Clear Sky Science · tr
Güvene Duyarlı XAI (TAXAI) çerçevesi: yorumlanabilir ve güvenilir klinik yapay zeka sistemleri için nicel bir model
Neden bilgisayarlar doktorlara yardım ettiğinde güven önemlidir
Hastaneler, taramaları okumak, hastalığı erken tespit etmek ve tedavi seçeneklerini yönlendirmek için yapay zekâya yöneliyor. Ancak birçok doktor ve hasta, tam olarak içini göremedikleri yazılımlara güvenmekte tereddüt ediyor. Bu makale, yalnızca performansını değil, tıbbi yapay zekâ sistemlerine ne kadar güvenmemiz gerektiğini ölçmenin bir yolunu sunuyor. Güveni bir sayıya dönüştürerek klinisyenlerin, düzenleyicilerin ve geliştiricilerin bir yapay zekâ aracının gerçek bakımda kullanıma uygun ve yeterince güvenilir olup olmadığına karar vermesine yardımcı olmayı hedefliyor.
Siyah kutulardan daha şeffaf gerekçelendirmeye
Modern yapay zekâ sistemleri, tıbbi görüntüleri okumada ve hasta verilerini analiz etmede insan uzmanlarla eşleşebiliyor veya onları geçebiliyor. Ancak bu sistemler genellikle siyah kutu gibi davranır; tahminde bulunurlar ama açık bir açıklama sunmazlar. Mevcut açıklama araçları bir röntgende ısı haritası çizebilir veya hangi laboratuvar değerlerinin kararı etkilediğini listeleyebilir, fakat bu açıklamaların güvenilir, adil veya zaman içinde stabil olup olmadığını nadiren belirtirler. Yazarlar, bir modelin nasıl davrandığını göstermek tek başına tanı ve kanser evrelemesi gibi yüksek riskli ortamlarda yeterli olmadığını; açıklamaların kendisine de güvenilebileceğine dair kanıt gerektiğini savunuyorlar.
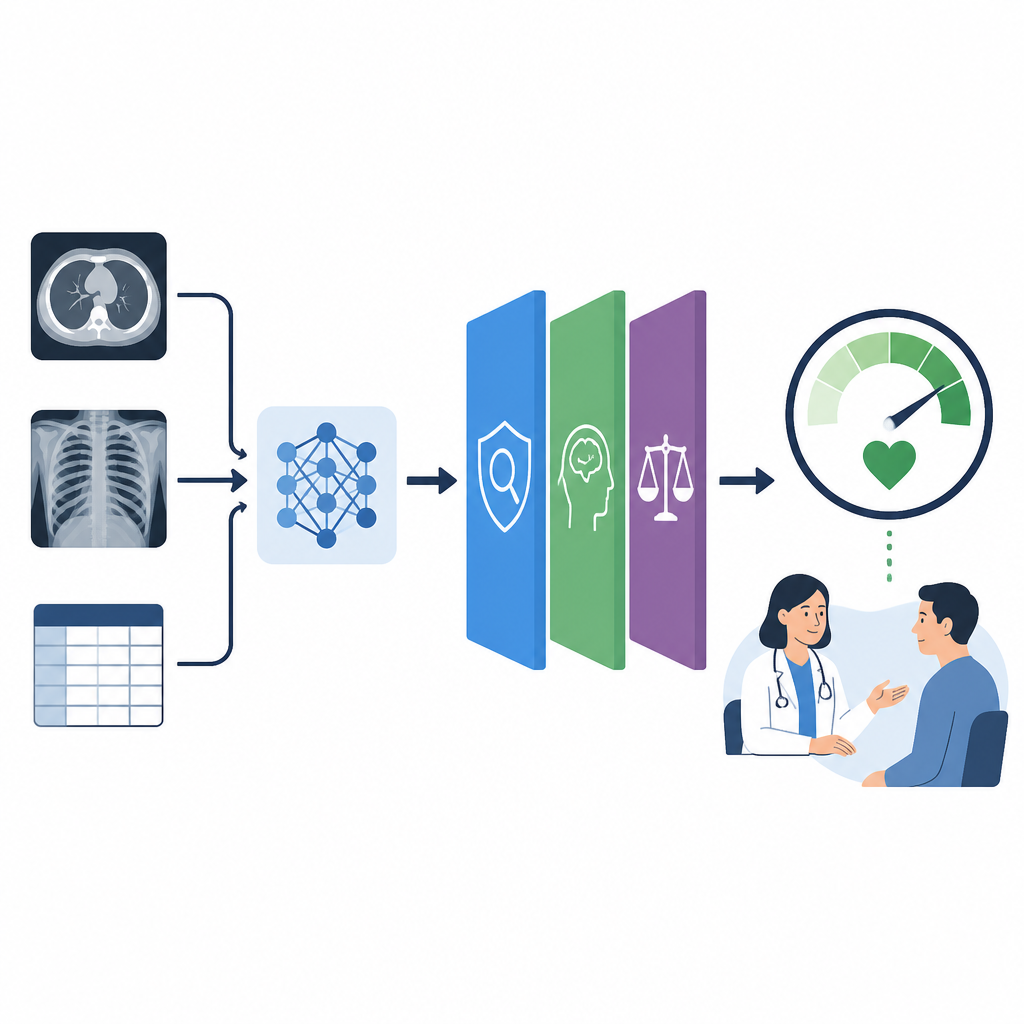
Güvenilir bir tıbbi yapay zekânın üç direği
Çalışma, güveni üç direğin birleşimi olarak ele alan Güvene Duyarlı XAI (TAXAI) çerçevesini öneriyor. Birinci direk bağlılık (fidelity) olup, bir açıklamanın altta yatan modelin gerçekte ne yaptığını ne kadar yakından yansıttığını ifade eder. İkinci direk yorumlanabilirlik uyumu; vurgulanan bölgelerin veya özelliklerin bir vakayı değerlendirirken klinisyenlerin nasıl düşündüğüyle örtüşüp örtüşmediğini kontrol eder. Üçüncü direk ise uyumluluk ve güvenilirlik olup, hasta grupları arasındaki adalet, küçük değişikliklere karşı sonuçların kararlılığı ve farklı çalıştırmalar ve merkezler arasında bulguların yeniden üretilebilirliğini içerir. Bu direklerin her biri sıfır ile bir arasında bir ölçekte değerlendirilir, böylece karşılaştırılabilir ve birleştirilebilir hale gelirler.
Güveni tek ve net bir puana dönüştürmek
TAXAI bu üç bileşeni birleştirerek sıfır ile bir arasında bir Güven İndeksi üretir. Bu indeks, her direğe atanan ağırlıklarla hesaplanır ve farklı ortamlara göre ayarlanabilir. Örneğin, modelin erken geliştirme aşamasında teknik doğruluğa daha fazla ağırlık verilebilirken, düzenleyiciler adalet ve güvenilirliği ön plana çıkarmayı tercih edebilir. Yazarlar, formüllerinin Güven İndeksinin belirgin sınırlar içinde kaldığını, herhangi bir bileşen iyileştiğinde veya kötüleştiğinde öngörülebilir şekilde yanıt verdiğini ve seçilen ağırlıkların küçük değişimlerine karşı kararlı kaldığını kanıtlıyorlar. Bu, farklı modeller, veri kümeleri ve açıklama yöntemleri arasında güven seviyelerini karşılaştırmayı kolaylaştırır.
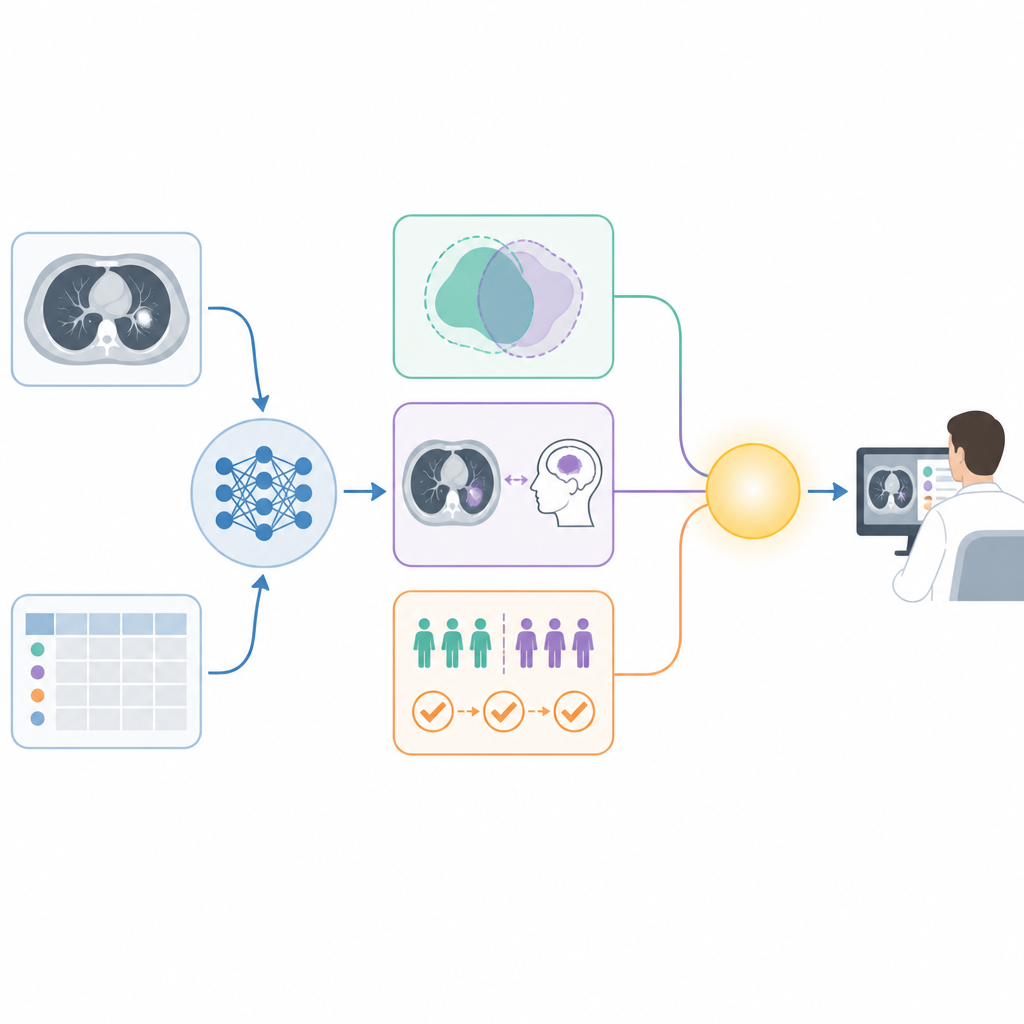
Çerçeveyi çeşitli tıbbi görevlerde test etmek
TAXAI’nin pratikte nasıl çalıştığını göstermek için yazarlar onu birkaç yaygın tıbbi yapay zekâ problemine uyguluyor. Bunlar arasında BT taramalarından akciğer kanserini tespit etme, zatürre ve COVID için göğüs röntgenlerini okuma, histoloji görüntülerinde akciğer dokusunu derecelendirme, tablosal test sonuçlarından meme kanserini sınıflandırma, MR görüntülerinde beyin tümörlerini saptama ve klinik kayıtlardan diyabet riskini tahmin etme yer alıyor. Her görev için SHAP, LIME ve Grad-CAM gibi bilinen açıklama araçları standart makine ve derin öğrenme modellerine ekleniyor. Daha sonra bağlılık, yorumlanabilirlik uyumu ve uyumluluk puanları hesaplanıp Güven İndeksi değerlerine dönüştürülüyor. Bu ayarlarda Güven İndeksi genellikle 0,85 ile 0,94 arasında yer alıyor; bu da çerçevenin tutarsız veya veri kümesine özgü davranışlar yerine sürekli, yorumlanabilir güven puanları ürettiğini gösteriyor.
Algoritmaları etik ve politika ile bağlamak
Çalışma ayrıca TAXAI’yi tıbbi düzenleme bağlamına yerleştiriyor. Avrupa Birliği gibi bölgelerdeki yeni kurallar ve ABD Gıda ve İlaç Dairesi gibi kurumların rehberlikleri, hasta bakımını etkileyen yapay zekâ için şeffaflık, adalet ve sürekli denetim talep ediyor. TAXAI, mevcut modellerin ve açıklama araçlarının çıktısını denetimler, dokümantasyon ve klinik yönetişime beslenebilecek güven sinyallerine dönüştüren bir katman olarak sunuluyor. Yazarlar TAXAI’nin mevcut açıklayıcı yöntemlerin yerini almaya çalışmadığını; bunun yerine bir açıklanabilir sistemin tıbbi yazılım olarak kullanıma ne kadar hazır olduğunu değerlendirmek için yapılandırılmış bir yol sağladığını vurguluyorlar.
Bu, klinikteki gelecekteki yapay zekâ için ne anlama geliyor
Basitçe söylemek gerekirse, bu makale tıbbi yapay zekâya olan güvenin doğruluk veya hız gibi diğer ölçülebilir nitelikler gibi ele alınabileceğini gösteriyor. Güveni teknik, insani ve etik parçalara ayırıp bunları net bir indekste yeniden birleştirerek TAXAI, hastaneler ve düzenleyiciler için sistemleri karşılaştırmak üzere ortak bir ölçüt sunuyor. Mevcut çalışma canlı klinik denemelerden ziyade hesaplamalı testlere odaklansa da, bu yaklaşım güven panoları ve klinisyenin sürece dahil olduğu çalışmalara zemin hazırlıyor. Benimsendiği takdirde, bu tür bir yaklaşım tıbbi yapay zekâyı etkileyici gösterilerden, doktorların ve hastaların daha rahat güvenebileceği güvenilir, iyi yönetişimli araçlara taşımaya yardımcı olabilir.
Atıf: Pal, M., Saha, H.N. & Chakrabarti, A. The Trust-Aware XAI (TAXAI) framework: a quantitative model for interpretable and reliable clinical AI systems. Sci Rep 16, 15455 (2026). https://doi.org/10.1038/s41598-026-44167-3
Anahtar kelimeler: tıbbi yapay zekâda güven, açıklanabilir yapay zekâ sağlık, klinik karar desteği, yapay zekâ adaleti ve güvenilirliği, Güven İndeksi çerçevesi