Clear Sky Science · nl
CNN-LSTM-model geoptimaliseerd door verbeterd muszoekalgoritme voor productievoorspelling van olieputten
Slimmere planning voor ondergrondse energie
Olie- en gasbedrijven moeten maanden van tevoren weten hoeveel olie een put zal produceren om investeringen te plannen, onderhoud in te plannen en verspilling van water, energie en geld te voorkomen. Toch gedragen echte putten zich op complexe, veranderlijke manieren die moeilijk te vangen zijn met traditionele formules. Deze studie presenteert een nieuwe benadering met kunstmatige intelligentie (AI) die leert van het eerdere gedrag van individuele putten om hun toekomstige productie nauwkeuriger en betrouwbaarder te voorspellen.
Waarom het voorspellen van een enkele put zo moeilijk is
De hoeveelheid olie die een enkele put kan leveren hangt af van vele wisselende factoren: de geologie van het gesteente, hoe water in het reservoir wordt geïnjecteerd, hoe de pomp presteert en hoe vloeistoffen zich in de loop van de tijd ondergronds verplaatsen. Klassieke technische modellen kunnen veel van deze fysica beschrijven, maar ze vereisen enorme hoeveelheden data en lange opzettermijnen, en worstelen nog steeds met rommelige, echte-wereldveranderingen. Recente machine-learningmethoden, die patronen direct uit gegevens leren, hebben de voorspellingen verbeterd—maar ze hebben vaak zorgvuldige handmatige afstemming door experts nodig. Het kiezen van de juiste modelinstellingen, of hyperparameters, kan tijdrovend, subjectief en vatbaar voor vastlopen in suboptimale oplossingen zijn.
Patronen combineren in ruimte en tijd
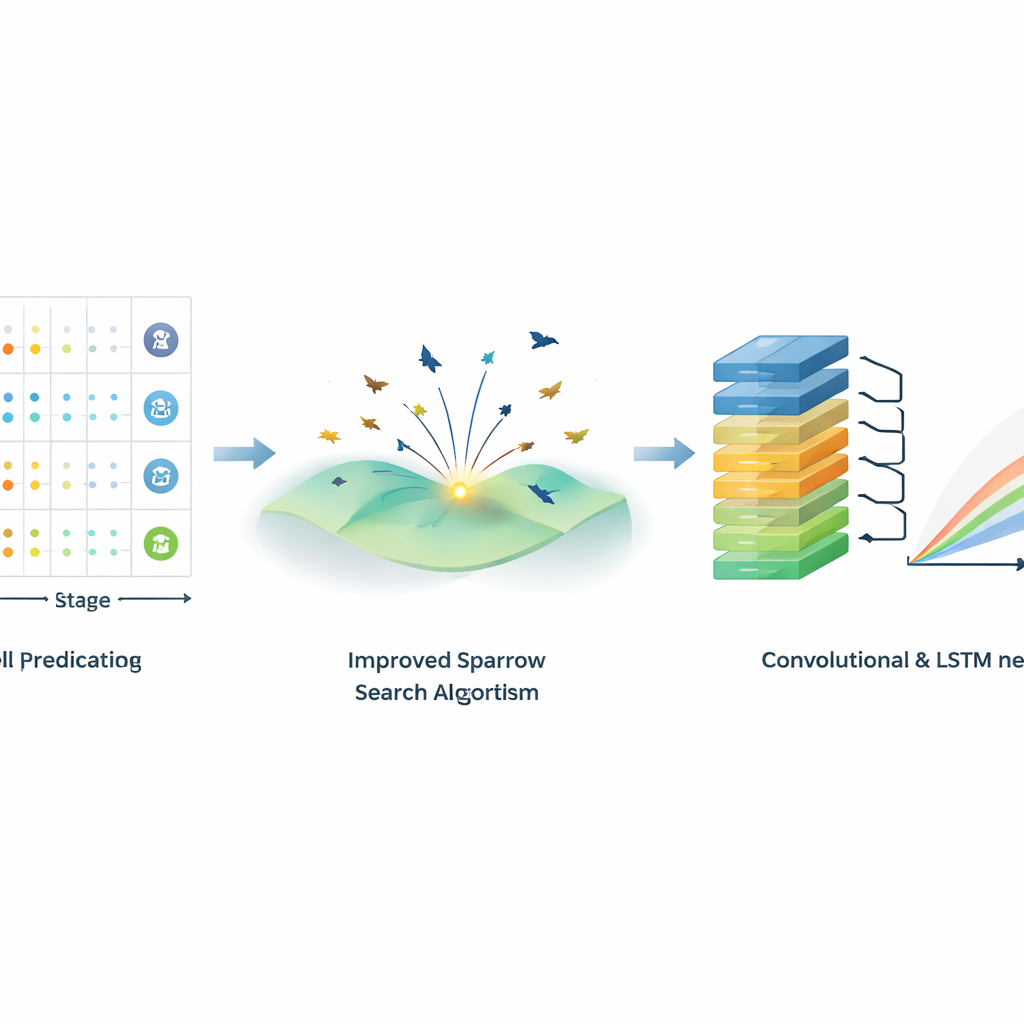
De auteurs bouwen voort op twee krachtige AI-instrumenten. Convolutionele neurale netwerken (CNN's) zijn erg goed in het herkennen van lokale patronen en kenmerken in gegevens, terwijl long short-term memory (LSTM)-netwerken zijn ontworpen om te volgen hoe signalen zich over lange tijdsintervallen ontwikkelen. Door CNN en LSTM te combineren kan het model eerst nuttige kortetermijnpatronen uit meerdere bedieningssignalen 'destilleren' en vervolgens volgen hoe die patronen maand na maand verlopen. De invoer omvat dagelijkse waterproductie, pomp-efficiëntie, watercut, productietijd en pompdiepte—gekozen met een standaard statistische test (Pearson-correlatie) om alleen de variabelen te behouden die werkelijk relevant zijn voor olieopbrengst. Het enkele voorspeldoel is de gemiddelde maandelijkse olieproductie van een gegeven put.
Een slimmere manier om het AI-model af te stemmen
De sleutelinnovatie is een verbeterde versie van het muszoekalgoritme, een techniek geïnspireerd op hoe vogels gezamenlijk naar voedsel zoeken. In deze aanpak 'vliegen' veel kandidaatoplossingen door de ruimte van mogelijke modelinstellingen en delen ze informatie over veelbelovende gebieden. Het verbeterde musalgoritme (ISSA) verfijnt drie kernelementen: het gebruikt een speciale chaotische methode om beginpunten gelijkmatig te verspreiden, en het verbetert hoe de virtuele 'producenten' en 'predatoren' bewegen tijdens hun verkenning. Deze aanpassingen vergroten de zoekruimte, versnellen convergentie naar goede instellingen en verkleinen de kans om vast te lopen in middelmatige oplossingen. ISSA wordt vervolgens gebruikt om automatisch kritische CNN-LSTM-hyperparameters af te stemmen, zoals de grootte en het aantal convolutiefilters en de grootte van de verborgen lagen.
Testen op echte putten in een tight-reservoir
Om te zien hoe goed het nieuwe model in de praktijk werkt, pasten de onderzoekers het toe op een tight zandsteenreservoir in het Ordosbekken in China, met gebruik van vijf jaar aan gegevens van twee representatieve putten, TB987 en TB990. De gegevens werden gesplitst in een trainingsgedeelte om het model te leren en een testgedeelte om de voorspellingen te evalueren. De auteurs vergeleken hun ISSA-CNN-LSTM-aanpak met verschillende alternatieven: versies die alleen LSTM of alleen CNN gebruiken, modellen afgestemd met de oorspronkelijke musmethode, en modellen afgestemd met andere gangbare zwermoptimizers zoals particle swarm, fruit fly en grey wolf algoritmen. Over meerdere standaard foutmaten produceerde het verbeterde model consequent voorspellingen die de echte productiekrommen nauwer volgden en met kleinere fluctuaties in fout.
Wat de verbeterde voorspellingen voor de operatie kunnen betekenen
De hogere nauwkeurigheid van het ISSA-CNN-LSTM-model is niet louter een academische verbetering; het heeft directe operationele toepassingen. Op korte termijn kunnen betrouwbaardere maandelijkse voorspellingen sturen hoeveel water geïnjecteerd moet worden en hoe middelen tussen putten verdeeld worden, wat helpt om een stabiele productie te handhaven. Wanneer de werkelijke productie te ver afwijkt van het voorspelde bereik, kunnen operators dit als een vroeg waarschuwingssignaal beschouwen en pompen inspecteren, zoeken naar onverwachte doorbraak van water, of de reservoircondities herbeoordelen. Op langere termijn helpen de modelvoorspellingen inzicht te geven in hoe snel een reservoir afneemt, wat beslissingen ondersteunt over wanneer een put gestimuleerd moet worden, nieuwe putten geboord moeten worden of het ontwikkelingsplan veranderd moet worden.
Heldere inzichten in toekomstige olie uit data
In eenvoudige termen toont dit werk aan dat het automatisch laten afstemmen van een gecombineerd CNN–LSTM-netwerk met een verbeterde, door vogels geïnspireerde zoekmethode individuele-putvoorspellingen zowel scherper als stabieler maakt. Voor de twee testputten werden de fouten van het model gemiddeld teruggebracht tot ongeveer één procent, en de overeenkomst tussen voorspelde en werkelijke productie was vrijwel één-op-één. Met verdere ontwikkeling op grotere datasets van putten en integratie met andere tijdbreekstools, zouden benaderingen zoals ISSA-CNN-LSTM praktische beslissingsmiddelen kunnen worden, die oliewinningbedrijven helpen meer informatie—en waarde—uit de data te halen die ze al verzamelen.
Bronvermelding: Zhang, R., Guo, L., Sun, J. et al. CNN-LSTM model optimized by improved sparrow search algorithm for oil well production prediction. Sci Rep 16, 13972 (2026). https://doi.org/10.1038/s41598-026-43674-7
Trefwoorden: voorspelling productie olieput, machine learning, tijdbreeksvoorspelling, optimalisatie-algoritme, reservoirtechniek