Clear Sky Science · pl
Lekka wieloskalowa metoda detekcji w obrazach rentgenowskich z nadzorowanym uczeniem kontrastowym
Dlaczego inteligentniejsze kontrole rentgenowskie są ważne
Każdy, kto stał w kolejce do kontroli na lotnisku, wie, że każda torba musi zostać przeskanowana szybko i dokładnie. Obrazy rentgenowskie wcale nie są proste: noże, butelki, laptopy i ładowarki układają się jeden na drugim, a niebezpieczne przedmioty mogą łatwo ukryć się w chaosie. Artykuł przedstawia nową metodę sztucznej inteligencji (AI), która pomaga urządzeniom rentgenowskim bardziej niezawodnie wykrywać małe lub nachodzące na siebie zagrożenia, zachowując jednocześnie wystarczającą szybkość działania na zatłoczonych punktach kontroli.
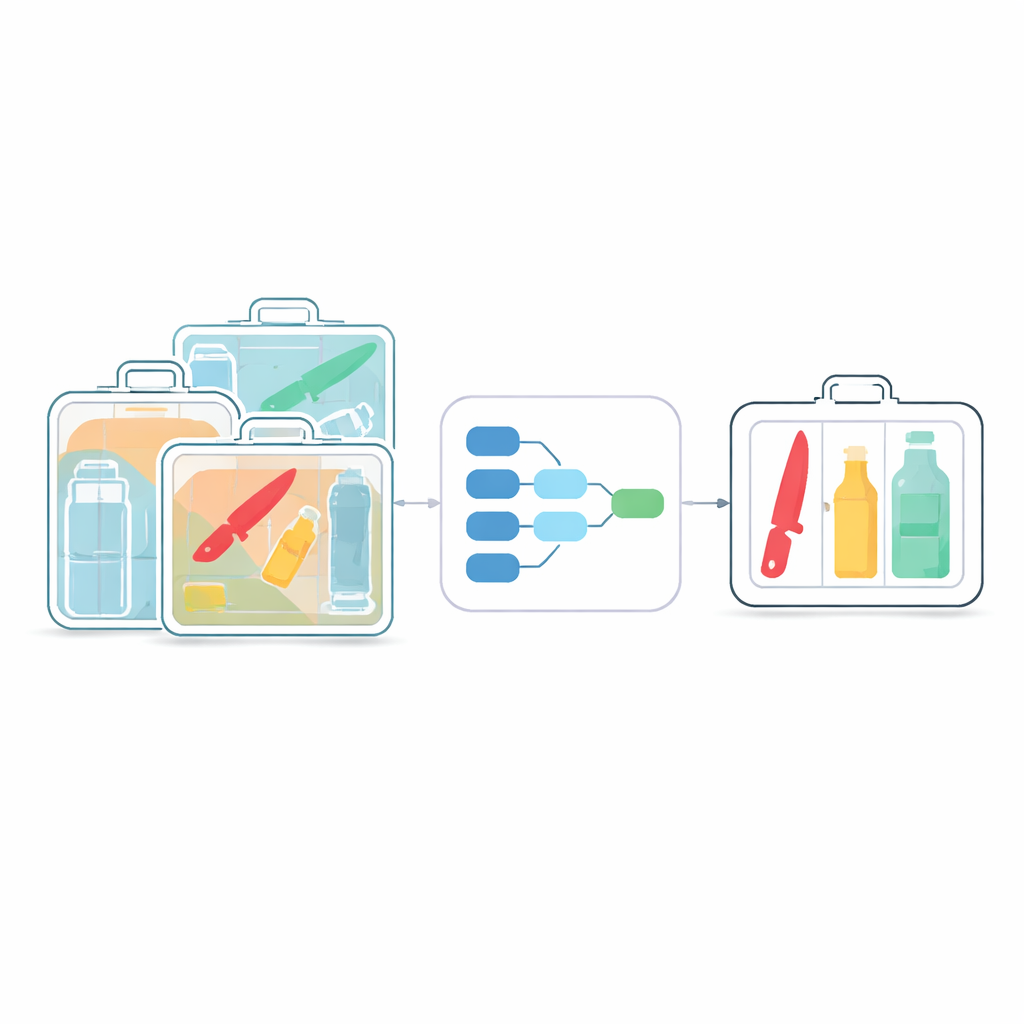
Trudność w przejrzeniu chaosu
Systemy bezpieczeństwa oparte na rentgenie to pierwsza linia obrony na lotniskach, w metrze i innych zatłoczonych miejscach publicznych. Tradycyjna inspekcja przez ludzi jest powolna i męcząca, co zwiększa ryzyko przeoczeń. Nowoczesne detektory AI, takie jak rodzina YOLO, poprawiły automatyczne skanowanie, ale zostały pierwotnie zaprojektowane do zwykłych zdjęć, a nie eterycznych, niskokontrastowych obrazów rentgenowskich. Na tych skanach obiekty często nachodzą na siebie, są częściowo przezroczyste i bardzo zróżnicowane pod względem rozmiaru. Małe ostrza czy butelki mogą być ukryte wśród przedmiotów neutralnych, a wiele obecnych algorytmów albo je pomija, albo wymaga dużej mocy obliczeniowej, trudnej do wdrożenia na kompaktowych, niskokosztowych urządzeniach.
Lżejszy „mózg” dla maszyn rentgenowskich
Autorzy bazują na popularnym detektorze YOLOv8 i przeprojektowują go specjalnie pod kątem obrazów rentgenowskich. Ich pierwszym krokiem jest odchudzenie sieci za pomocą konwolucji separowalnych wgłąb kanałów (depthwise separable) — technicznego sposobu na bardziej oszczędne rozpoznawanie wzorców. Zamiast stosować duże, kosztowne filtry jednocześnie na wszystkich kanałach obrazu, operację rozkłada się na tańsze kroki. Ta zmiana zmniejsza liczbę obliczeń o około jedną czwartą do dwóch piątych, zachowując jednocześnie szczegóły niezbędne do wykrywania małych, częściowo ukrytych obiektów. Efektem jest lżejszy cyfrowy „mózg”, który może działać w czasie rzeczywistym na skromnym sprzęcie, takim jak wbudowane procesory w skanerach.
Pomaganie modelowi skupić się na istotnym
Samo pomniejszenie sieci nie wystarczy; musi ona też być bardziej selektywna. W tym celu badacze wprowadzają moduł Channel-Spatial Attention Fusion (CSAF). Jeden z jego torów uczy się, które rodzaje cech wizualnych — krawędzie, kształty lub wskazówki materiałowe — są ogólnie najbardziej informatywne, podczas gdy drugi tor uczy się, gdzie w obrazie dzieje się akcja. Zamiast stosować te mechanizmy uwagi kolejno, CSAF przetwarza je równolegle, a następnie scala, aby system mógł jednocześnie rozważać „co” i „gdzie”. Jednostki uwagi są wplecione w wieloskalową architekturę łączącą widoki ogólne i szczegółowe, co jest szczególnie pomocne przy wykrywaniu drobnych, nachodzących na siebie obiektów w zatłoczonych torbach.
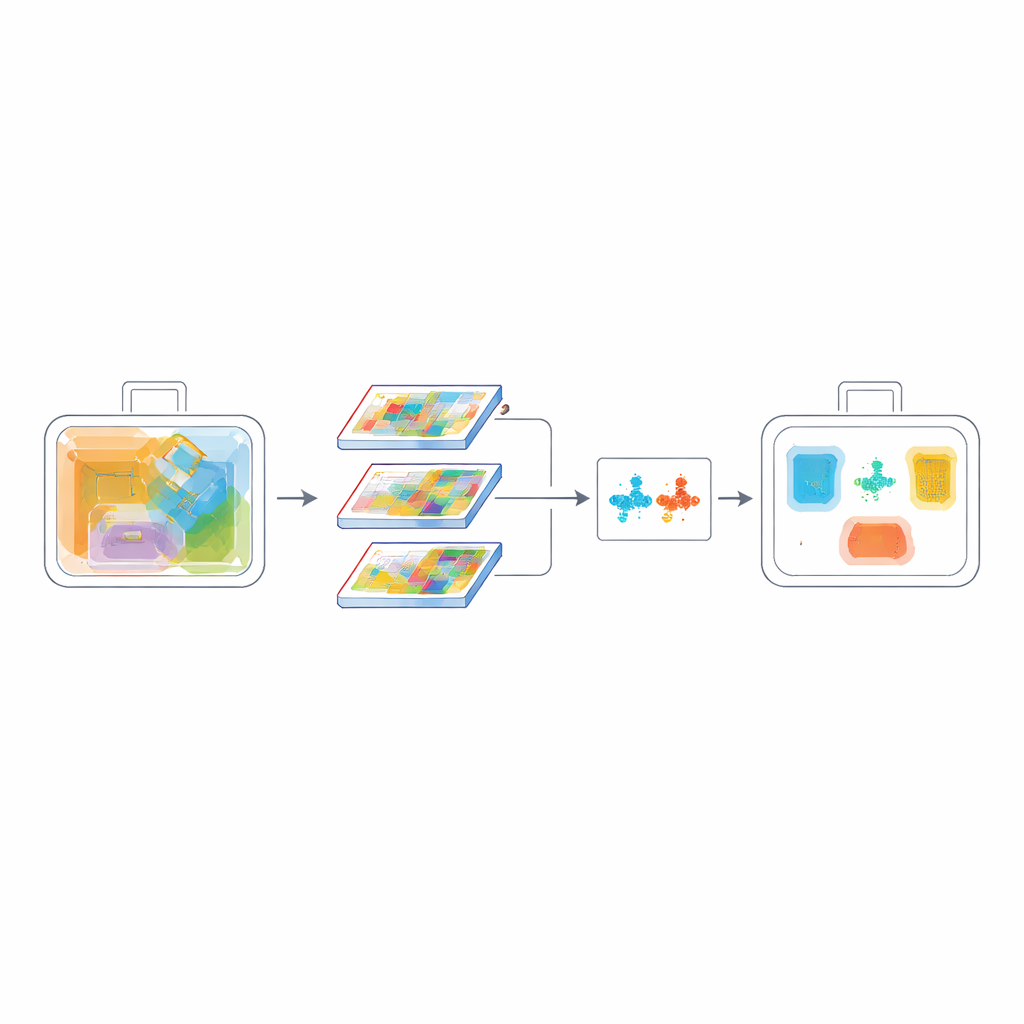
Nauka rozróżniania podobnych przedmiotów
Kolejną trudnością w skanach rentgenowskich jest to, że wiele przedmiotów wygląda podobnie: puszka i spray czy różne rodzaje noży mogą mieć niemal identyczne kontury. Aby poprawić zdolność modelu do rozróżniania takich kategorii, autorzy dodają cel uczenia kontrastowego. Podczas treningu sieć jest zachęcana do zbliżania przykładów tej samej klasy w swojej wewnętrznej reprezentacji, jednocześnie odsuwając klasy różne od siebie. Równocześnie miara nakładania na poziomie pikseli zwana PIoU pomaga dopracować pozycję i kształt przewidywanych ramek ograniczających, co jest kluczowe, gdy obiekty są obrócone, zatłoczone lub częściowo widoczne. Razem te funkcje strat uczą model nie tylko gdzie znajduje się obiekt, ale także co odróżnia go od mylących sąsiadów.
Potwierdzenie wydajności w realistycznych testach
Zespół ocenia swoje podejście na dwóch wymagających zbiorach danych rentgenowskich zawierających rzeczywiste punkty kontroli oraz syntetyczne sceny bagażowe z wieloma kategoriami zagrożeń. W porównaniu ze standardową bazą YOLOv8 ich model osiąga wyższą dokładność przy rygorystycznych miarach nakładania, jednocześnie wykorzystując mniej parametrów i mniejsze obciążenie obliczeniowe. Utrzymuje bardzo wysokie wskaźniki wykrywania twardych przedmiotów i poprawia rozpoznawanie przezroczystych lub odkształcalnych obiektów, takich jak butelki i kartony po napojach. Krzywe precyzja–pewność i czułość–pewność pokazują, że jego przewidywania pozostają stabilne nawet po podniesieniu progu uznania detekcji, co przekłada się na mniej fałszywych alarmów i mniej przeoczonych zagrożeń. Testy na drugim zbiorze danych zebranym w innym miejscu potwierdzają, że system dobrze się uogólnia — istotny warunek dla wdrożeń w świecie rzeczywistym, gdzie zawartość bagażu i warunki obrazowania się różnią.
Co to oznacza dla codziennych podróżnych
Dla laika sedno sprawy jest takie: ta praca oferuje mądrzejszy, lżejszy sposób skanowania bagażu. Przeprojektowując nowoczesny detektor AI tak, by był jednocześnie lekki i bardziej rozróżniający, autorzy umożliwiają urządzeniom rentgenowskim działanie szybko na przystępnym sprzęcie, a jednocześnie wychwytywanie małych, nachodzących na siebie lub podobnych do siebie zagrożeń. Jeśli takie metody zostaną wdrożone w praktyce, mogą pomóc skrócić kolejki, zmniejszyć liczbę niepotrzebnych kontroli bagażu i — co najważniejsze — zwiększyć szanse na wykrycie naprawdę niebezpiecznych przedmiotów, zanim trafią do bramki.
Cytowanie: Diao, Q., Chan, W., Zain, A.M. et al. A lightweight multi-scale detection framework for X-ray images with supervised contrastive learning. Sci Rep 16, 8635 (2026). https://doi.org/10.1038/s41598-026-38000-0
Słowa kluczowe: bezpieczeństwo rentgenowskie, detekcja obiektów, głębokie uczenie, kontrola na lotnisku, widzenie komputerowe