Clear Sky Science · sv
Funktionsreducering med svärmoptimering och Random Forest‑klassificerare för tidig diabetesriskprediktion
Varför det är viktigt att upptäcka diabetes tidigt
Typ 2‑diabetes smyger ofta in tyst och skadar hjärta, ögon, njurar och nerver lång tid innan den diagnostiseras. Läkare förlitar sig vanligtvis på många frågor och tester för att bedöma någons risk, vilket kan ta tid både för patienter och vårdkliniker. Denna studie undersöker hur smarta datorprogram kan flagga tidig diabetesrisk med bara ett fåtal enkla ja‑/nej‑frågor, vilket potentiellt kan göra screening snabbare, billigare och lättare att använda i trånga eller resurssvaga miljöer. 
En smartare checklista för diabetesrisk
Forskarna arbetade med en verklig datamängd från ett diabetes‑sjukhus i Sylhet, Bangladesh. Var och en av de 520 personerna i datasetet var etiketterad som antingen i tidigt skede av diabetes eller inte. För varje person hade läkare registrerat ålder och 15 enkla kliniska tecken och symtom, såsom frekvent urinering (polyuri), ovanlig törst (polydipsi), plötslig viktnedgång, klåda, suddig syn och fetma. De flesta posterna var enkla ja‑/nej‑svar på ett frågeformulär, vilket gör data liknande det en sjuksköterska eller vårdarbetare kan samla in på några minuter under ett rutinbesök.
Att lära datorn att fokusera på det som spelar störst roll
I stället för att mata in alla 16 uppgifterna i en modell per automatik ställde teamet en nyckelfråga: vilka av dessa egenskaper bär egentligen mest information om diabetesrisk? För att svara på detta kombinerade de en populär maskininlärningsmetod kallad Random Forest med tre "svärmsöknings"‑strategier inspirerade av djurbeteenden: en fox optimizer, en honey badger‑algoritm och tuna swarm optimization. Dessa svärmar beter sig som digitala jägare och söker igenom många möjliga kombinationer av funktioner och modellinställningar för att hitta dem som ger bäst prediktioner med minst möjliga indata. Systemet delade upp data upprepade gånger i tränings‑ och testdelar, finjusterade interna parametrar och röstade fram vilka funktioner och parameterinställningar som fungerade bäst över många körningar.
Hur väl de strömlinjeformade modellerna presterade
De tre resulterande modellerna—namngivna FOX_RF, HBA_RF och TSO_RF—var alla mycket träffsäkra. När de tränades och testades en gång på hela datasetet klassificerade tunabaserade modellen (TSO_RF) varje person korrekt och nådde 100 % noggrannhet, precision och recall. När författarna använde en mer krävande 10‑faldig cross‑validation, som efterliknar testning på osedd data, uppnådde TSO_RF fortfarande en genomsnittlig noggrannhet över 98 %, något bättre än de andra två modellerna och bättre än tidigare publicerade tekniker på samma dataset. Viktigt är att honey badger‑modellen nådde solid prestanda med endast 10 av 16 funktioner, medan de andra modellerna behövde bara 13 eller 14. Denna reducering innebär färre frågor för patienter och lättare beräkningar för framtida appar eller enheter. 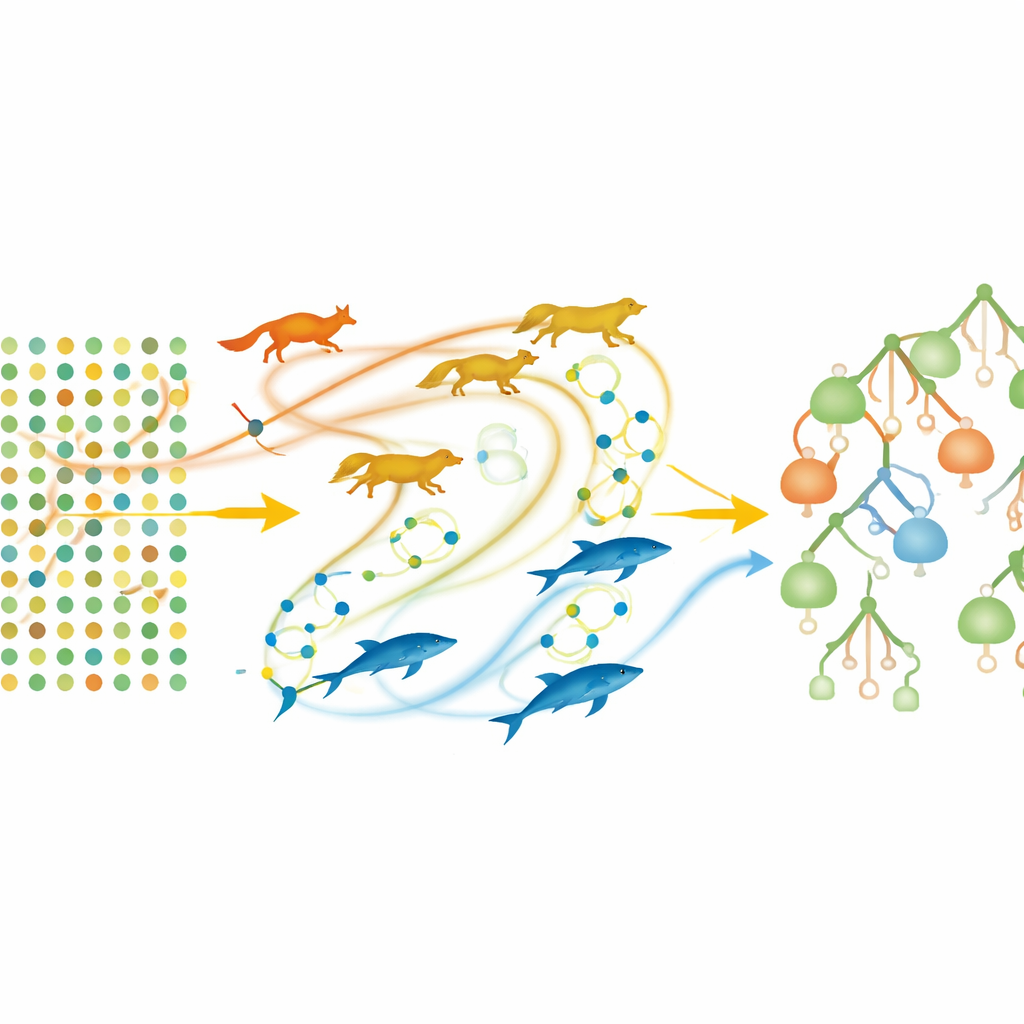
En titt in i den svarta lådan
Moderna prediktionssystem fungerar ofta bra men är svåra att tolka. För att tackla detta använde forskarna en förklarbar AI‑metod kallad SHAP för att mäta hur mycket varje funktion drog modellen mot att förutsäga diabetes eller inte för varje individ. I samtliga tre modeller framträdde samma mönster: frekvent urinering, överdriven törst och kön hade konsekvent störst påverkan på prediktionerna, medan plötslig viktnedgång, muskelstelhet, irritabilitet och några andra tecken spelade stödjande roller. Teamet undersökte också specifika misstag—fall där modellerna felklassificerade personer—och visade att små förändringar i dessa nyckelsymtom ofta vände beslutet, vilket avslöjar var modellerna är mest känsliga och där kliniker bör vara försiktiga.
Vad det betyder för vardaglig vård
Kort sagt visar studien att en noggrant utformad datormodell mycket exakt kan identifiera tidig diabetesrisk med hjälp av en kort, symtombaserad checklista och några demografiska detaljer. Genom att ta bort mindre användbara frågor och lyfta fram de mest talande tecknen—särskilt frekvent urinering, överdriven törst och kön—kan tillvägagångssättet ligga till grund för snabba screeningverktyg i kliniker, samhällsbaserade hälsoprogram eller till och med mobilbaserade system. Även om arbetet fortfarande behöver testas på större och mer mångsidiga populationer pekar det mot en framtid där tidiga diabetesvarningar både är mer precisa och mindre betungande för patienter.
Citering: Sarker, P., Nahid, AA., Choi, K. et al. Feature reduction using swarm optimization and random forest classifiers for early diabetes risk prediction. Sci Rep 16, 14355 (2026). https://doi.org/10.1038/s41598-026-35984-7
Nyckelord: diabetesprediktion, maskininlärning, funktionsurval, svärmoptimering, tidig diagnos