Clear Sky Science · zh
用于实时暴力检测与警报生成的嵌入式深度学习框架
为何更聪明的摄像头关系到日常安全
街道、学校和公共交通中的打斗与袭击往往在几秒钟内发生,远早于人工操作者能扫描所有监控画面并呼救的时间。本研究提出了一种方法,让体积小、成本低的计算设备——例如像树莓派这样的板子——能够实时观看视频并自动标记可能的暴力行为。通过将强大的视频分析技术压缩到高效的本地系统中,这项工作展示了现有摄像头如何在不用依赖远端数据中心或持续人工监控的情况下,成为更迅速、更可靠的守望者。
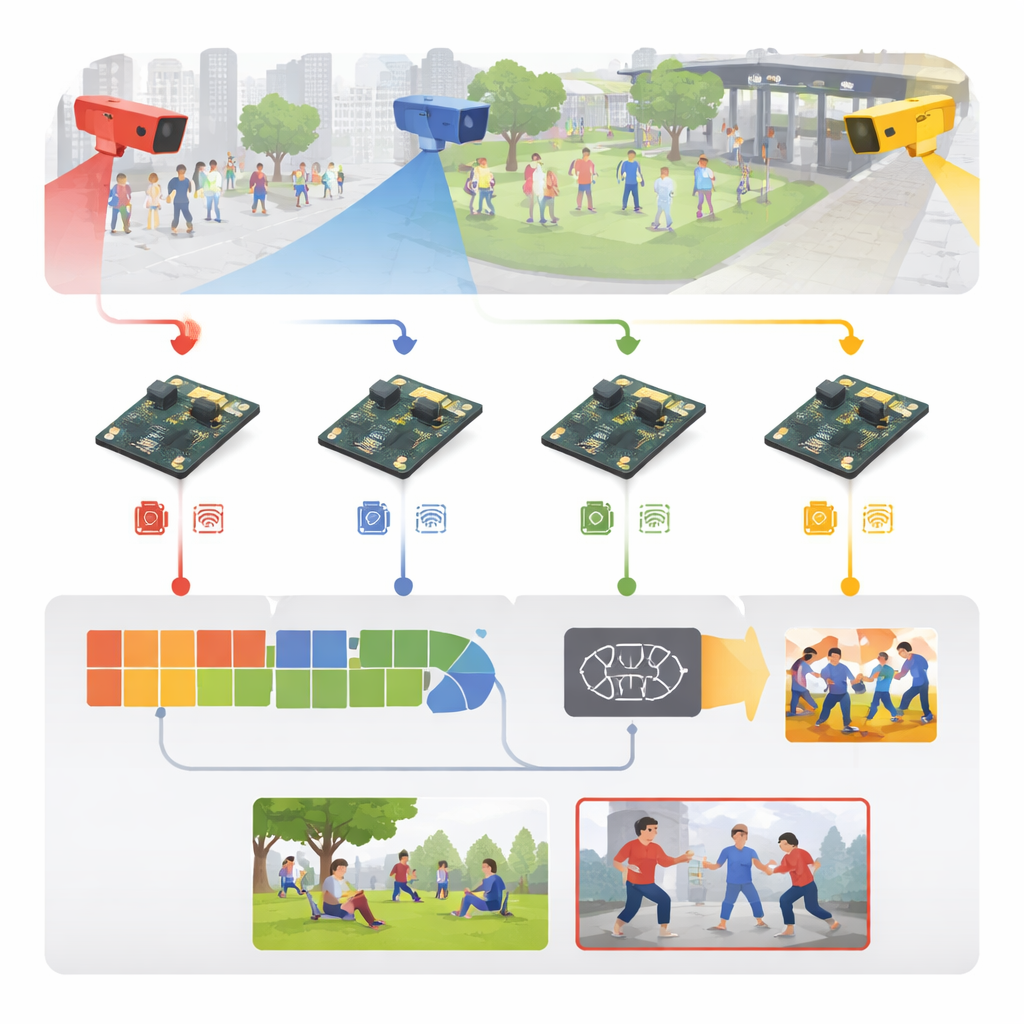
把原始视频转化为早期预警信号
系统从体育场、人行道、校园通道和室内走廊等处的普通监控视频开始。每个摄像头并不把所有视频流回中央服务器,而是将帧直接发送到附近的嵌入式板上。在那里,输入帧会被标准化——在训练阶段进行缩放、去噪,并通过翻转、旋转和亮度变化等轻度变换来增强——以便模型学会应对不同光照、视角和人群密度。作者还构建了丰富的训练素材:五个知名的公开数据集外加一个新的六类集合,包含拳打、脚踢、武器相关攻击、群体暴力、奔跑和正常互动。
盒内紧凑“大脑”的工作原理
系统的核心是一个精简的两阶段学习引擎。首先,一个轻量的图像模块扫描每一帧以寻找关键视觉线索——人体轮廓、手臂和腿部姿态以及运动边缘——采用来自手机视觉模型的节省计算的卷积操作。接着第二个模块在短序列帧上进行观察,理解这些线索随时间的变化,从而捕捉例如友好拍打与拳击之间的差别。这通过一种高效的递归结构实现,该结构能记忆近期运动而无需像更庞大的视频网络那样的高计算负担。一个简单的最终层把这种时空理解转化为六类活动标签之一,将普通动作与可能的攻击区分开来。
把深度学习塞进小型低功耗板子
设计巧妙的模型只是故事的一半;让它在掌心大小的计算机上高速运行才是真正的挑战。作者把整个系统当作工程流水线来处理:先在高性能图形工作站上训练一个版本,然后将其转换为便携格式并进行大幅压缩。数值精度被降低,使得权重只占原来内存的四分之一,网络中不必要的部分被剪枝掉。借助离线的专用优化工具,他们生成了一个调优模型,能在树莓派上通过优化运行时高效执行。结果是系统每秒处理约26帧视频,每帧约38毫秒延迟,同时仅耗费几瓦电力——足够快速且节能,适合在现场持续运行。

测试、信任与机器判断的局限
为了检验他们的紧凑监测器是否既准确又可靠,研究人员对其进行了多项测试。在从冰球场到城市街道的基准集合以及他们自己的六类数据集上,系统大约能在100个案例中正确标注97个,并在捕捉暴力行为与避免误报之间表现出较好的平衡。与更复杂的视频模型——例如完整的3D卷积网络和基于变换器的设计——的比较显示,这种更精简的方法在使用远少计算量的情况下可以匹配或超越它们的精度。团队还可视化了模型在每帧中“注视”的区域,发现其注意力自然集中在移动的四肢和近距离接触处,而非无关的背景细节,这有助于增强对其决策的信心。
对更安全、更智能空间的意义
该研究的主要信息并不是宣称发明了一种全新的神经网络,而是展示了如何将成熟技术打包成适用于朴素硬件的实用实时工具。通过在模型设计、数据准备和部署时的压缩之间谨慎权衡,作者交付了一个可以监控实时视频、识别可能暴力并以低延迟与低能耗发出警报的嵌入式系统。他们也承认存在的开放性挑战:在光线差、拥挤场景或快速类似运动的情况下系统仍可能出错,且任何此类技术的部署都必须注意隐私、偏见与人工监督。尽管如此,这项工作指向这样一个未来:许多普通摄像头将配备小巧、安静的计算设备,帮助更早发现危险并支持更迅速、更明智的响应。
引用: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
关键词: 暴力检测, 嵌入式视觉, 边缘人工智能, 视频监控, 深度学习