Clear Sky Science · nl
Een ingebouwd deep-learningkader voor realtime geweldsdetectie en waarschuwingen
Waarom slimme camera’s van belang zijn voor de alledaagse veiligheid
Gevechten en aanvallen op straat, op scholen en in het openbaar vervoer ontvouwen zich vaak in enkele seconden, veel te snel voor menselijke operatoren om elk bewakingsbeeld te scannen en hulp in te roepen. Deze studie introduceert een methode waarmee kleine, goedkope computers—apparaten zo bescheiden als een Raspberry Pi—video in realtime kunnen bekijken en automatisch waarschijnlijk gewelddadig gedrag markeren. Door krachtige video‑analysetechnieken samen te persen tot een efficiënt systeem dat op het apparaat draait, laat het werk zien hoe bestaande camera’s snellere en betrouwbaardere waarnemers kunnen worden zonder afhankelijk te zijn van verre datacenters of voortdurende menselijke aandacht.
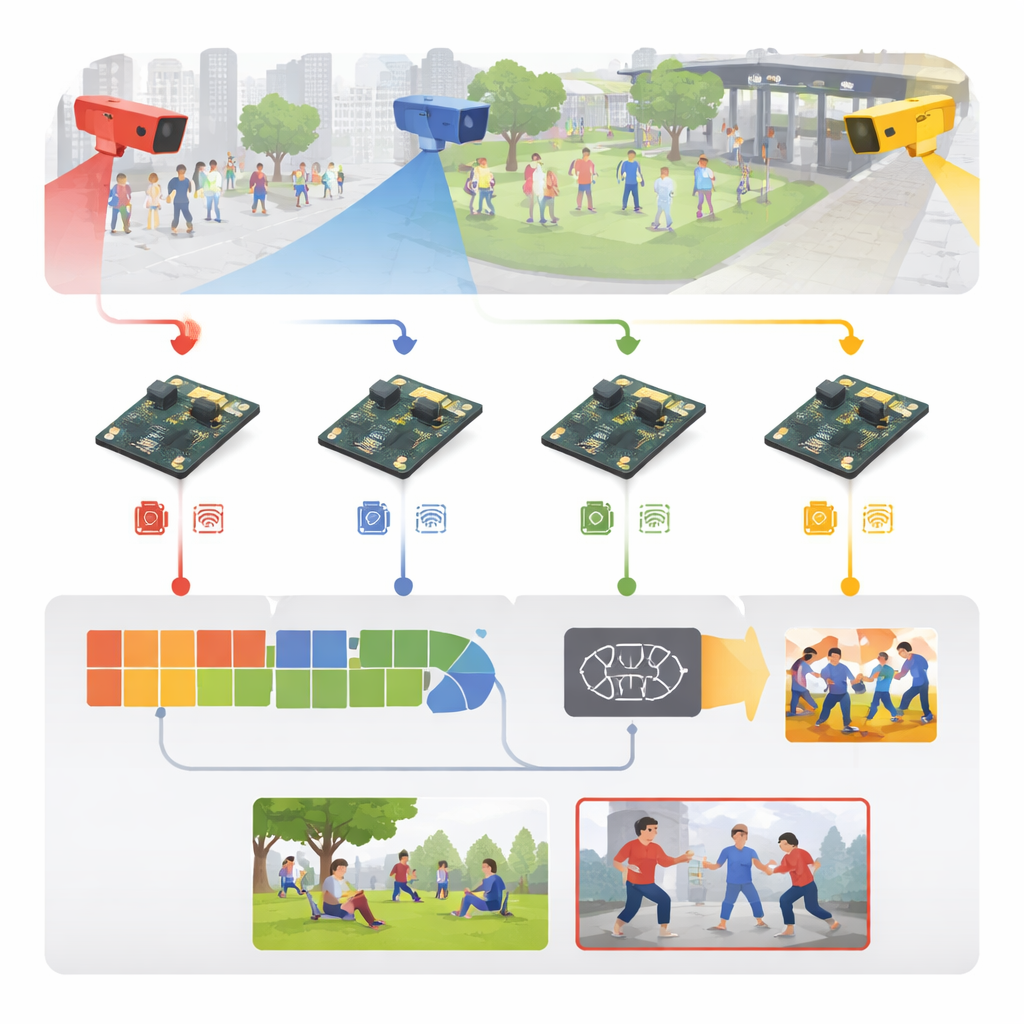
Ruwe video omzetten in vroegtijdige waarschuwingen
Het systeem begint met gewone bewakingsbeelden van locaties zoals sportarena’s, trottoirs, campuspaden en binnencorridors. In plaats van al die video naar een centrale server te streamen, stuurt elke camera zijn frames direct naar een nabijgelegen ingebedde kaart. Daar worden binnenkomende frames gestandaardiseerd—van formaat veranderd, opgeschoond en tijdens de training licht gemuteerd met spiegelen, rotaties en helderheidsaanpassingen—zodat het model leert omgaan met verschillende verlichting, gezichtspunten en mensenmassa’s. De auteurs bouwen ook een rijke mix van trainingsmateriaal: vijf bekende openbare datasets plus een nieuwe verzameling met zes categorieën die stoten, trappen, wapengerelateerde aanvallen, massa‑geweld, wegrennen en normale interacties omvat.
Hoe het compacte brein in het kastje werkt
In het hart van het systeem bevindt zich een gestroomlijnde twee‑traps leerengine. Eerst scant een lichtgewicht beeldmodule elk frame op aanwijzende visuele signalen—lichaamscontouren, arm‑ en beenposities en bewegingsranden—met kostenbesparende convolutieoperaties geleend uit mobiele‑telefonievisionmodellen. Daarna bekijkt een tweede module een korte reeks frames om te begrijpen hoe die signalen in de tijd veranderen, en zo het verschil vast te leggen tussen bijvoorbeeld een vriendelijke tik en een stoot. Dit gebeurt met een efficiënte recurrente structuur die recente beweging onthoudt zonder de zware rekenlast van omvangrijkere videonetwerken. Een eenvoudige eindlaag zet dit spatio‑temporele begrip om in één van zes activiteitslabels, waarmee gewone beweging wordt gescheiden van waarschijnlijke agressie.
Deep learning passend maken voor een klein, energiezuinig bord
Een slim model ontwerpen is slechts de helft van het verhaal; het daadwerkelijk snel laten draaien op een handpalmgroot computerbord is de echte uitdaging. De auteurs behandelen het hele systeem als een engineeringpipeline: ze beginnen met een versie getraind op een krachtige grafische werkplek, zetten die om naar een draagbaar formaat en krimpen hem agressief in. Numerieke precisie wordt verlaagd zodat gewichten een kwart van het oorspronkelijke geheugen innemen, en overbodige delen van het netwerk worden weggeknipt. Met gespecialiseerde optimalisatietools buiten het apparaat genereren ze een getuned model dat efficiënt op de Raspberry Pi kan worden uitgevoerd met een geoptimaliseerde runtime. Het resultaat is een systeem dat ongeveer 26 videoframes per seconde verwerkt met ruwweg 38 milliseconden vertraging per frame, terwijl het slechts enkele watts verbruikt—snel en zuinig genoeg voor continue inzet in het veld.

Testen, vertrouwen en beperkingen van machinale beoordeling
Om te beoordelen of hun compacte waarnemer zowel nauwkeurig als betrouwbaar is, hebben de onderzoekers hem aan een reeks tests onderworpen. Over benchmarkverzamelingen van ijshockeybanen tot stadsstraten, en op hun eigen zesklassen‑dataset, labelde het systeem gebeurtenissen correct in ongeveer 97 van de 100 gevallen en toonde het een goede balans tussen het opvangen van gewelddadige daden en het vermijden van valse alarmen. Vergelijkingen met meer uitgebreide videomodellen—zoals volledige 3D‑convolutionele netwerken en transformer‑gebaseerde ontwerpen—lieten zien dat deze slanke aanpak hun nauwkeurigheid kan evenaren of overtreffen terwijl veel minder rekencapaciteit wordt gebruikt. Het team visualiseerde ook waar het model ‘‘kijkt’’ binnen elk frame en ontdekte dat de aandacht zich van nature concentreert op bewegende ledematen en nauwe contacten tussen mensen, in plaats van irrelevante achtergronddetails, wat vertrouwen in de beslissingen vergroot.
Wat dit betekent voor veiligere, slimere ruimtes
De hoofdboodschap van de studie is niet dat er een geheel nieuw type neuraal netwerk is uitgevonden, maar dat is aangetoond hoe bewezen technieken kunnen worden verpakt in een praktisch realtime‑instrument voor bescheiden hardware. Door zorgvuldig modelontwerp, datavoorbereiding en compressie tijdens deployment in balans te brengen, leveren de auteurs een ingebed systeem dat live video kan monitoren, waarschijnlijk geweld kan herkennen en waarschuwingen kan geven met lage vertraging en laag energieverbruik. Ze erkennen ook openstaande uitdagingen: het systeem kan nog steeds in de war raken door slechte verlichting, drukke scènes of snelle, sportachtige bewegingen, en elke dergelijke technologie moet worden ingezet met aandacht voor privacy, bias en menselijke supervisie. Desondanks wijst het werk op een toekomst waarin veel gewone camera’s worden gekoppeld aan kleine, stille computers die helpen gevaar eerder te signaleren en snellere, beter geïnformeerde reacties mogelijk maken.
Bronvermelding: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Trefwoorden: gewelddetectie, ingebedde vision, edge-AI, video‑toezicht, deep learning