Clear Sky Science · nl
Vergelijking van prestaties van LLM's en machine learning bij het voorspellen van complicaties na percutane kyphoplastie voor osteoporotische wervelcompressiefracturen
Waarom dit belangrijk is voor mensen met fragiele ruggen
Naarmate meer mensen een hogere leeftijd bereiken, komen pijnlijke wervelfracturen door verzwakte botten steeds vaker voor. Een veelgebruikte behandeling, percutane kyphoplastie, kan snel de pijn verlichten, maar kan ook ongewenste bijwerkingen veroorzaken. Deze studie onderzoekt of moderne kunstmatige intelligentie-instrumenten, waaronder grote taalmodellen vergelijkbaar met populaire chatbots, artsen kunnen helpen voorspellen welke patiënten na de behandeling meer kans hebben op deze complicaties.
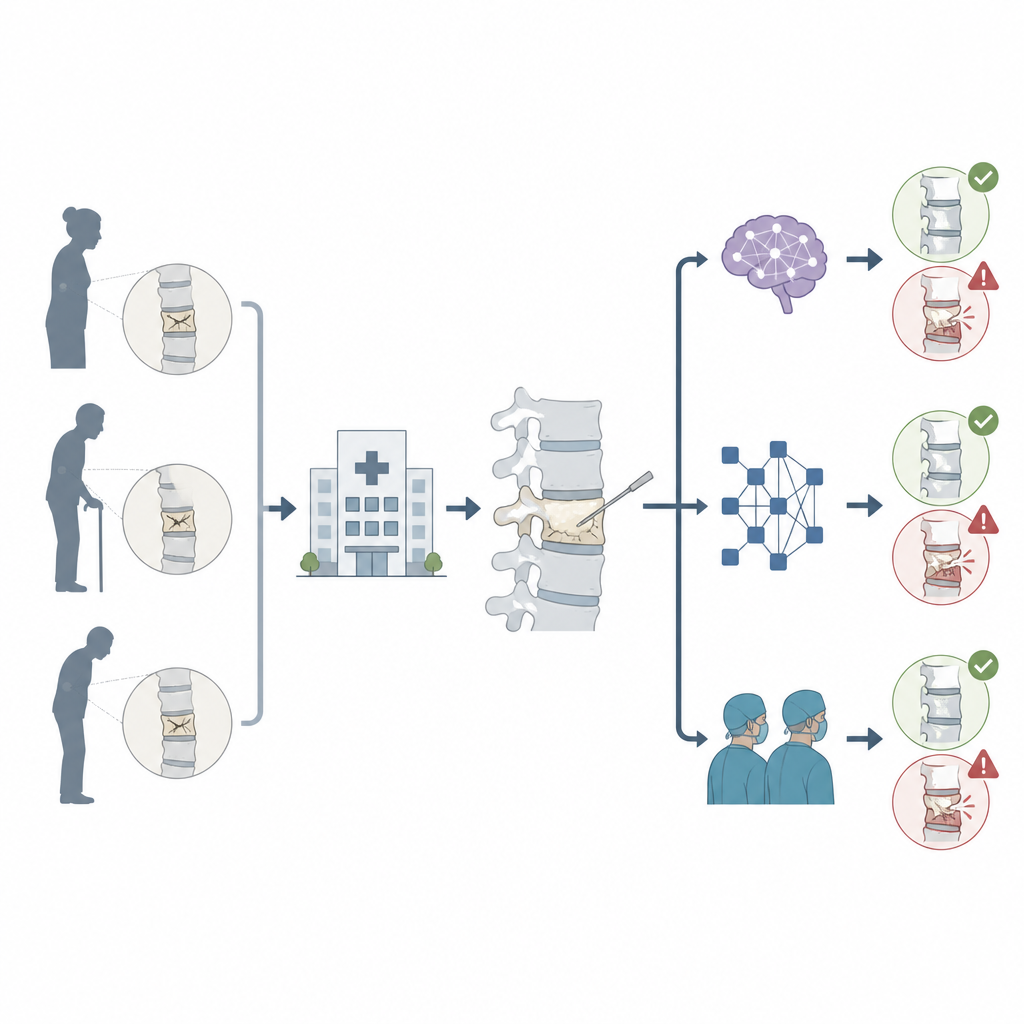
Het rugprobleem en de gebruikelijke oplossing
Osteoporotische wervelcompressiefracturen ontstaan wanneer verzwakte botten in de wervelkolom inzakken, vaak na een kleine val of zelfs door eenvoudige dagelijkse activiteiten. Percutane kyphoplastie is bedoeld om deze gebroken wervels te stabiliseren door een ballon in te brengen en de ruimte op te vullen met botcement, wat meestal de pijn vermindert en enig herstel van de hoogte van de verplette wervel geeft. Cement kan echter soms uit het bot lekken en er kunnen maanden later nieuwe fracturen optreden op andere niveaus van de wervelkolom. Deze complicaties kunnen ernstige problemen veroorzaken, waaronder zenuwbeschadiging, longproblemen en aanhoudende pijn, dus artsen zijn gebrand op hulpmiddelen die patiënten met hoog risico vóór de operatie kunnen identificeren.
Oude computermodellen en menselijke beoordeling
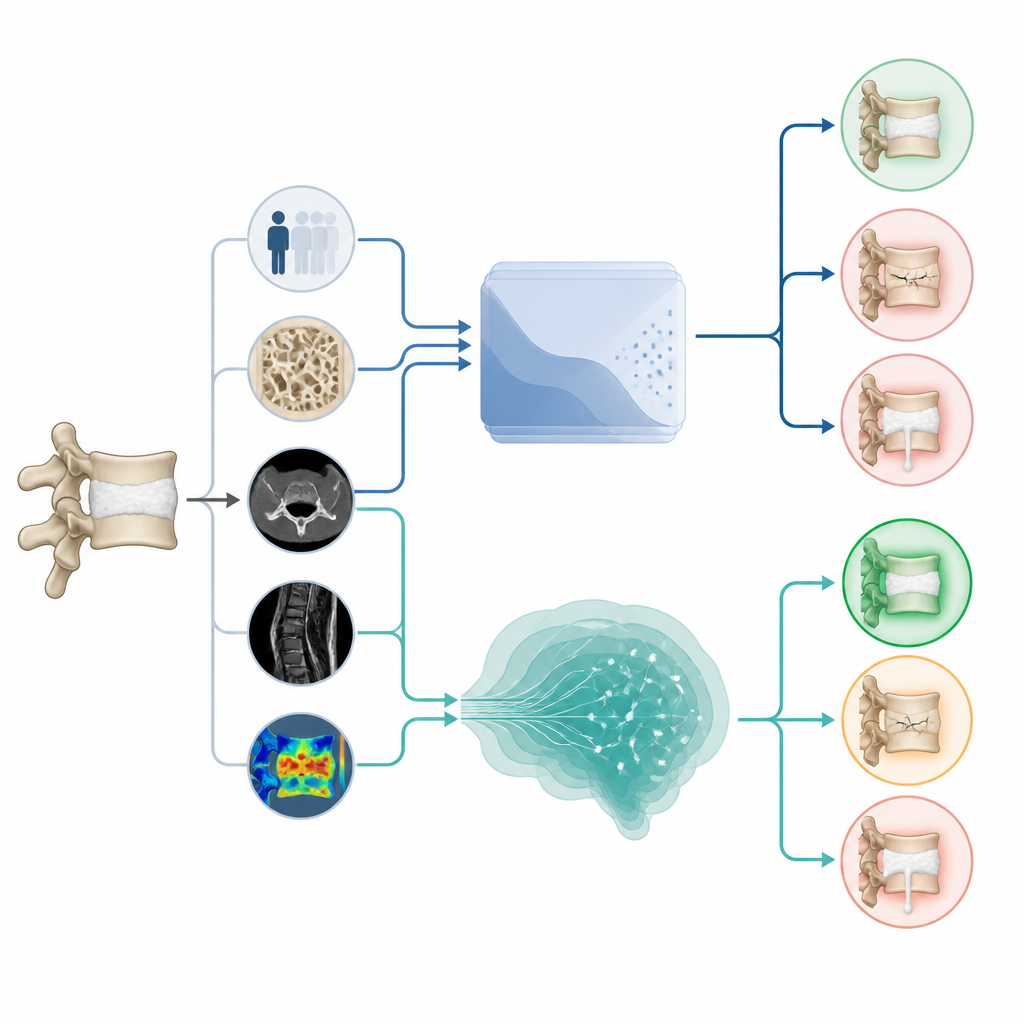
Vóór de opkomst van grote taalmodellen bouwden onderzoekers traditionele machine learning-systemen die patronen leerden uit patiëntendossiers en beeldvorming. Deze systemen kunnen de kans op cementlekkage of nieuwe fracturen inschatten door veel details te combineren, zoals leeftijd, botdichtheid, fractuurvorm en hoe het cement verdeeld is. Tegelijkertijd vormen ervaren wervelchirurgen hun eigen oordeel na het bekijken van dezelfde informatie. Hoewel deze oudere computermodellen vaak goed presteren, vereisen ze zorgvuldige training, technische expertise en rekenmiddelen, wat hun gebruik in alledaagse ziekenhuizen kan beperken.
Chatbots op de proef stellen
In deze studie verzamelden onderzoekers gegevens van meer dan duizend patiënten die behandeld waren met kyphoplastie in een groot ziekenhuis in Peking. Voor elke patiënt registreerden ze standaard klinische en beeldvormingsgegevens en vroegen vervolgens twee grote taalmodellen, een reeks traditionele machine learning-modellen en twee wervelchirurgen om te voorspellen of botcement zou lekken en of er later nieuwe fracturen zouden optreden. De chatbots werden op twee manieren getest. In een zero-shot setting kregen ze simpelweg de casusgegevens en werd om een voorspelling gevraagd. In een few-shot setting kregen ze eerst een kleine set voorbeeldcases met bekende uitkomsten te zien, om te onderzoeken of leren van deze voorbeelden hun antwoorden zou verbeteren.
Wat de computers en chirurgen goed en fout hadden
Voor het voorspellen van cementlekkage kort na de operatie presteerden de grote taalmodellen redelijk goed. Hun resultaten leken op die van de beste traditionele computermodellen en waren iets beter dan die van de chirurgen die op zichzelf werkten. Bij het voorspellen van nieuwe fracturen maanden later hadden de chatbots het echter moeilijk. Hun eerste pogingen waren slecht en sterk bevooroordeeld richting de veronderstelling dat bijna iedereen een nieuwe fractuur zou krijgen. Het geven van voorbeeldcases hielp enigszins, maar traditionele machine learning, met name een model genaamd support vector machine, presteerde nog steeds betrouwbaarder. De chatbots faalden ook wanneer hen gevraagd werd specifieke subtypes van complicaties te identificeren, zoals precies waar het cement lekte of welke wervel als volgende zou breken.
Hulp voor artsen, maar nog geen zelfstandig instrument
Een interessante bevinding was dat chirurgen soms voordeel hadden van de uitleg van de chatbots, maar alleen bij taken waarbij de modellen al redelijk goed presteerden. Wanneer de onderliggende voorspellingen zwak waren, zoals voor langetermijnfracturen, verbeterden de verklaringen de beslissingen van artsen niet. Over het geheel genomen toont de studie aan dat huidige grote taalmodellen nuttige ondersteuning kunnen bieden voor bepaalde kortetermijnrisico's na kyphoplastie, maar ze zijn nog niet betrouwbaar genoeg om bestaande computermodellen of deskundig oordeel te vervangen. Vooralsnog moeten ze worden gezien als vroege hulpverleners die nog verfijning, betere training met medische gegevens en nauwere integratie met beeldvormingshulpmiddelen nodig hebben voordat ze veilig de echte wereld van wervelkolomzorg kunnen leiden.
Bronvermelding: Wang, T., Chen, R., Liang, M. et al. Comparative performance of LLMs and machine learning in predicting complications after percutaneous kyphoplasty for osteoporotic vertebral compression fractures. npj Digit. Med. 9, 401 (2026). https://doi.org/10.1038/s41746-026-02588-4
Trefwoorden: osteoporotische wervelfracturen, percutane kyphoplastie, grote taalmodellen, machine learning in de geneeskunde, voorspelling van chirurgisch risico