Clear Sky Science · pt
Uma estrutura de deep learning embarcada para detecção de violência em tempo real e geração de alertas
Por que câmeras mais inteligentes importam para a segurança cotidiana
Brigas e agressões em ruas, escolas e transportes públicos frequentemente acontecem em segundos, muito antes que operadores humanos consigam monitorar todas as telas de vigilância e chamar ajuda. Este estudo apresenta uma forma de pequenos computadores de baixo custo — dispositivos tão modestos quanto uma placa Raspberry Pi — observarem vídeo em tempo real e sinalizarem automaticamente comportamentos provavelmente violentos. Ao comprimir técnicas poderosas de análise de vídeo em um sistema eficiente e embarcado, o trabalho demonstra como câmeras existentes poderiam se tornar sentinelas mais rápidas e confiáveis sem depender de centros de dados remotos ou de atenção humana constante.
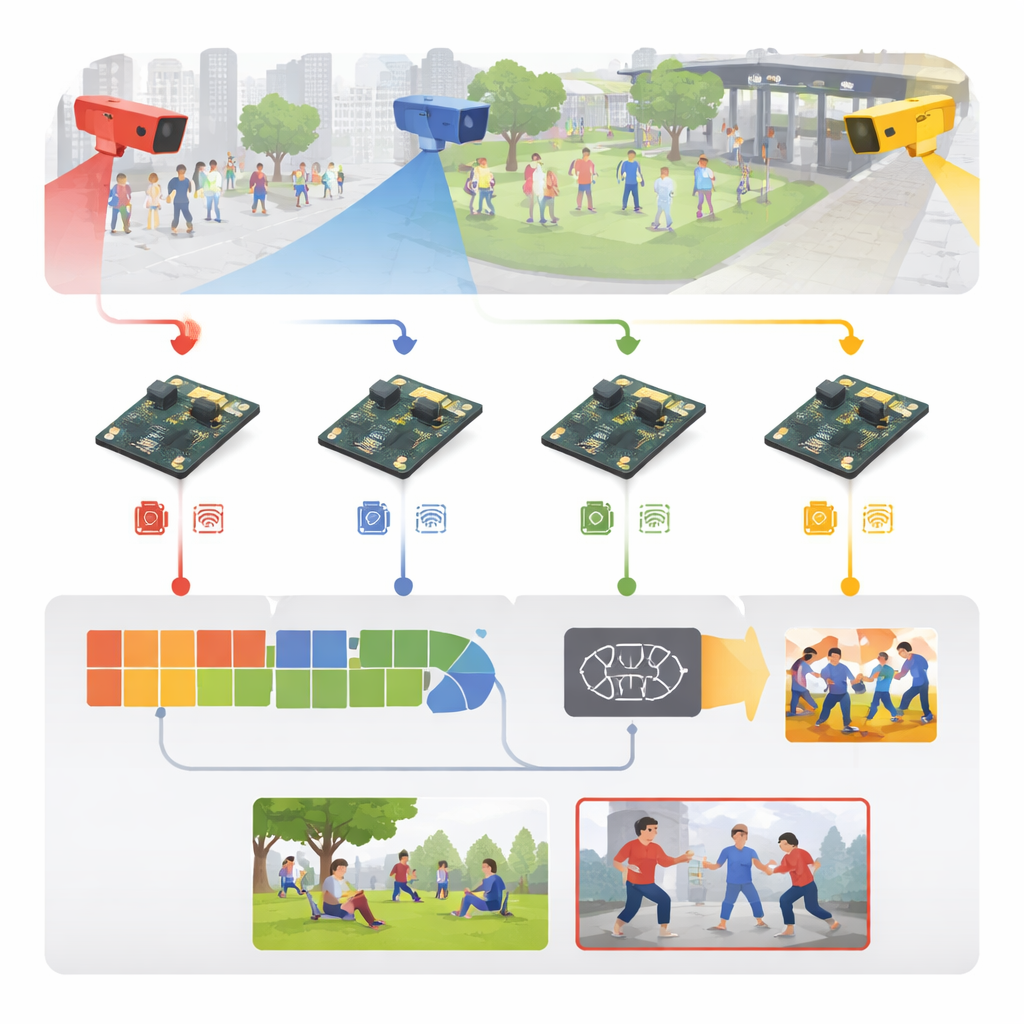
Transformando vídeo bruto em sinais de alerta precoce
O sistema parte de imagens de vigilância comuns, de locais como arenas esportivas, calçadas, caminhos de campus e corredores internos. Em vez de transmitir todo esse vídeo para um servidor central, cada câmera envia seus quadros diretamente a uma placa embarcada próxima. Lá, os quadros recebidos são padronizados — redimensionados, limpos e levemente alterados com flip, rotações e mudanças de brilho durante o treinamento — para que o modelo aprenda a lidar com diferentes iluminações, pontos de vista e densidades de público. Os autores também constroem uma mistura rica de material de treinamento: cinco conjuntos públicos bem conhecidos mais uma nova coleção de seis categorias que inclui socos, chutes, ataques com armas, violência em multidões, corrida e interação normal.
Como o cérebro compacto dentro da caixa funciona
No coração do sistema está um motor de aprendizado simplificado em duas etapas. Primeiro, um módulo de imagem leve escaneia cada quadro em busca de pistas visuais reveladoras — contornos do corpo, posições de braços e pernas e bordas de movimento — usando operações convolucionais econômicas emprestadas de modelos de visão para celulares. Depois, um segundo módulo analisa uma curta sequência de quadros para entender como essas pistas mudam ao longo do tempo, capturando a diferença entre, por exemplo, um toque amistoso e um soco. Isso é feito com uma estrutura recorrente eficiente que lembra movimentos recentes sem a carga computacional pesada de redes de vídeo mais volumosas. Uma camada final simples transforma esse entendimento espaço-temporal em uma das seis etiquetas de atividade, separando movimentos ordinários de agressões prováveis.
Encaixando deep learning em uma placa pequena e de baixo consumo
Projetar um modelo inteligente é só metade da história; fazê‑lo rodar rápido em um computador do tamanho da palma da mão é o verdadeiro desafio. Os autores tratam o sistema inteiro como um pipeline de engenharia: começam com uma versão treinada em uma estação de trabalho com GPU potente, depois a convertem para um formato portátil e a encolhem agressivamente. A precisão numérica é reduzida para que os pesos ocupem um quarto da memória original, e partes desnecessárias da rede são podadas. Usando ferramentas de otimização especializadas fora do dispositivo, eles geram um modelo ajustado que pode ser executado de forma eficiente no Raspberry Pi usando um runtime otimizado. O resultado é um sistema que processa cerca de 26 quadros de vídeo por segundo com aproximadamente 38 milissegundos de latência por quadro, tudo consumindo apenas alguns watts — rápido e econômico o suficiente para operação contínua em campo.

Testes, confiança e limites do julgamento da máquina
Para avaliar se seu observador compacto é ao mesmo tempo preciso e confiável, os pesquisadores o submeteram a uma bateria de testes. Em coleções de referência que vão de rinques de hóquei a ruas da cidade, e em seu próprio conjunto de seis classes, o sistema rotulou corretamente os eventos em cerca de 97 de cada 100 casos e mostrou forte equilíbrio entre detectar atos violentos e evitar alarmes falsos. Comparações com modelos de vídeo mais elaborados — como redes convolucionais 3‑D completas e arquiteturas baseadas em transformers — mostraram que essa abordagem mais enxuta pode igualar ou superar sua exatidão enquanto usa muito menos cálculo. A equipe também visualizou onde o modelo “olha” dentro de cada quadro, verificando que sua atenção naturalmente se concentra em membros em movimento e contatos próximos entre pessoas, em vez de detalhes irrelevantes do fundo, o que ajuda a aumentar a confiança em suas decisões.
O que isso significa para ambientes mais seguros e inteligentes
A principal mensagem do estudo não é que ele tenha inventado um tipo totalmente novo de rede neural, mas que demonstrou como empacotar técnicas comprovadas em uma ferramenta prática de tempo real para hardware modesto. Ao equilibrar cuidadosamente o design do modelo, a preparação dos dados e a compressão em tempo de implantação, os autores entregam um sistema embarcado capaz de monitorar vídeo ao vivo, reconhecer violência provável e emitir alertas com baixa latência e baixo consumo de energia. Eles também reconhecem desafios em aberto: o sistema ainda pode ser prejudicado por iluminação ruim, cenas muito lotadas ou movimentos rápidos semelhantes a esportes, e qualquer tecnologia desse tipo deve ser implantada com atenção à privacidade, viés e supervisão humana. Ainda assim, o trabalho aponta para um futuro em que muitas câmeras comuns sejam pareadas com pequenos computadores discretos que ajudam a detectar perigos mais cedo e a apoiar respostas mais rápidas e bem informadas.
Citação: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Palavras-chave: detecção de violência, visão embarcada, edge AI, vigilância por vídeo, deep learning