Clear Sky Science · sv
En inbyggd djupinlärningsram för realtidsdetektion av våld och generering av varningar
Varför smartare kameror spelar roll för vardaglig säkerhet
Brott och övergrepp på gator, i skolor och i kollektivtrafik utvecklas ofta på sekunder, långt innan mänskliga operatörer hinner skanna varje övervakningsskärm och kalla på hjälp. Denna studie presenterar ett sätt för små, lågkostnadsdatorer — enheter så blygsamma som ett Raspberry Pi‑kort — att bevaka video i realtid och automatiskt flagga sannolik våldsamt beteende. Genom att pressa kraftfulla videoföranstaltningar in i ett effektivt system på enheten visar arbetet hur befintliga kameror kan bli snabbare och mer pålitliga väktare utan att vara beroende av avlägsna datacenter eller ständig mänsklig uppmärksamhet.
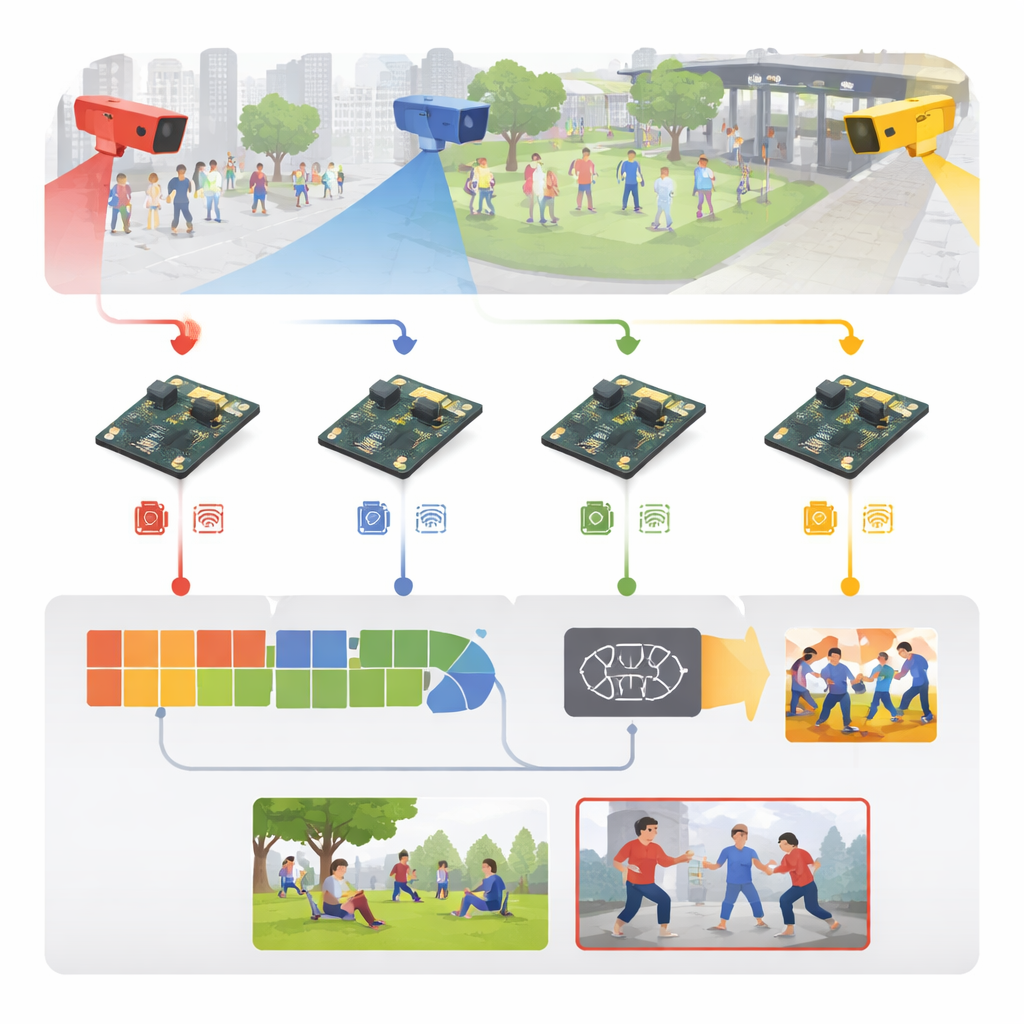
Att omvandla rå video till tidiga varningssignaler
Systemet börjar med vanlig övervakningsfilm från platser som idrottsarenor, trottoarer, campusgångar och inomhuskorridorer. Istället för att strömma all denna video till en central server skickar varje kamera sina bildrutor direkt till ett närliggande inbyggt kort. Där standardiseras inkommande rutor — ändras i storlek, rengörs och lätt modifieras med speglingar, rotationer och ljusstyrkeändringar under träning — så att modellen lär sig hantera olika belysning, synvinklar och folksamlingstätheter. Författarna bygger också en rik blandning av träningsmaterial: fem välkända offentliga datamängder plus en ny sexkategorisamling som inkluderar slag, sparkar, vapenrelaterade attacker, massvåld, flykt/utrinningsbeteende och normal interaktion.
Hur den kompakta hjärnan i lådan fungerar
I hjärtat av systemet finns en strömlinjeformad tvåstegsinlärningsmotor. Först skannar en lättviktsbildmodul varje ruta efter talande visuella ledtrådar — kroppskonturer, arm‑ och benpositioner samt rörelsekanter — med kostnadsbesparande konvolutionsoperationer lånade från mobilvisionsmodeller. Därefter betraktar en andra modul en kort sekvens rutor för att förstå hur dessa ledtrådar förändras över tid, vilket fångar skillnaden mellan till exempel en vänlig knuff och ett slag. Detta görs med en effektiv rekurrent struktur som kommer ihåg nylig rörelse utan den tunga beräkningsbördan från större videonätverk. Ett enkelt slutlager omvandlar denna spatio‑temporala förståelse till en av sex aktivitetsklasser och skiljer vardagliga rörelser från sannolik aggression.
Att få djupinlärning att rymmas i ett litet, lågströmkort
Att designa en klipsk modell är bara halva historien; att få den att köras snabbt på en handflatesstor dator är den verkliga utmaningen. Författarna behandlar hela systemet som en ingenjörspipeline: de börjar med en version tränad på en kraftfull grafikarbetsstation, konverterar den sedan till ett portabelt format och krymper den aggressivt. Numerisk precision reduceras så att viktvärden upptar en fjärdedel av det ursprungliga minnet, och onödiga delar av nätverket beskärs bort. Genom att använda specialiserade optimeringsverktyg utanför enheten genererar de en finjusterad modell som kan köras effektivt på Raspberry Pi med en optimerad runtime. Resultatet är ett system som bearbetar omkring 26 videorutor per sekund med ungefär 38 millisekunders fördröjning per ruta, allt medan det drar endast några watt — tillräckligt snabbt och sparsamt för kontinuerlig drift i fält.

Testning, förtroende och gränser för maskinellt omdöme
För att avgöra om deras kompakta bevakare är både korrekt och pålitlig utsatte forskarna den för en rad tester. Över benchmarksamlingar från hockeyrinkar till stadsgator, och på deras egen sexklassdatamängd, klassificerade systemet händelser korrekt i ungefär 97 av 100 fall och visade stark balans mellan att fånga våldsamma handlingar och att undvika falsklarm. Jämförelser med mer avancerade videomodeller — såsom fullständiga 3D‑konvolutionsnätverk och transformerbaserade konstruktioner — visade att detta slankare tillvägagångssätt kan matcha eller överträffa deras noggrannhet samtidigt som det använder betydligt mindre beräkningsresurser. Teamet visualiserade också var modellen ”tittar” i varje ruta och fann att dess uppmärksamhet naturligt centrerar på rörliga lemmar och nära kontakter mellan människor snarare än irrelevanta bakgrundsdetaljer, vilket hjälper till att bygga förtroende för dess beslut.
Vad detta betyder för tryggare, smartare miljöer
Studiens huvudbudskap är inte att den uppfunnit en helt ny typ av neuralt nätverk, utan att den visat hur beprövade tekniker kan paketeras till ett praktiskt realtidsverktyg för modest hårdvara. Genom att noggrant balansera modellens utformning, databeredning och kompression vid driftsättning levererar författarna ett inbyggt system som kan övervaka levande video, känna igen sannolikt våld och väcka varningar med låg fördröjning och låg energiförbrukning. De erkänner också öppna utmaningar: systemet kan fortfarande luras av dålig belysning, trånga scener eller snabb sportlik rörelse, och all sådan teknik måste användas med hänsyn till integritet, bias och mänsklig tillsyn. Ändå pekar arbetet mot en framtid där många vanliga kameror paras med små, tysta datorer som hjälper till att upptäcka fara tidigare och stödja snabbare, bättre informerade insatser.
Citering: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Nyckelord: våldsdetektion, inbyggd bildbehandling, edge‑AI, videoövervakning, djupinlärning