Clear Sky Science · sv
En lättvikts flerfallsupptäcktsram för röntgenbilder med övervakad kontrastinlärning
Varför smartare röntgenkontroller spelar roll
Den som har smugit sig igenom flygplatssäkerheten vet att varje väska måste skannas snabbt och noggrant. Röntgenbilder är dock långt ifrån enkla: knivar, flaskor, datorer och laddare ligger ofta ovanpå varandra, och farliga föremål kan lätt gömma sig i röran. Denna artikel presenterar en ny metod inom artificiell intelligens (AI) som hjälper röntgenapparater att upptäcka små eller överlappande hot mer tillförlitligt, samtidigt som den körs tillräckligt snabbt för trafikerade kontrollstationer.
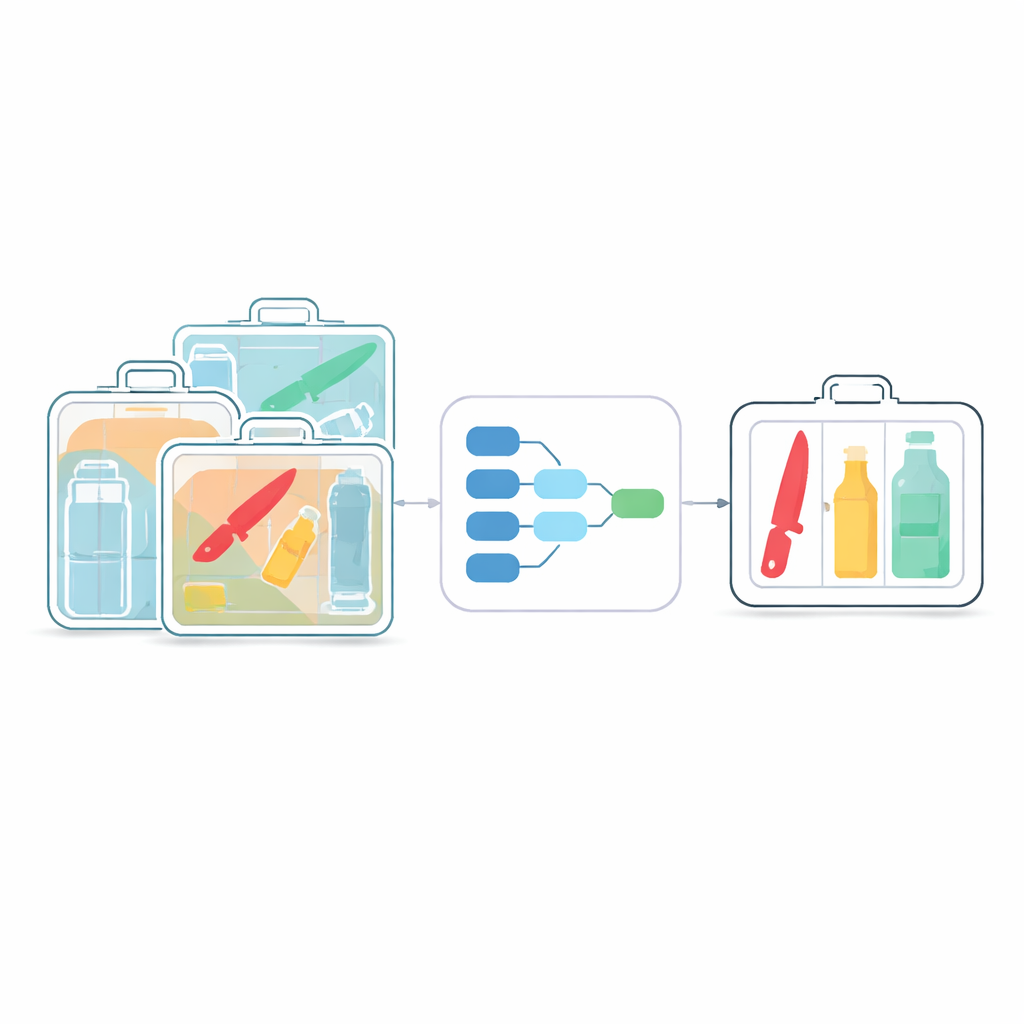
Utmaningen att se genom röran
Röntgensystem för säkerhet utgör första försvarslinjen på flygplatser, tunnelbanestationer och andra trånga offentliga platser. Traditionell manuell granskning är långsam och utmattande, vilket ökar risken för att föremål förbises. Moderna AI-detektorer som YOLO-familjen har förbättrat automatisk screening, men de designades ursprungligen för vardagsfotografier, inte de spöklika, lågkontrastiga röntgenvyerna. I dessa skanningar överlappar föremål ofta, framstår som halvgenomskinliga och varierar kraftigt i storlek. Små blad eller flaskor kan vara begravda bland ofarliga föremål, och många nuvarande algoritmer missar dem eller kräver tung processorkraft som är svår att distribuera på kompakta, lågkostnadsmaskiner.
En slankare hjärna för röntgenmaskiner
Författarna bygger vidare på den populära YOLOv8-detektorn och ritar om den specifikt för röntgenbilder. Deras första steg är att strömlinjeforma nätverket genom att använda "depthwise separable"-konvolutioner — ett tekniskt sätt att säga att modellen söker efter mönster mer sparsamt. Istället för att applicera stora, dyra filter på varje kanal i bilden på en gång, delar den upp operationen i billigare steg. Denna ändring minskar antalet beräkningar med ungefär en fjärdedel till två femtedelar, samtidigt som de fina detaljer som behövs för att upptäcka små, delvis dolda föremål bevaras. Resultatet är en lättare digital "hjärna" som kan köras i realtid på modest hårdvara, till exempel inbyggda processorer i skannrar.
Hjälpa modellen att fokusera på det som betyder något
Att göra nätverket mindre räcker inte; det måste också bli mer selektivt. För detta introducerar forskarna en Channel-Spatial Attention Fusion (CSAF)-modul. En gren av denna modul lär sig vilka typer av visuella funktioner — kanter, former eller materialindikatorer — som är mest informativa i allmänhet, medan en annan gren lär sig var i bilden aktiviteten sker. Istället för att applicera dessa uppmärksamheter i följd behandlar CSAF dem parallellt och smälter sedan samman dem, så att systemet kan beakta både "vad" och "var" samtidigt. Dessa uppmärksamhetsenheter vävs in i en flerskalig design som kombinerar grova och fina vyer av scenen, vilket är särskilt hjälpsamt för att upptäcka små, överlappande föremål i fullpackade väskor.
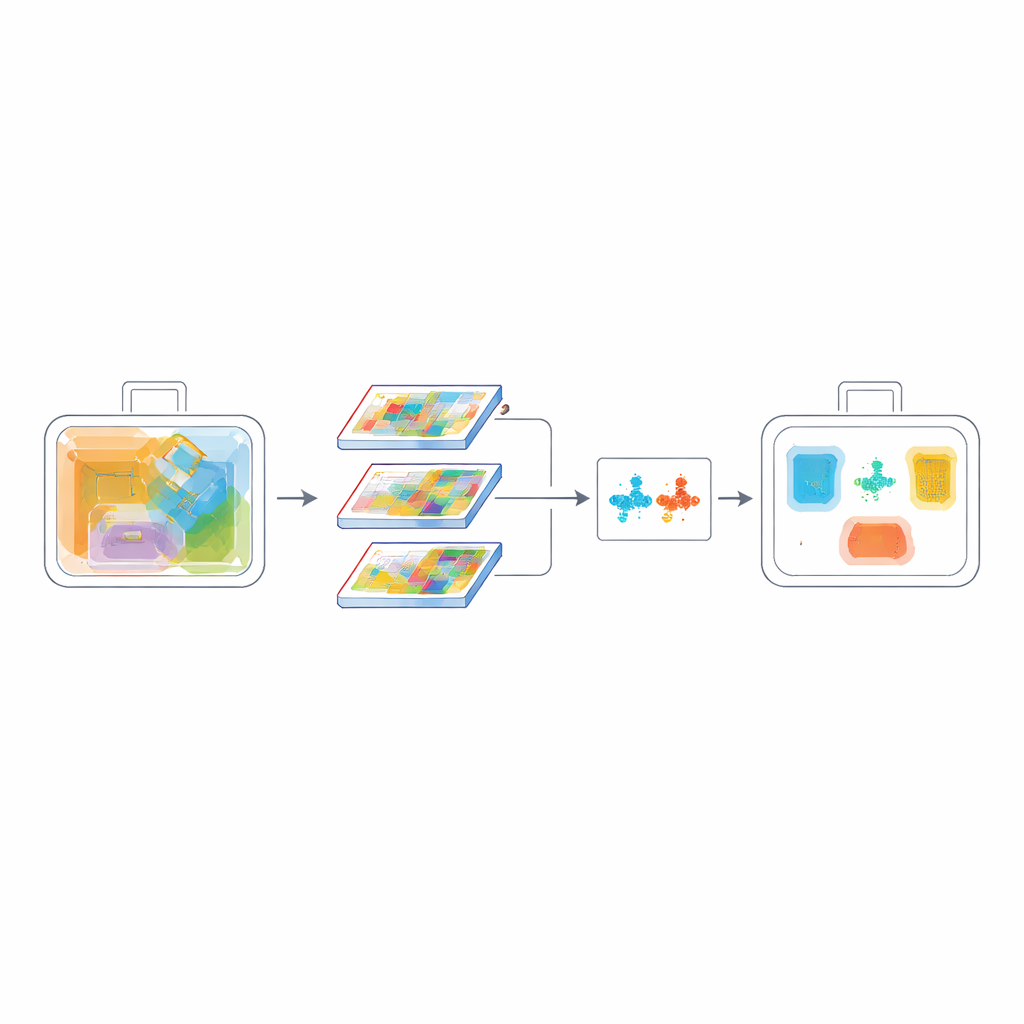
Lära systemet att skilja på liknande utseenden
En annan svårighet i röntgenskanningar är att många föremål ser lika ut: en plåtburk och en sprayflaska, eller olika typer av knivar, kan ha nästan identiska konturer. För att göra modellen bättre på att skilja sådana kategorier åt lägger författarna till ett kontrastivt inlärningsmål. Under träningen uppmuntras nätverket att dra exempel av samma klass närmare varandra i sin interna representation, samtidigt som det skjuter olika klasser längre ifrån varandra. Samtidigt hjälper ett pixel-nivå överlappningsmått kallat PIoU till att finjustera placeringen och formen på de förutsagda begränsningsrutorna, vilket är avgörande när föremål är tilta, trängda eller delvis synliga. Tillsammans lär dessa förluster modellen inte bara var ett föremål är, utan också vad som gör det distinkt från förvirrande grannar.
Bevisa prestanda i realistiska tester
Teamet utvärderar sitt tillvägagångssätt på två krävande röntgendatamängder som inkluderar verkliga kontrollstationer och syntetiska bagagescener med flera hotkategorier. Jämfört med standardbaslinjen YOLOv8 når deras modell högre noggrannhet på strikta överlappningsmått samtidigt som den använder färre parametrar och mindre beräkningskraft. Den upprätthåller mycket höga detektionsnivåer för skarpa föremål och förbättrar igenkänningen av transparenta eller deformbara föremål som flaskor och dryckeskartonger. Precision–konfidens och återkallnings–konfidenskurvor visar att dess förutsägelser förblir stabila även när tröskeln för att förklara en detektion höjs, vilket innebär färre falsklarm och färre missade hot. Tester på en andra datamängd insamlad på annan plats bekräftar att systemet generaliserar väl, ett viktigt krav för verklig implementering där väska innehåll och avbildningsförhållanden varierar.
Vad detta betyder för vardagliga resenärer
För en lekman är slutsatsen att detta arbete erbjuder ett smartare, slankare sätt att skanna bagage. Genom att rita om en modern AI-detektor så att den både är lättviktig och mer diskriminerande möjliggör författarna röntgenmaskiner som kan köras snabbt på prisvärd hårdvara samtidigt som de fångar små, överlappande eller liknande hot. Om sådana metoder antas i praktiken kan de bidra till kortare köer, färre onödiga väskkontroller och—viktigast av allt—förbättrade chanser att verkligt farliga föremål upptäcks innan de når gaten.
Citering: Diao, Q., Chan, W., Zain, A.M. et al. A lightweight multi-scale detection framework for X-ray images with supervised contrastive learning. Sci Rep 16, 8635 (2026). https://doi.org/10.1038/s41598-026-38000-0
Nyckelord: röntgen säkerhet, objektigenkänning, djupinlärning, flygplatskontroll, datorseende