Clear Sky Science · sv
En ny distribuerad gradientalgoritm för sammansatta begränsade optimeringsproblem över riktade nätverk
Smartare beslutsfattande utan en central chef
Moderna teknologier — från elkraftnät och sensornät till drönarflottor — bygger ofta på många enheter som samarbetar utan en enda central kontrollpunkt. Varje enhet ser bara en del av helheten, men hela gruppen måste komma överens om en säker och ändamålsenlig driftspunkt. Denna artikel presenterar ett nytt sätt för sådana distribuerade system att fatta gemensamma beslut effektivt och pålitligt, även när de underliggande kommunikationslänkarna är envägs och problemet innefattar svåra begränsningar och skarpa ”kostnadshörn”.
Varför många små hjärnor slår en stor hjärna
Centraliserad optimering — där en kraftfull dator samlar in all data, löser ett stort problem och skickar tillbaka kommandon — är skört och svårt att skala upp. Det kan sluta fungera om den centrala enheten går ner eller drabbas av stora kommunikationsförseningar i stora system. Distribuerad optimering vänder på detta: varje nod (eller agent) behåller sina egna data, uppdaterar sin lokala beslutspunkt och utbyter endast begränsad information med närliggande grannar. Utmaningen är att konstruera uppdateringsregler så att, trots partiell och envägs kommunikation, alla noder ändå enas om en lösning som är globalt bästa för nätverket.
Svåra problem med skarpa hörn och verkliga begränsningar
Författarna fokuserar på en krävande klass av problem där den totala kostnaden kombinerar släta termer (som förändras mjukt) med icke-släta termer (som kan skapa skarpa kinks), till exempel den välkända l1-normen. Dessa icke-släta delar är centrala för att främja sparsitet och robusthet i tillämpningar som komprimerad sensing, signalavbrusning och modellanpassning. Dessutom måste varje nod uppfylla lokala likhets- och olikhetsbegränsningar och hålla sig inom tillåtna gränser. Allt detta måste hanteras över ett riktat kommunikationsnätverk, där information kan flöda från nod A till nod B men inte nödvändigtvis tillbaka. Befintliga metoder antar ofta oriktade länkar, enklare begränsningar eller fasta steglängder som är svåra att ställa in och mindre flexibla.
Ett nytt sätt för noder att kommunicera och enas
För att hantera dessa svårigheter föreslår artikeln en ny distribuerad gradientbaserad algoritm anpassad för sammansatta, begränsade problem över riktade nätverk. Varje nod justerar upprepade gånger sitt lokala beslut genom ett projicerat gradientsteg: den rör sig i en riktning som minskar den samlade kostnaden och projicerar sedan resultatet tillbaka till sitt tillåtna område så att begränsningarna förblir uppfyllda. Extra variabler fungerar som intern bokföring och hjälper nätverket att upprätthålla likhets- och olikhetsvillkor samt hantera den icke-släta l1-termen. En nyckelinnovation är en korrigeringsmekanism som kompenserar för obalansen som orsakas av envägs länkar, och som använder enbart rad-stokastiska vikter — vilket betyder att varje nod bara behöver veta hur den tar emot information, inte vem som tar emot information från den.
Flexibla steglängder med garanterad konvergens
Ett annat kännetecken för metoden är dess användning av tidsvarierande men konstanta steglängder: varje nod kan välja sin egen steglängd inom ett teoretiskt säkert intervall, istället för att dela en enda fast värde. Denna flexibilitet gör inställningen enklare i praktiken och tillåter algoritmen att bättre anpassa sig till olika lokala förhållanden. Med verktyg från stabilitetsteorin bygger författarna en Lyapunov-funktion — en slags matematisk energimätare — och bevisar att den minskar vid varje iteration, så länge steglängderna respekterar en tydlig övre gräns. Detta garanterar att, från vilken startpunkt som helst, alla noders beslut konvergerar till samma globala optimala lösning, även i närvaro av icke-släta termer och blandade begränsningar.
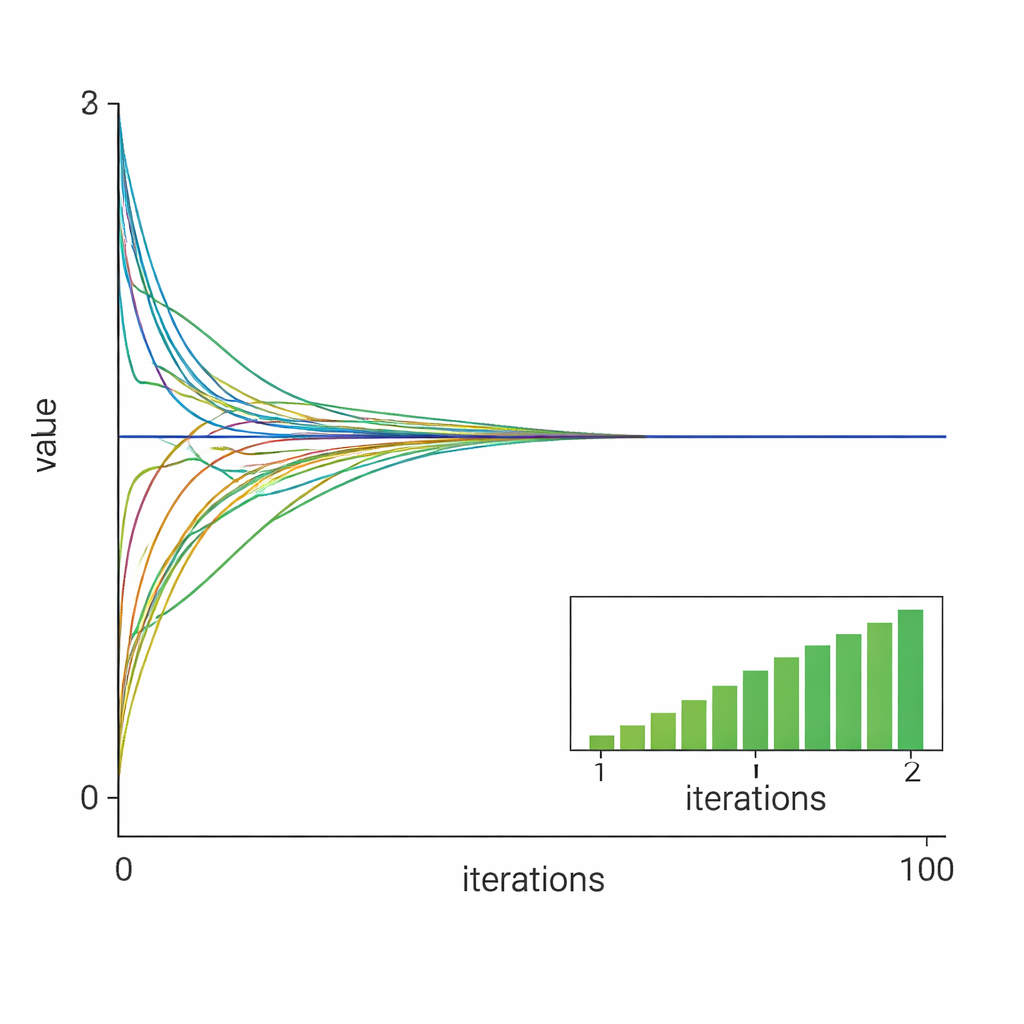
Att pröva metoden i praktiken
Forskarna validerar sin teori med två numeriska fallstudier. I det första löser tio noder gemensamt ett begränsat kvadratiskt problem med l1-regularisering, liknande uppgifter inom resurstilldelning eller sensorfusion. Resultaten visar att alla lokala variabler snabbt anpassar sig till den centraliserade optimala lösningen och att användning av en väl vald konstant steglängd leder till snabbare, nästan linjär konvergens jämfört med en avtagande steglängd. I det andra fallet hanterar metoden ett illa betingat minst absoluta avvikelse-problem, känt för att vara svårt för standardlösare. Även här, med endast fem noder och starkt obalanserade data, styr algoritmen pålitligt alla agenter mot den verkliga lösningen.
Vad detta betyder för verkliga system
Enkelt uttryckt levererar artikeln ett robust recept för grupper av nätverksanslutna enheter att gemensamt lösa svåra optimeringsproblem utan en huvudkontrollant, samtidigt som praktiska begränsningar respekteras och envägs kommunikationslänkar hanteras. Metoden kan tillämpas på kraftsystem, sensornät och distribuerade maskininlärningsuppgifter där begränsningar och sparsitet är viktiga. Eftersom den endast behöver lokal granneinformation och ger tydliga regler för hur man väljer steglängder är den väl lämpad för verkliga implementeringar. Författarna föreslår att metoden kan utvidgas till tidsvarierande nätverk nästa steg, vilket för systemet närmare realistiska, ständigt föränderliga kommunikationsmiljöer.
Citering: Ou, M., Zhang, H., Yan, Z. et al. A novel distributed gradient algorithm for composite constrained optimization over directed network. Sci Rep 16, 5185 (2026). https://doi.org/10.1038/s41598-026-36058-4
Nyckelord: distribuerad optimering, riktade nätverk, flera agenters system, sparse regularisering, begränsade konvexa problem