Clear Sky Science · zh
通过多模态文本到图像生成框架提升基础模型在罕见眼病诊断中的表现
为什么智能眼部成像很重要
许多导致失明的眼病都很罕见,这使得医生和计算机难以做到早期识别。本研究提出了一种从简短文本描述生成逼真眼部图像的新方法,帮助人工智能系统从临床中很少见到的病况中学习。该方法旨在提高自动化眼部筛查对常见和罕见视网膜疾病的准确性与公平性,从而惠及全球各地的患者。
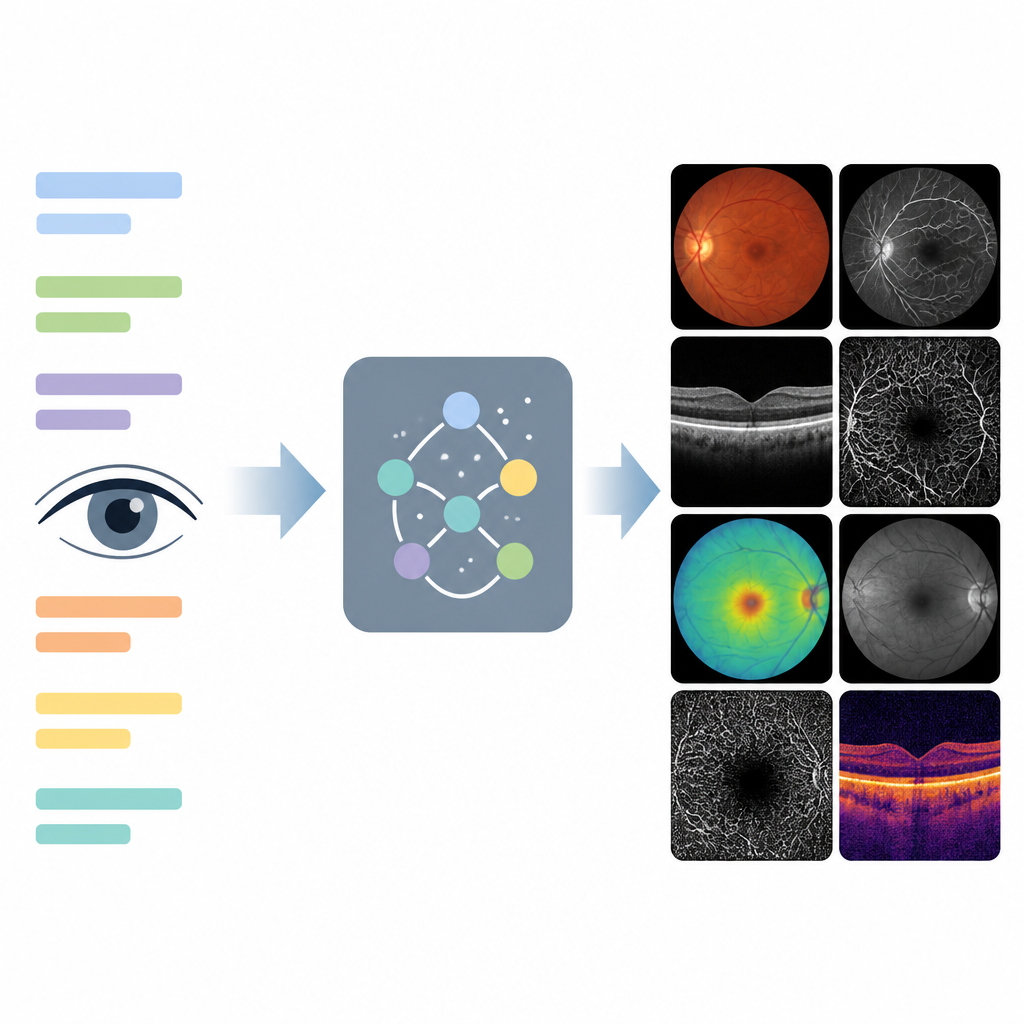
将文字转换为逼真的眼部图像
研究人员构建了名为 EyeDiff 的系统,能够根据简短书面提示生成眼底及相关扫描的详细图像。这些提示描述了成像方式(如彩色照片或横断面扫描)、疾病类型及其严重程度。EyeDiff 在超过四万张图像上进行训练,覆盖 14 种成像类型和 80 多类疾病。通过学习不同设备和视角下各疾病的典型表现,模型能生成在保留关键病变特征的同时匹配所请求成像风格的合成图像。
检验合成图像是否像真实图像一样
为测试 EyeDiff 是否遵循文本指令,团队使用了自动化工具来评分图像与描述的一致性。在涉及常见视网膜疾病、糖尿病性改变、青光眼及若干罕见病的任务中,得分都很高,表明提示与生成图像之间对齐良好。随后,两位眼科医生参与了一项图灵风格测试,他们需要判断每张图像是真实还是合成。医生在大多数情况下能正确识别真实图像,但约有三分之二的合成图像被误判为真实,说明这些合成图像对受过训练的专家也具有说服力。当要求对 50 张合成图像与其文本提示的一致性进行评分时,两位评分者给出了低误差分并表现出高度一致性。
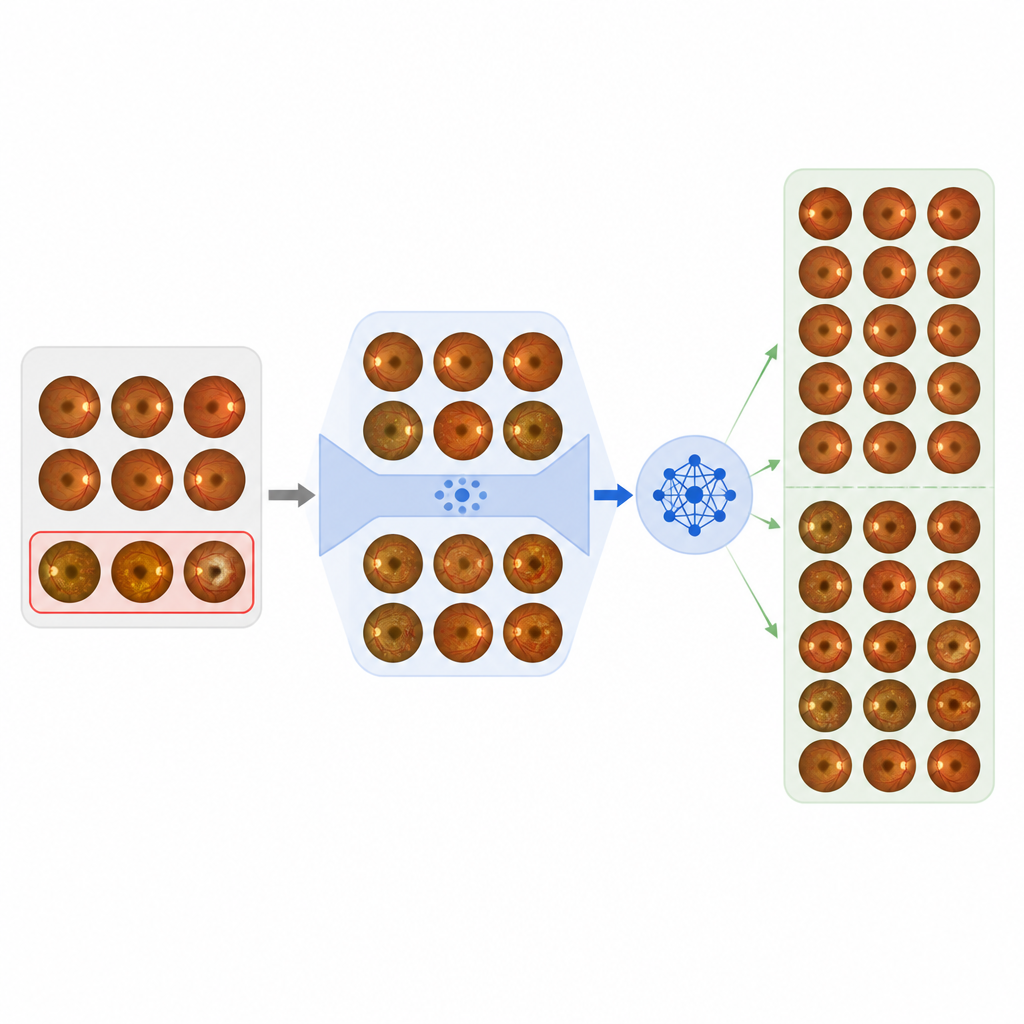
帮助计算机更好地识别罕见问题
EyeDiff 的主要目标不仅是生成好看的图像,而是增强那些在罕见表现上表现欠佳的诊断模型。在许多真实世界的数据集中,某些疾病类型仅有极少数病例,这会使模型偏向常见病种。作者将 EyeDiff 生成的图像补充到来自不同国家和成像设备的 11 个数据集中这些代表性不足的类别中。然后他们对若干领先的眼科基础诊断模型进行了再训练,包括专用于单一扫描类型的系统以及结合图像与文本的模型。在糖尿病视网膜病变分级、青光眼分期、多疾病分类和罕见病识别等任务中,加入合成图像相比仅使用真实数据或简单重采样技巧,持续改进了关键性能指标。
临床使用的益处与保障
EyeDiff 对某些特定罕见疾病(如 Stargardt 病、早产儿视网膜病变和视网膜母细胞瘤)表现出显著价值,在这些病种中增加训练样本数量显著提高了检测准确率。作者指出,所有生成的图像均未经过挑选即被使用,但仍带来了益处,这表明该方法在实践中具有鲁棒性。同时,他们强调需要谨慎。合成图像可能包含细微伪影或反映训练数据中的偏差,因此应明确标注、谨慎监测并防止滥用。扩大源数据的多样性并设计用于检测或量化伪影的工具是重要的后续工作。
这对未来眼保健意味着什么
简单来说,EyeDiff 像一个智能图像工厂,能够按需快速提供常见和极罕见眼病的逼真示例。通过填补真实患者数据稀缺的空白,它帮助诊断算法在不暴露更多隐私信息的前提下变得更敏感且更平衡。尽管仍需进一步提高图像保真度并确保安全部署,但这项研究表明,文本驱动的合成成像有望成为构建早期检测致盲性视网膜疾病的可靠工具的重要助力。
引用: Chen, R., Zhang, W., Liu, B. et al. Boosting foundation models for rare eye disease diagnosis via a multimodal text-to-image generative framework. npj Digit. Med. 9, 371 (2026). https://doi.org/10.1038/s41746-026-02560-2
关键词: 视网膜成像, 生成式人工智能, 罕见眼病, 医学数据增强, 眼科