Clear Sky Science · pt
Uma estrutura leve de detecção em múltiplas escalas para imagens de raio‑X com aprendizado contrastivo supervisionado
Por que verificações de raio‑X mais inteligentes importam
Quem já passou pela segurança de aeroportos sabe que cada bagagem precisa ser escaneada com rapidez e precisão. Mas imagens de raio‑X estão longe de ser simples: facas, garrafas, laptops e carregadores se sobrepõem, e itens perigosos podem se ocultar nesse emaranhado. Este artigo apresenta um novo método de inteligência artificial (IA) que ajuda máquinas de raio‑X a identificar ameaças pequenas ou sobrepostas com mais confiabilidade, mantendo velocidade suficiente para pontos de checagem movimentados.
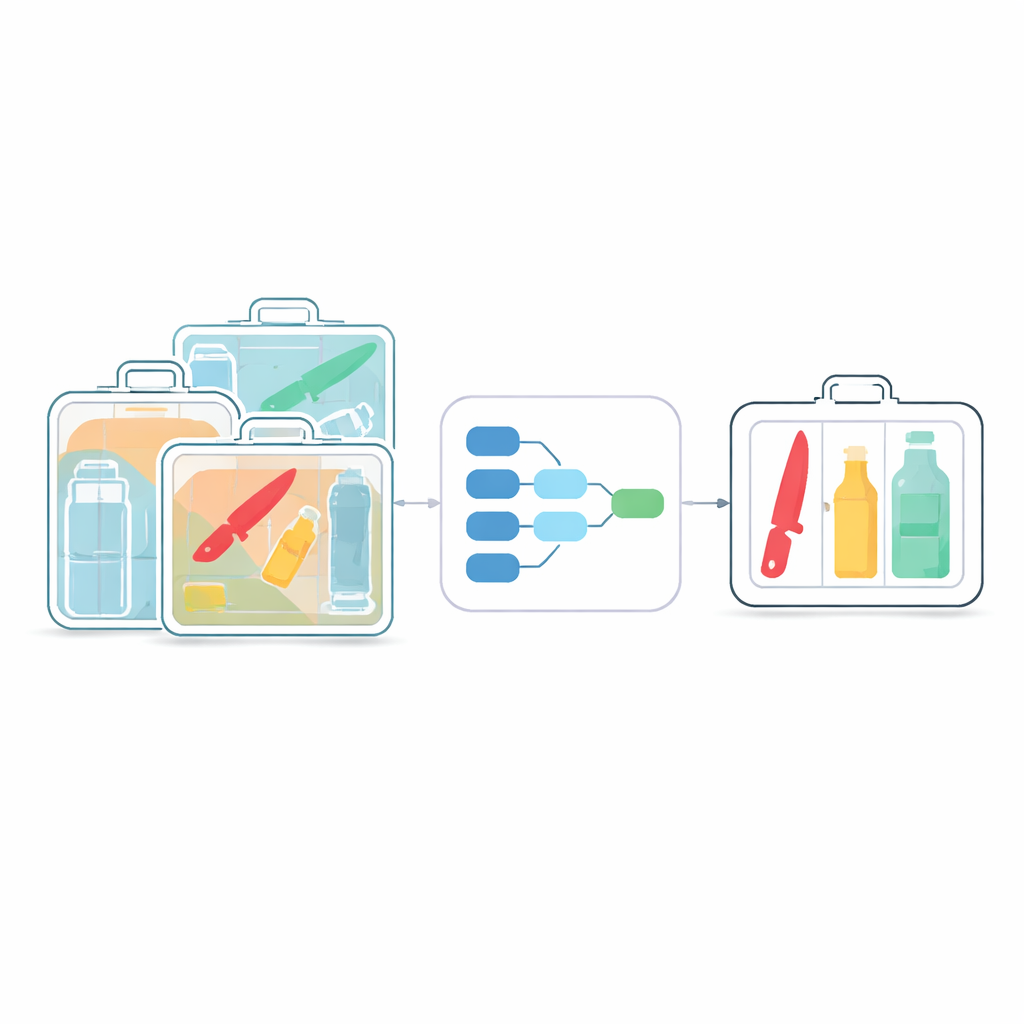
O desafio de ver através da desordem
Sistemas de segurança por raio‑X são a primeira linha de defesa em aeroportos, estações de metrô e outros espaços públicos cheios. A inspeção humana tradicional é lenta e cansativa, o que aumenta o risco de itens passarem despercebidos. Detectores de IA modernos, como a família YOLO, melhoraram a triagem automatizada, mas foram originalmente projetados para fotos do dia a dia, não para as vistas fantasmagóricas e de baixo contraste dos raios‑X. Nessas varreduras, objetos frequentemente se sobrepõem, aparecem semitransparentes e variam muito em tamanho. Lâminas pequenas ou garrafas podem ficar enterradas entre itens inofensivos, e muitos dos algoritmos atuais ou os deixam escapar, ou exigem grande poder computacional difícil de implantar em máquinas compactas e de baixo custo.
Um cérebro mais enxuto para máquinas de raio‑X
Os autores partem do detector popular YOLOv8 e o redesenham especificamente para imagens de raio‑X. O primeiro passo é enxugar a rede usando convoluções “depthwise separable” — uma maneira técnica de dizer que o modelo busca padrões de forma mais econômica. Em vez de aplicar filtros grandes e caros em todos os canais da imagem de uma vez, a operação é decomposta em etapas mais baratas. Essa mudança reduz o número de cálculos em cerca de um quarto a dois quintos, preservando ainda os detalhes finos necessários para detectar objetos pequenos e parcialmente ocultos. O resultado é um “cérebro” digital mais leve que pode rodar em tempo real em hardware modesto, como processadores embarcados dentro dos scanners.
Ajuda ao modelo para focar no que importa
Reduzir a rede não é suficiente; ela também precisa ser mais seletiva. Para isso, os pesquisadores introduzem um módulo Channel‑Spatial Attention Fusion (CSAF). Um ramo desse módulo aprende quais tipos de características visuais — bordas, formas ou indícios de material — são mais informativas de modo geral, enquanto outro ramo aprende onde na imagem a ação está acontecendo. Em vez de aplicar essas atenções em sequência, o CSAF as processa em paralelo e depois as funde, para que o sistema possa considerar simultaneamente o “o quê” e o “onde”. Essas unidades de atenção são entrelaçadas em um projeto multiescala que combina visões grosseiras e detalhadas da cena, especialmente útil para detectar itens minúsculos e sobrepostos em malas lotadas.
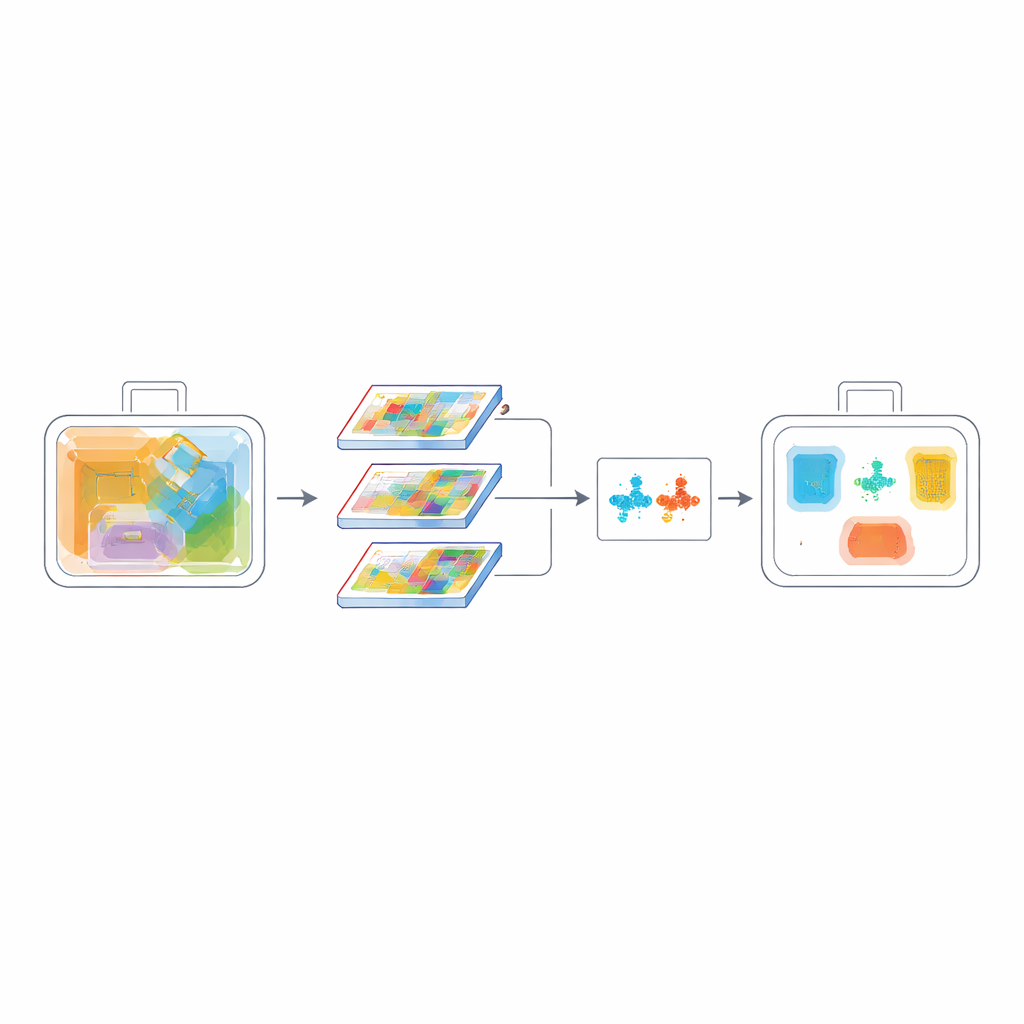
Ensinando o sistema a separar semelhantes
Outra dificuldade nas imagens de raio‑X é que muitos itens se parecem: uma lata e um borrifador, ou diferentes tipos de facas, podem compartilhar contornos quase idênticos. Para tornar o modelo melhor em distinguir essas categorias, os autores adicionam um objetivo de aprendizado contrastivo. Durante o treinamento, a rede é incentivada a aproximar exemplos da mesma classe em sua representação interna, enquanto afasta classes diferentes. Ao mesmo tempo, uma medida de sobreposição ao nível de pixel chamada PIoU ajuda a ajustar a posição e a forma das caixas delimitadoras previstas, algo vital quando os objetos estão inclinados, lotados ou parcialmente visíveis. Em conjunto, essas perdas ensinam o modelo não só onde um objeto está, mas também o que o diferencia de vizinhos confusos.
Comprovando desempenho em testes realistas
A equipe avalia sua abordagem em dois conjuntos de dados desafiadores de raio‑X que incluem pontos de verificação reais e cenas sintéticas de bagagens com múltiplas categorias de ameaça. Em comparação com a linha de base padrão YOLOv8, seu modelo alcança maior precisão em medidas estritas de sobreposição, usando menos parâmetros e menos computação. Mantém taxas de detecção muito altas para objetos nítidos e melhora o reconhecimento de itens transparentes ou deformáveis, como garrafas e caixas de bebida. Curvas de precisão‑confiança e recall‑confiança mostram que suas previsões permanecem estáveis mesmo quando o limiar para declarar uma detecção é aumentado, o que significa menos alarmes falsos e menos ameaças não detectadas. Testes em um segundo conjunto de dados coletado em outro local confirmam que o sistema generaliza bem, um requisito importante para implantação no mundo real, onde o conteúdo das malas e as condições de imagem variam.
O que isso significa para viajantes comuns
Para o público em geral, a conclusão é que este trabalho oferece uma maneira mais inteligente e enxuta de escanear bagagens. Ao redesenhar um detector de IA moderno para ser leve e mais discriminativo, os autores possibilitam máquinas de raio‑X que podem rodar rapidamente em hardware acessível, ao mesmo tempo em que detectam ameaças pequenas, sobrepostas ou semelhantes. Se esses métodos forem adotados na prática, poderão ajudar a reduzir filas, diminuir revistorias desnecessárias de bagagens e — o mais importante — aumentar as chances de que itens realmente perigosos sejam apreendidos antes de chegarem ao portão.
Citação: Diao, Q., Chan, W., Zain, A.M. et al. A lightweight multi-scale detection framework for X-ray images with supervised contrastive learning. Sci Rep 16, 8635 (2026). https://doi.org/10.1038/s41598-026-38000-0
Palavras-chave: segurança por raio‑X, detecção de objetos, aprendizado profundo, triagem em aeroportos, visão computacional