisch reflektiert wird. Umgekehrt haben Methoden, die bei Spiegeln gut funktionieren — etwa Deflektometrie mit einem großen Display als bekanntem Lichtquellengerät — Schwierigkeiten mit teilweise glänzenden Objekten und erfordern sperrige, sorgfältig kalibrierte Aufbauten. Reale Szenen wie Fahrzeuginnenräume oder Wohnzimmer mischen all diese Oberflächentypen, was heutige Systeme langsam, zerbrechlich oder unvollständig macht.
Ereigniskameras und abtastende Strahlen
Die Autoren bauen ein kompaktes System aus nur zwei Komponenten: einer ereignisbasierten Kamera und einem Laser, der dünne Linien über die Szene fegt. Im Gegensatz zu einer normalen Kamera, die zu festen Zeiten vollständige Bilder aufnimmt, meldet eine Ereigniskamera nur die Pixel, bei denen sich die Helligkeit ändert — und das mit Mikrosekunden-Genauigkeit. Während horizontale und vertikale Laserlinien die Szene abtasten, zeichnet die Kamera einen präzisen Strom von „Ereignissen“ auf, die anzeigen, wo und wann das Licht vorbeigegangen ist. Durch die Kombination dieser Fegvorgänge kann das System die Tiefe in matten Bereichen mittels Triangulation erschließen, ähnlich wie strukturierte-Licht-Scanner, jedoch schneller und mit besserer Toleranz gegenüber Blendung und wechselnder Raumbeleuchtung.
Jede Wand als virtuelle Anzeige nutzen
Die Schlüsselidee der Arbeit besteht darin, die gemessenen matten Teile der Szene als eine Art virtuelle Anzeige für die Analyse glänzender Objekte wiederzuverwenden. Zuerst rekonstruiert das System die Geometrie aller diffusen Flächen mithilfe der direkten Laserreflexionen. Diese Flächen fungieren dann als Lichtquellen: Wenn der Laser sie trifft, streuen sie Licht zu benachbarten Spiegeln und glänzenden Objekten, die dieses Licht wiederum in die Ereigniskamera zurückwerfen. Durch den Vergleich der Zeitpunkte und Geometrien dieser Zwei-Fach-Reflexionspfade mit den zuvor aus den matten Flächen gewonnenen Informationen kann die Methode die Neigungen und Formen spekularer Objekte schätzen, ohne eine physische Anzeige zu benötigen. Effektiv wird so „alles um einen herum zu einer Anzeige“, und die Abdeckung von glänzenden Flächen lässt sich einfach durch Hinzufügen oder Verschieben gewöhnlicher diffuser Objekte erhöhen.
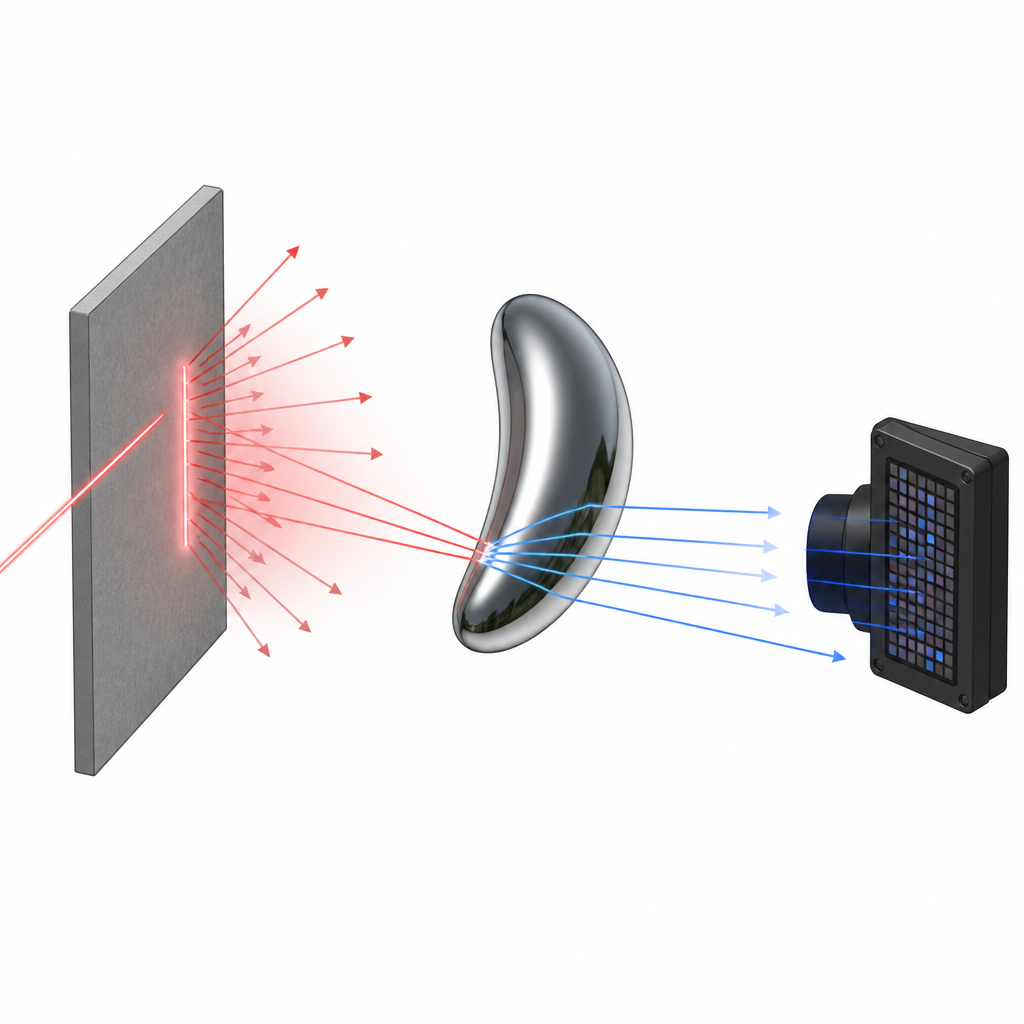
Die vielen Wege des Lichts auseinanderhalten
Damit das funktioniert, muss das System verschiedene Lichtwege trennen, die im Ereignisstrom zusammenmischen. Die Autoren nutzen geometrische Regeln, bekannt als Epipolarbedingungen, um zu entscheiden, ob ein detektiertes Ereignis wahrscheinlich von einer Einfachreflexion stammt, die sich zur Triangulation eignet, von einem Zwei-Fach-Pfad, der für die Rekonstruktion spekularer Formen nützlich ist, oder von einem komplexeren Mehrfachreflexions- oder Subsurface-Pfad, der verworfen werden sollte. Sie entwerfen außerdem ein Optimierungsverfahren, das die Form glänzender Objekte verfeinert, sodass die abgeleiteten Oberflächennormalen mit den beobachteten Lichtdirektionen übereinstimmen. Tests mit Kugeln, Spiegeln, Ballons und glänzenden Spielzeugen zeigen, dass die Tiefenfehler sowohl auf matten als auch auf spekularen Flächen unter 0,6 Millimetern bleiben und dass das System für gemischte Szenen bei etwa 14 3D-Bildern pro Sekunde arbeiten kann und für rein diffuse Szenen bis zu 250 Bilder pro Sekunde erreicht.
Was das für zukünftige 3D-Kameras bedeutet
Dieser Ansatz weist auf eine neue Klasse von Tiefensensoren hin, die mit einem einzigen kompakten Gerät unordentliche, reflektierende und sogar bewegte Umgebungen bewältigen können. Durch die Kombination ereignisbasierter Erfassung mit geschicktem Laserabtasten und durch die Behandlung der umgebenden Wände und Objekte als virtuelle Anzeigen überbrückt die Methode eine lange bestehende Lücke zwischen Technologien, die entweder für matte oder für spiegelähnliche Oberflächen optimiert sind. Zwar gibt es noch Grenzen — etwa die Abhängigkeit von etwas diffusem Material in der Szene und der Umgang mit seltenen komplexen Reflexionen —, doch die Ergebnisse deuten auf praktikable Wege zu verlässlicherer 3D-Vision in Anwendungen von AR- und VR-Headsets bis hin zur robotischen Inspektion glänzender Industrieteile.
Zitation: Dashpute, A., Wang, J., Taylor, J. et al. Accurate and fast event-based shape measurement of mixed reflectance scenes. Nat Commun 17, 4407 (2026). https://doi.org/10.1038/s41467-026-72254-6
Schlüsselwörter: 3D-Bildgebung, ereignisbasierte Kamera, gemischte Reflexion, spekulare Oberflächen, strukturiertes Licht