Clear Sky Science · pt
Um novo algoritmo de gradiente distribuído para otimização composta com restrições em redes direcionadas
Tomada de decisão mais inteligente sem um chefe central
Tecnologias modernas — de redes elétricas e redes de sensores a frotas de drones — frequentemente dependem de muitos dispositivos trabalhando juntos sem um controlador central único. Cada dispositivo enxerga apenas parte do cenário, mas o conjunto precisa concordar sobre um ponto de operação bom e seguro. Este artigo apresenta uma nova maneira para tais sistemas distribuídos tomarem decisões conjuntas de forma eficiente e confiável, mesmo quando os enlaces de comunicação são unilaterais e o problema inclui restrições difíceis e “cantos” acentuados no custo.
Por que muitos cérebros pequenos superam um cérebro grande
A otimização centralizada — em que um computador poderoso reúne todos os dados, resolve um grande problema e envia comandos de volta — é frágil e difícil de escalar. Pode falhar se a unidade central cair ou sofrer com atrasos de comunicação em sistemas grandes. A otimização distribuída inverte esse quadro: cada nó (ou agente) mantém seus próprios dados, atualiza sua decisão local e troca apenas informação limitada com vizinhos próximos. O desafio é projetar regras de atualização de modo que, apesar da comunicação parcial e unidirecional, todos os nós ainda concordem em uma solução que seja globalmente ótima para a rede.
Problemas difíceis com cantos agudos e limites do mundo real
Os autores focam em uma classe exigente de problemas em que o custo total combina termos suaves (que mudam de forma gradual) com termos não suaves (que podem criar quinas acentuadas), como a popular norma l1. Essas partes não suaves são essenciais para promover esparsidade e robustez em aplicações como compressão de sinais, remoção de ruído e ajuste de modelos. Além disso, cada nó deve respeitar restrições locais de igualdade e desigualdade e permanecer dentro de limites permitidos. Tudo isso precisa ser tratado sobre uma rede de comunicação direcionada, onde a informação pode fluir do nó A para o nó B, mas não necessariamente no sentido inverso. Métodos existentes normalmente assumem enlaces não direcionados, restrições mais simples ou passos fixos difíceis de ajustar e menos flexíveis.
Uma nova forma de os nós conversarem e concordarem
Para enfrentar essas dificuldades, o artigo propõe um novo algoritmo distribuído baseado em gradiente, adequado a problemas compostos e com restrições em redes direcionadas. Cada nó ajusta repetidamente sua decisão local seguindo um passo de gradiente com projeção: move-se na direção que reduz o custo global e então projeta o resultado de volta em sua região permitida para que as restrições permaneçam satisfeitas. Variáveis extras atuam como controle interno, ajudando a rede a impor condições de igualdade e desigualdade e a lidar com o termo não suave l1. Uma inovação chave é um mecanismo de correção que compensa o desequilíbrio causado por enlaces unidirecionais, usando apenas pesos linha‑estocásticos — isto é, cada nó precisa saber apenas como recebe informação, não para quem ele envia informação.
Tamanhos de passo flexíveis com convergência garantida
Outra característica marcante do método é o uso de tamanhos de passo que podem variar no tempo, mas serem constantes localmente: cada nó pode escolher seu próprio passo dentro de um intervalo comprovadamente seguro, em vez de compartilhar um único valor fixo. Essa flexibilidade facilita o ajuste na prática e permite que o algoritmo se adapte melhor às diferentes condições locais. Usando ferramentas da teoria de estabilidade, os autores constroem uma função de Lyapunov — uma espécie de medida de energia matemática — e provam que ela diminui a cada iteração, contanto que os tamanhos de passo respeitem um limite superior claro. Isso garante que, a partir de qualquer ponto inicial, as decisões de todos os nós convirjam para a mesma solução globalmente ótima, mesmo na presença de termos não suaves e de restrições mistas.
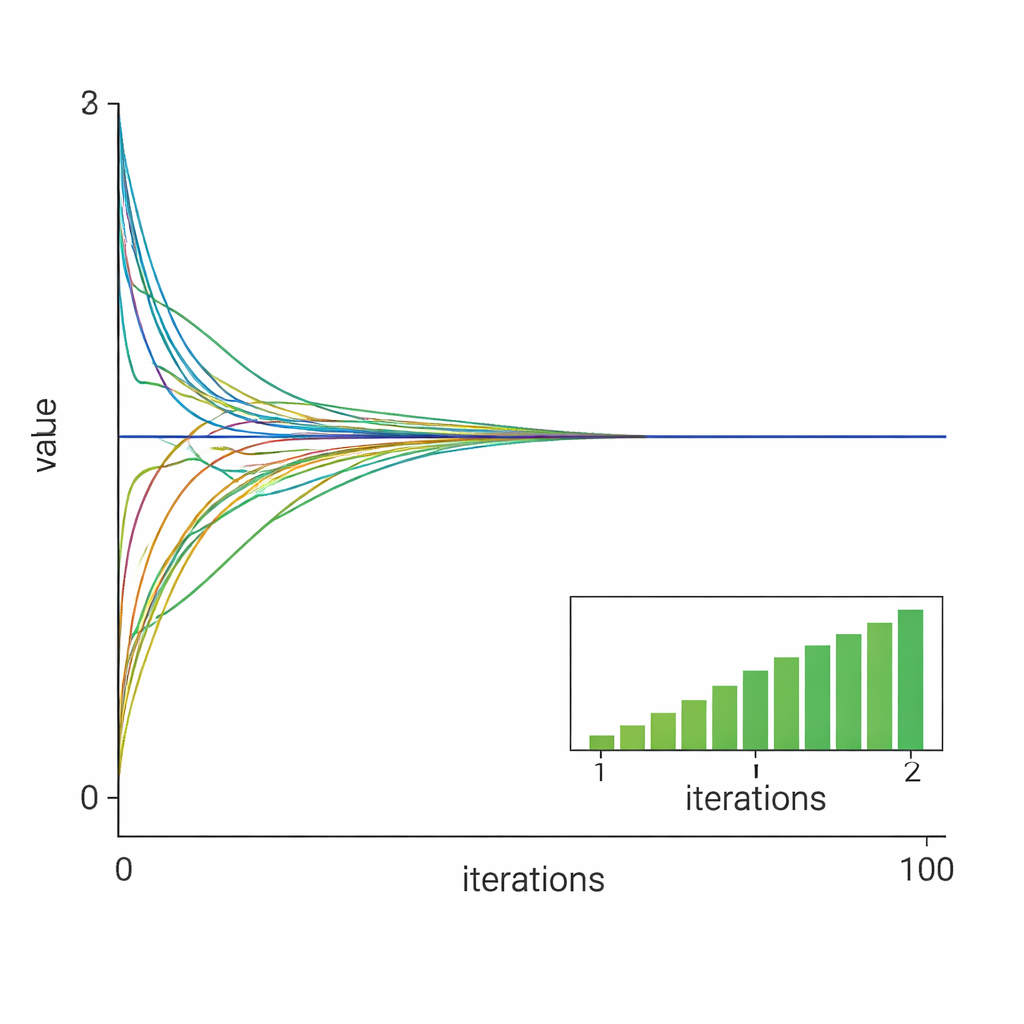
Colocando o método à prova
Os pesquisadores validam sua teoria com dois estudos de caso numéricos. No primeiro, dez nós resolvem cooperativamente um problema quadrático com restrições e regularização l1, semelhante a tarefas em alocação de recursos ou fusão de sensores. Os resultados mostram que todas as variáveis locais rapidamente se alinham com a solução ótima centralizada e que usar um tamanho de passo constante bem escolhido leva a uma convergência mais rápida, quase linear, em comparação com um tamanho de passo decrescente. No segundo caso, o método enfrenta um problema de desvios absolutos com má condição, conhecido por ser desafiador para solucionadores padrão. Mesmo aí, com apenas cinco nós e dados altamente desbalanceados, o algoritmo conduz de forma confiável todos os agentes à solução correta.
O que isso significa para sistemas reais
Em termos práticos, o artigo oferece uma receita robusta para grupos de dispositivos em rede resolverem conjuntamente problemas de otimização difíceis sem um controlador mestre, respeitando limites práticos e funcionando sobre enlaces de comunicação unidirecionais. O método pode ser aplicado a sistemas de energia, redes de sensores e tarefas de aprendizado de máquina distribuído onde restrições e esparsidade são importantes. Como precisa apenas de informação local de vizinhança e fornece regras claras para escolher os tamanhos de passo, é bem adequado para implementações reais. Os autores sugerem estender a abordagem a redes que variam no tempo a seguir, aproximando‑a de ambientes de comunicação realistas e em constante mudança.
Citação: Ou, M., Zhang, H., Yan, Z. et al. A novel distributed gradient algorithm for composite constrained optimization over directed network. Sci Rep 16, 5185 (2026). https://doi.org/10.1038/s41598-026-36058-4
Palavras-chave: otimização distribuída, redes direcionadas, sistemas multiagente, regularização esparsa, problemas convexos com restrições