Clear Sky Science · pl
Wstrzykiwanie stanów magicznych na procesorach kwantowych IBM powyżej progu destylacji
Dlaczego to ma znaczenie dla przyszłych komputerów
Dzisiejsze prototypowe komputery kwantowe są z zasady potężne, ale w praktyce kruche: drobne niedoskonałości szybko mieszają ich obliczenia. Artykuł przedstawia konkretny krok w kierunku okiełznania tej kruchości na sprzęcie IBM. Autorzy pokazują, jak wiarygodnie tworzyć specjalne „magiczne” stany kwantowe — kluczowe składniki do uruchamiania pełnego zestawu algorytmów kwantowych — używając mniej zasobów sprzętowych niż wcześniej i o jakości wystarczającej do praktycznego wykorzystania. Ich wyniki sugerują, że prawdziwie tolerancyjne na błędy obliczenia kwantowe coraz bardziej przechodzą z teorii do inżynieryjnej rzeczywistości.
Budowanie bezpieczniejszego domu dla informacji kwantowej
Aby chronić informacje kwantowe, badacze rozpraszają je na wielu fizycznych kubitach w uporządkowanym wzorze znanym jako kod powierzchniowy. Ten kod nieustannie sprawdza błędy, nie zaglądając bezpośrednio do kruchej informacji. Urządzenia IBM użyte tutaj układają kubity w układ „heavy-hexagon”, w którym każdy kubit styka się co najwyżej z trzema sąsiadami, w przeciwieństwie do czterokierunkowej siatki często zakładanej w podręcznikach. Taki układ sprzętowy komplikuje sposób rysowania i operowania standardowymi kodami powierzchniowymi. Autorzy przyjmują bardziej ekonomiczną odmianę zwaną obróconym kodem powierzchniowym i dopasowują ją do heksagonalnej łączności IBM, co w przybliżeniu zmniejsza liczbę potrzebnych kubitów o połowę w porównaniu z wcześniejszymi podejściami dla dużych rozmiarów kodu.
Dopasowanie kodu do sprzętu
W podręcznikowej wersji kodu powierzchniowego niektóre wielokubitowe checki, zwane stabilizatorami, działają na czterech kubitach jednocześnie. Na chipach IBM w układzie heavy-hexagon nie jest to bezpośrednio możliwe z powodu ograniczonych połączeń. Autorzy rozwiązują to przez „złożenie” każdego czterokubitowego sprawdzenia w sekwencję prostszych dwu-kubitowych checków, używając dodatkowych kubitów-mostów jako pośredników. Następnie „rozwiązują” tę transformację, aby przywrócić oryginalną strukturę logiczną. Na zewnętrznych krawędziach kodu, gdzie dostępnych są mniejsza liczba sąsiadów, projektują ostrożnie mniejsze dwu- i jedno-kubitowe checki, które nadal wpisują się w ten sam rytm działania. Symulacje przeprowadzone przy realistycznym modelu szumów pokazują, że ten obrócony układ nie tylko zachowuje wydajność, lecz nieznacznie poprawia akceptowalne fizyczne wskaźniki błędów w porównaniu z wcześniejszymi kodami dla heavy-hexagon, z progami rzędu trzech do czterech błędów na tysiąc operacji.
Wstrzyknięcie odrobiny kwantowej magii
Chronienie informacji to tylko połowa historii. Aby uruchamiać naprawdę uniwersalne algorytmy kwantowe, komputer musi też wykonywać pewne specjalne operacje, których nie da się zbudować wyłącznie z najbezpieczniejszych, najprostszych bramek. Potężnym rozwiązaniem jest przygotowanie „stanów magicznych”, specjalnych stanów jednowubitowych, które po przeprowadzeniu przez sprytne obwody odblokowują te trudne operacje. Autorzy wdrażają protokół zwany wstrzykiwaniem stanów magicznych na procesorze IBM ibm_fez, używając obróconego kodu powierzchniowego o odległości 3 zbudowanego z 25 kubitów fizycznych. Zaczynają od przygotowania wybranego jednowubitowego stanu w centrum łaty kodu oraz prostych stanów na otaczających kubitach. Następnie uruchamiają pojedynczą rundę obwodów sprawdzających błędy dostosowanych do układu heavy-hexagon, a na końcu mierzą wszystkie kubity w starannie dobranych bazach, aby odtworzyć, jaki stan logiczny został wygenerowany wewnątrz kodu.
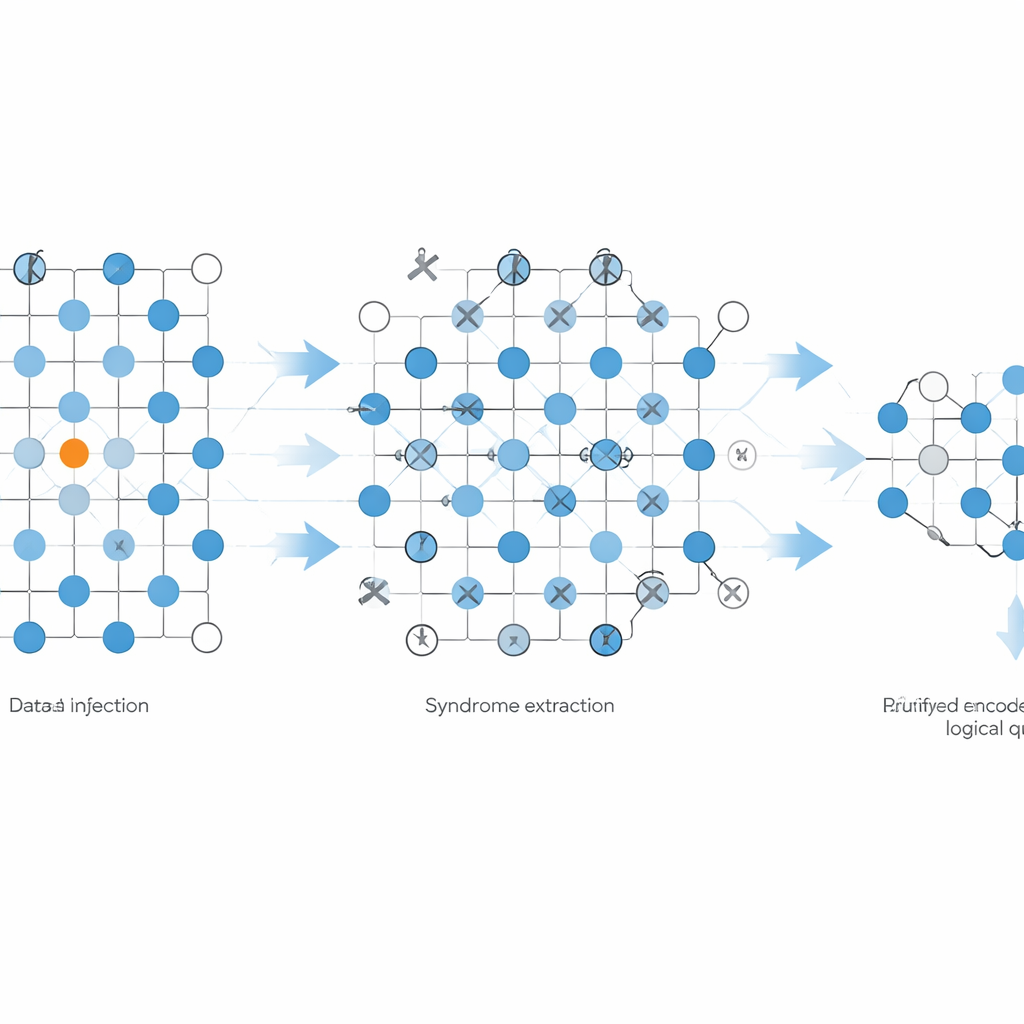
Wydzielanie najczystszych wyników
Rzeczywiste urządzenia są zaszumione, więc zespół stosuje strategię znaną jako post-selekcja: zachowują tylko te próby eksperymentalne, których sygnały sprawdzające błędy wyglądają idealnie czysto, a pozostałe odrzucają. Chociaż oznacza to, że przyjmują nieco ponad jedną trzecią wszystkich powtórzeń, ocalałe próby są wysokiej jakości. Na podstawie tych wybranych zdarzeń rekonstruują zakodowany stan logiczny i porównują go z idealnym celem, używając standardowych miar podobieństwa kwantowego zwanych fidelnościami. Dla szerokiego zakresu stanów docelowych na sferze Blocha najniższa zaobserwowana fidelność wynosi około 0,84, a średnia zbliża się do 0,88. Co istotne, dwa szczególnie ważne stany magiczne, często oznaczane jako H i T w literaturze obliczeń kwantowych, są wytwarzane z fidelnościami około 0,88 i 0,87 — komfortowo powyżej znanych progów, przy których dalsze procedury „destylacji” mogą podnieść ich jakość jeszcze bardziej.
Co to oznacza dla jutrzejszych urządzeń kwantowych
Mówiąc przystępnie, autorzy pokazują, że obecny sprzęt kwantowy IBM może już pomieścić zwarty układ korekcji błędów, który nie tylko chroni informacje, lecz także niezawodnie wytwarza specjalne składniki potrzebne do zaawansowanych algorytmów kwantowych. Ich obrócony projekt oszczędza kubity, działa w ramach rzeczywistych ograniczeń okablowania i osiąga wskaźniki błędów poniżej kluczowych granic teoretycznych. Choć wciąż pozostaje wiele przeszkód — zwłaszcza poprawa pomiarów, skalowanie do większych odległości kodu oraz redukcja subtelnych ścieżek błędów wielokubitowych — praca ta pokazuje, że wysokowartościowe, korygujące błędy zasoby takie jak stany magiczne nie są już wyłącznie teoretyczne. Mogą być tworzone, weryfikowane i wykorzystywane jako elementy konstrukcyjne na dzisiejszych maszynach, przybliżając prawdziwie tolerancyjne obliczenia kwantowe o krok bliżej.
Cytowanie: Kim, Y., Sevior, M. & Usman, M. Magic state injection on IBM quantum processors above the distillation threshold. Sci Rep 16, 11189 (2026). https://doi.org/10.1038/s41598-026-40381-1
Słowa kluczowe: korekcja błędów kwantowych, kod powierzchniowy, wstrzykiwanie stanów magicznych, procesor kwantowy IBM, tolerancyjne obliczenia kwantowe