Clear Sky Science · ru
Встроенная система глубокого обучения для обнаружения насилия в реальном времени и генерации оповещений
Почему более умные камеры важны для повседневной безопасности
Драки и нападения на улицах, в школах и общественном транспорте часто разворачиваются за считанные секунды, задолго до того, как оператор успеет просмотреть все экраны видеонаблюдения и вызвать помощь. В этом исследовании предложен подход, который позволяет небольшим, недорогим компьютерам — таким как плата Raspberry Pi — в реальном времени анализировать видеопоток и автоматически помечать вероятные проявления насилия. Упаковывая мощные методы анализа видео в эффективную систему, работа показывает, как существующие камеры могут стать более быстрыми и надежными сторожами, не завися от удалённых дата‑центров и постоянного внимания человека.
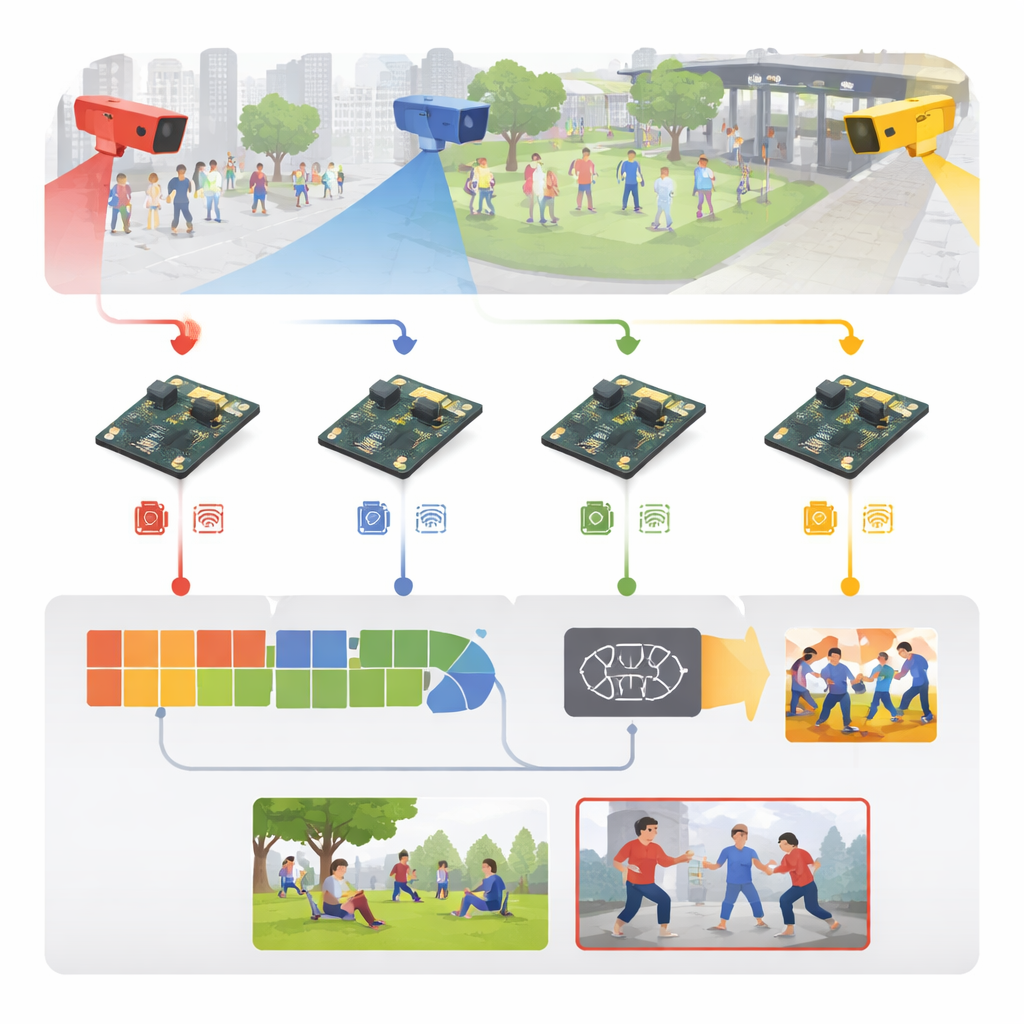
Преобразование «сырых» видеоданных в сигналы раннего предупреждения
Система начинает с обычных записей видеонаблюдения из таких мест, как спортивные арены, тротуары, кампусные дорожки и внутренние коридоры. Вместо того чтобы отправлять весь видеопоток на центральный сервер, каждая камера пересылает кадры на ближайшую встроенную плату. Там входящие кадры стандартизируются — изменяются по размеру, очищаются и в процессе обучения слегка трансформируются (отражения, повороты, изменение яркости), чтобы модель училась работать при разных условиях освещения, точках съёмки и плотности людей. Авторы также сформировали разнообразный набор обучающих данных: пять известных публичных датасетов плюс новая коллекция из шести категорий, включающая удары кулаком, удары ногой, нападения с оружием, массовое насилие, бег и обычное взаимодействие.
Как работает компактный «мозг» внутри устройства
В основе системы — упрощённый двухступенчатый движок обучения. Сначала лёгкий модуль обработки изображений сканирует каждый кадр в поисках значимых визуальных признаков — контуров тел, положений рук и ног, границ движения — используя ресурсоэкономичные сверточные операции, позаимствованные из моделей мобильного зрения. Затем второй модуль анализирует короткую последовательность кадров, чтобы понять, как эти признаки меняются во времени, фиксируя разницу между, например, дружеским прикосновением и ударом. Это реализовано с помощью эффективной рекуррентной структуры, которая запоминает недавние движения без тяжёлой вычислительной нагрузки громоздких видеосетей. Простой финальный слой переводит это пространственно‑временное представление в одну из шести меток активности, отделяя обычные движения от вероятной агрессии.
Встраивание глубокого обучения в маленькую, энергоэффективную плату
Разработка продуманной модели — лишь половина дела; настоящая задача — заставить её быстро работать на компьютере размером с ладонь. Авторы рассматривают всю систему как инженерный конвейер: сначала модель обучается на мощной графической рабочей станции, затем конвертируется в портативный формат и сильно сжимается. Числовая точность снижена так, что веса занимают четверть исходной памяти, а ненужные части сети вырезаются. С помощью специализированных инструментов оптимизации вне устройства генерируют настроенную модель, способную эффективно выполняться на Raspberry Pi с оптимизированным рантаймом. В результате получается система, обрабатывающая примерно 26 кадров в секунду с задержкой около 38 миллисекунд на кадр и потребляющая всего несколько ватт — достаточно быстро и экономично для непрерывной работы в полевых условиях.

Тестирование, доверие и ограничения машинного суждения
Чтобы проверить, насколько компактный наблюдатель точен и надёжен, исследователи провели широкий набор испытаний. На эталонных коллекциях — от хоккейных арен до городских улиц — и на собственном шестиклассовом датасете система правильно маркировала события примерно в 97 из 100 случаев и демонстрировала хорошее равновесие между обнаружением насильственных актов и снижением ложных тревог. Сравнения с более сложными видеомоделями — такими как полные 3‑D сверточные сети и модели на основе трансформеров — показали, что более лёгкий подход может соперничать с ними по точности или превосходить её, потребляя при этом гораздо меньше вычислительных ресурсов. Команда также визуализировала области внимания модели в каждом кадре и обнаружила, что она естественно фокусируется на движущихся конечностях и близких контактах между людьми, а не на несущественных деталях фона, что повышает доверие к её решениям.
Что это значит для более безопасных и умных пространств
Основной вывод исследования не в том, что создан принципиально новая нейросеть, а в том, что показано, как упаковать проверенные методы в практичный инструмент для работы в реальном времени на скромном оборудовании. Тщательно балансируя дизайн модели, подготовку данных и операции сжатия при развёртывании, авторы предлагают встроенную систему, способную мониторить живое видео, распознавать вероятное насилие и генерировать оповещения с малой задержкой и низким энергопотреблением. Они также признают открытые проблемы: система по‑прежнему уязвима к плохому освещению, многолюдным сценам или быстрому спортивному движению, и любая такая технология требует учёта вопросов приватности, смещений и человеческого контроля. Тем не менее работа указывает на будущее, где многие обычные камеры будут сопряжены с небольшими тихими компьютерами, помогающими быстрее заметить опасность и обеспечить более оперативные и взвешенные реакции.
Цитирование: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Ключевые слова: обнаружение насилия, встроенное зрение, edge AI, видеонаблюдение, глубокое обучение