Clear Sky Science · pl
Wbudowane ramy głębokiego uczenia do wykrywania przemocy w czasie rzeczywistym i generowania ostrzeżeń
Dlaczego inteligentniejsze kamery są ważne dla codziennego bezpieczeństwa
Bójki i napaści na ulicach, w szkołach czy w transporcie publicznym często rozgrywają się w ciągu kilku sekund — długo zanim operatorzy zdołają przejrzeć wszystkie podglądy i wezwać pomoc. W tym badaniu zaprezentowano sposób, w jaki małe, niedrogie komputery — urządzenia tak skromne jak płytka Raspberry Pi — mogą analizować obraz wideo w czasie rzeczywistym i automatycznie oznaczać prawdopodobne zachowania agresywne. Upakowując wydajne techniki analizy wideo w efektywny system działający na urządzeniu, praca pokazuje, jak istniejące kamery mogą stać się szybszymi i bardziej niezawodnymi strażnikami, bez polegania na odległych centrach danych czy stałej uwadze człowieka.
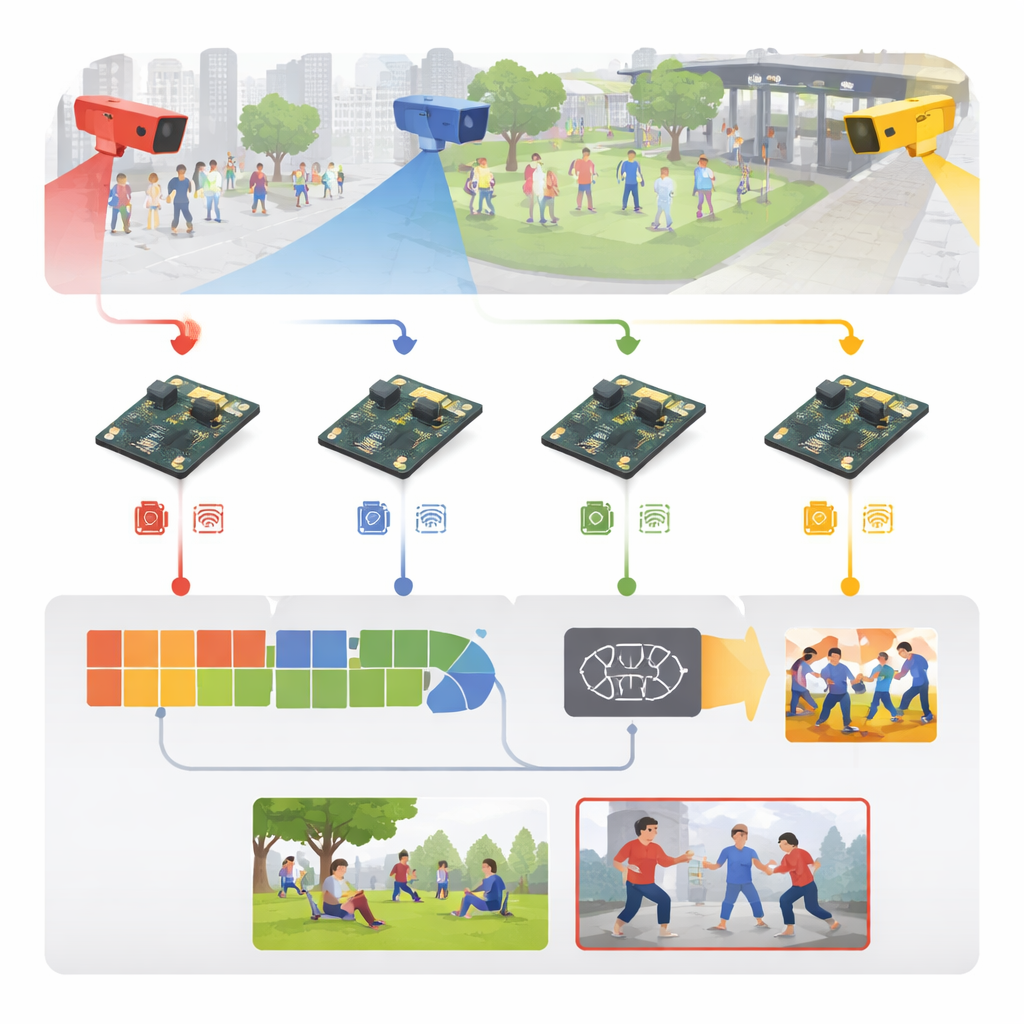
Przekształcanie surowego wideo w sygnały wczesnego ostrzegania
System zaczyna od zwykłych materiałów nadzorczych z miejsc takich jak stadiony, chodniki, kampusowe alejki czy korytarze wewnętrzne. Zamiast przesyłać cały ten strumień wideo do serwera centralnego, każda kamera wysyła klatki bezpośrednio do pobliskiej wbudowanej płytki. Tam przychodzące klatki są standaryzowane — zmieniane rozmiary, oczyszczane i podczas treningu delikatnie modyfikowane przez obracanie, odbicia czy zmiany jasności — tak by model nauczył się radzić sobie z różnym oświetleniem, punktami widzenia i gęstością tłumu. Autorzy przygotowali też bogaty zestaw materiałów treningowych: pięć dobrze znanych publicznych zbiorów oraz nową kolekcję z sześcioma kategoriami obejmującą uderzenia pięścią, kopnięcia, ataki z użyciem broni, przemoc w tłumie, bieganie i normalne interakcje.
Jak działa kompaktowy „mózg” w urządzeniu
W centrum systemu znajduje się uproszczony, dwustopniowy mechanizm uczenia. Najpierw lekki moduł obrazowy skanuje każdą klatkę w poszukiwaniu istotnych wskazówek wizualnych — konturów ciała, pozycji ramion i nóg oraz krawędzi ruchu — wykorzystując oszczędne operacje konwolucyjne zapożyczone z modeli wizji mobilnej. Następnie drugi moduł analizuje krótką sekwencję klatek, aby zrozumieć, jak te wskazówki zmieniają się w czasie, uchwytując różnicę między na przykład przyjaznym klepnięciem a ciosem. Osiągnięto to za pomocą wydajnej struktury rekurencyjnej, która pamięta niedawny ruch bez ciężkiego obciążenia obliczeniowego typowego dla masywniejszych sieci wideo. Prosta warstwa końcowa przekształca to przestrzenno‑czasowe rozumienie w jedną z sześciu etykiet aktywności, rozróżniając zwykłe ruchy od prawdopodobnej agresji.
Wpasowanie głębokiego uczenia w małą, energooszczędną płytkę
Zaprojektowanie sprytnego modelu to tylko połowa historii; prawdziwym wyzwaniem jest sprawić, by działał szybko na komputerze wielkości dłoni. Autorzy potraktowali cały system jak potok inżynieryjny: zaczęli od wersji trenowanej na wydajnej stacji graficznej, potem przekonwertowali ją do formatu przenośnego i agresywnie skompresowali. Zredukowano precyzję liczb, tak aby wagi zajmowały jedną czwartą pierwotnej pamięci, a niepotrzebne części sieci zostały przycięte. Korzystając ze specjalistycznych narzędzi optymalizacyjnych poza urządzeniem, wygenerowano dopracowany model, który można efektywnie uruchomić na Raspberry Pi przy użyciu zoptymalizowanego środowiska wykonawczego. Efektem jest system przetwarzający około 26 klatek na sekundę z opóźnieniem rzędu 38 milisekund na klatkę, zużywający przy tym zaledwie kilka watów — na tyle szybki i oszczędny, by działać ciągle w terenie.

Testy, zaufanie i ograniczenia oceny maszynowej
Aby sprawdzić, czy ich kompaktowy obserwator jest jednocześnie dokładny i niezawodny, badacze poddali go szeregowi testów. W zestawach benchmarkowych od lodowisk hokejowych po miejskie ulice, oraz na ich własnym zbiorze sześcioklasowym, system poprawnie oznaczył zdarzenia w około 97 na 100 przypadków i wykazał silną równowagę między wykrywaniem aktów przemocy a unikaniem fałszywych alarmów. Porównania z bardziej rozbudowanymi modelami wideo — takimi jak pełne sieci konwolucyjne 3D czy konstrukcje oparte na transformerach — pokazały, że ta chudsza metoda potrafi dorównać im lub przewyższyć je pod względem dokładności, przy znacznie mniejszych wymaganiach obliczeniowych. Zespół również zwizualizował, na co model "patrzy" w każdej klatce, odkrywając, że jego uwaga naturalnie koncentruje się na poruszających się kończynach i bliskich kontaktach między ludźmi, zamiast na nieistotnych detalach tła, co pomaga budować zaufanie do jego decyzji.
Co to oznacza dla bezpieczniejszych, inteligentniejszych przestrzeni
Główne przesłanie badania nie polega na wynalezieniu zupełnie nowego rodzaju sieci neuronowej, lecz na pokazaniu, jak sprawdzone techniki zapakować w praktyczne narzędzie działające w czasie rzeczywistym na skromnym sprzęcie. Poprzez staranne wyważenie projektu modelu, przygotowania danych i kompresji na etapie wdrożenia, autorzy dostarczają system wbudowany, który potrafi monitorować obraz na żywo, rozpoznawać prawdopodobną przemoc i zgłaszać alarmy przy niskim opóźnieniu i niskim zużyciu energii. Przyznają też otwarte wyzwania: system nadal może mieć problemy przy słabym oświetleniu, w zatłoczonych scenach lub przy szybkich, sportopodobnych ruchach, a każda taka technologia musi być wdrażana z uwzględnieniem prywatności, uprzedzeń i nadzoru ludzkiego. Mimo to praca wskazuje ku przyszłości, w której wiele zwykłych kamer będzie sparowanych z małymi, cichymi komputerami pomagającymi wykrywać niebezpieczeństwo wcześniej i wspierać szybsze, lepiej poinformowane reakcje.
Cytowanie: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Słowa kluczowe: wykrywanie przemocy, wizja wbudowana, edge AI, nadzór wideo, głębokie uczenie