Clear Sky Science · zh
在可调整套索中预测未知修饰变量的监督学习
为什么隐藏影响对预测很重要
从识别信用卡欺诈到预测疾病风险,计算机现在在日常生活的许多方面承担预测任务。但现实世界的数据通常很杂乱:相同的输入,例如年龄或温度,可能会根据隐藏的情境(如性别、时间段或实验条件)而产生不同的作用。本文探讨了当这些“不可见”影响在历史数据中已知但在新样本中缺失时,如何处理它们,并展示了将不同机器学习工具结合起来如何能得到既准确又更易解释的预测。
将输入、隐藏情境与结果联系起来
研究聚焦于一种强大的回归方法——可调整套索(pliable lasso)。简单来说,这种方法在用许多特征(例如年龄或蛋白质水平)预测结果(如血压)的同时,允许另一组“修饰”变量去弯曲或重塑这些关系。例如,运动对血压的影响可能因性别而异。可调整套索旨在捕捉这些依赖情境的效应,同时自动防止模型变得不必要地复杂。它通过偏好简单模式,除非数据明确支持更复杂的交互,来实现这一点。
处理缺失情境的三种方式
作者描述了修饰变量的三种常见情况。在最简单的“已知—已知”情形中,修饰变量在训练和未来数据中都被记录,因此可调整套索可以拟合一次后直接应用。在更具挑战性的“已知—未知”情形中,修饰变量仅在训练数据中可得,必须为新观测估计。在最难的“未知—未知”情形中,修饰变量从未被观测,只能通过间接方法近似,例如对相似个体进行聚类。本文聚焦于中间且在实践中很重要的情况:修饰变量在历史数据中已知,但在新数据中必须先预测出来,才能让可调整套索使用它们。

并列测试多种学习方法
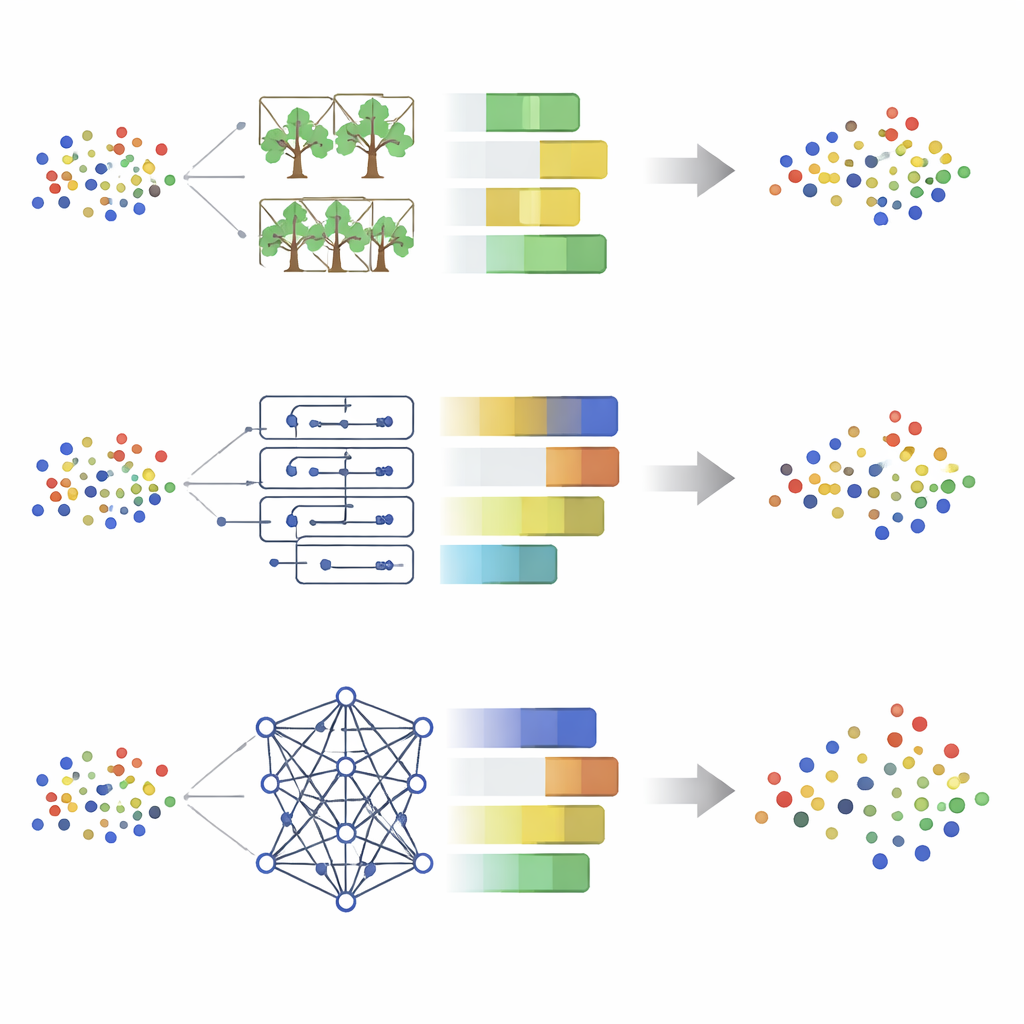
为了估计缺失的修饰变量,作者系统比较了八种监督学习算法,包括随机森林、XGBoost、决策树、支持向量机、k近邻、人工神经网络、Lasso 和弹性网(Elastic Net)。他们同时评估两个步骤:首先,各方法对修饰变量本身的分类能力如何;其次,将这些估计的修饰变量插入可调整套索后,整体管线对最终结果的预测性能如何。测试既涵盖精心设计的模拟数据,也包括两个真实数据集:小鼠大脑的蛋白表达和超导材料的性质。为了避免过于乐观的结论和训练/测试集之间的信息泄漏,研究采用了严格的交叉验证和仔细的超参数调优。
什么方法最有效及其原因
结果揭示了一个有趣的张力。基于树的集成方法(如 XGBoost、随机森林和单棵决策树)在对隐藏修饰变量进行分类方面表现优异,常常接近完美。然而,当这些修饰变量估计结果被输入可调整套索后,它们并不总是带来最好的最终结果预测。相反,像 Lasso 和弹性网这样的更简单且带正则化的线性模型往往产生更准确且更稳定的结果预测,即便它们对修饰变量的分类稍逊。作者认为,这种现象的原因在于基于树的方法可能产生非常“尖锐”但有时错误的修饰标签,扭曲了可调整套索中微妙的交互结构;而正则化的线性方法则给出更平滑、较“软”的估计,更符合模型的假设。
实用的操作建议
对于希望在重要情境因子仅部分观测到的场景中获得强健且可解释预测的从业者,研究推荐一种混合策略。首先,利用强大的基于树的模型来估计缺失的修饰变量,借助它们在发现复杂模式方面的优势。然后,将这些估计的修饰变量与原始特征一起输入可调整套索模型,并在最终回归步骤中最好配合使用 Lasso 或弹性网。这种两阶段方法利用了两者的优点:先灵活地发现隐藏结构,再通过有纪律、透明的模型来预测结果。
引用: Hawrami, Z.S.M., Cengiz, M.A. & Dünder, E. Supervised learning for predicting unknown modifying variables in pliable lasso. Sci Rep 16, 10200 (2026). https://doi.org/10.1038/s41598-026-36854-y
关键词: 可调整套索, 修饰变量, 监督学习, 混合建模, 交互效应