Clear Sky Science · nl
Diagnosemodel voor vroege kwaadaardige longknobbeltjes op basis van klinische laboratoriumgegevens
Waarom kleine plekjes in de long ertoe doen
Wanneer een routinematige thoraxscan een klein plekje in de long laat zien, staan artsen en patiënten voor een lastige vraag: is het een vroeg stadium van kanker dat snelle behandeling vereist, of een goedaardige afwijking die veilig kan worden afgewacht? Huidige beeldvormingstests kunnen vaak het verschil niet maken, waardoor sommige mensen onnodig geopereerd worden terwijl bij anderen de diagnose gevaarlijk wordt vertraagd. Deze studie onderzoekt of een eenvoudige bloedtest, geïnterpreteerd met moderne computermethoden, kan helpen om deze long“knobbeltjes” in laag- en hoogrisicogroepen te verdelen.
Beperkingen van huidige scans en bloedtesten
Lage-dosis CT-scans worden tegenwoordig veel gebruikt om mensen met risico op longkanker te screenen omdat ze tumoren kunnen detecteren terwijl ze nog klein zijn. Maar deze scans vinden ook veel goedaardige knobbeltjes, en vrijwel alle positieve bevindingen kunnen uiteindelijk geen kanker blijken te zijn. Traditionele bloedgebaseerde markers die in longklinieken worden gebruikt, hebben dit probleem niet opgelost; ze missen vaak vele vroege kankers en kunnen op zichzelf geen betrouwbare beslissingen sturen. Daardoor vertrouwen artsen vaak sterk op ervaring en subtiele scankenmerken, die per specialist kunnen verschillen.
Immune vingerafdrukken omzetten in aanwijzingen
Eén veelbelovende aanpak is het kijken naar de eigen immuunreactie van het lichaam. Lang voordat een longtumor groot genoeg is om op een scan zichtbaar te zijn, kan het immuunsysteem abnormale eiwitten van kankercellen herkennen en overeenkomende antilichamen produceren. Een paneel van zeven dergelijke autoantilichamen is al goedgekeurd in China en staat bekend als redelijk specifiek voor longkanker, maar het mist nog steeds veel gevallen. De onderzoekers in deze studie vroegen zich af of het combineren van dit antistoffenpaneel met routinematige laboratoriummetingen uit een standaardbloedafname een vollediger beeld van het kankerrisico kan opleveren.
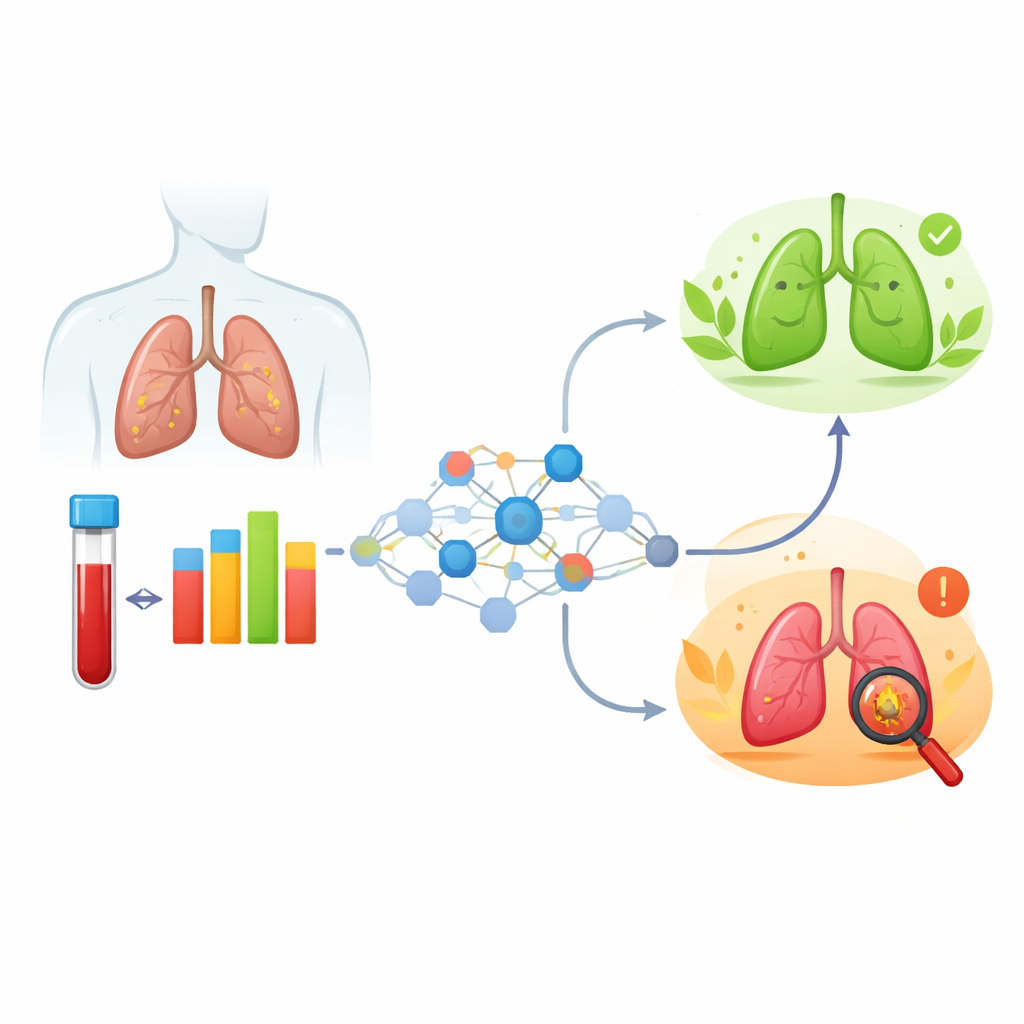
Computers leren patronen herkennen
Het team analyseerde gegevens van 310 patiënten bij wie longknobbeltjes door weefselonderzoek waren bevestigd: 142 hadden kanker in een vroeg stadium en 168 hadden goedaardige aandoeningen zoals littekenweefsel of ontsteking. Van elke persoon verzamelden zij zeven autoantilichamen, basisinformatie zoals geslacht, en een breed scala aan gangbare bloedtestuitslagen, waaronder metingen van bloedcellen, eiwitten en ontstekingsindicatoren. Met een statistische methode om minder nuttige gegevens te verwijderen, beperkten ze de lijst tot 12 kernfactoren. Vervolgens trainden en vergeleken ze 11 verschillende machine-learningbenaderingen, een familie van algoritmen die patronen leren uit voorbeelden in plaats van te vertrouwen op vaste formules.
Een gericht model gebouwd voor de kliniek
Onder alle geteste benaderingen stak een methode genaamd random forest eruit vanwege het evenwicht tussen nauwkeurigheid en stabiliteit bij evaluatie op een onafhankelijke patiëntenpopulatie. Om de toekomstige test praktisch te houden, gebruikten de onderzoekers een uitlegbaarheidstool om te zien welke invoervariabelen het meest bijdroegen aan de beslissingen van het model. Dit stelde hen in staat het model terug te brengen tot slechts vijf bloedgebaseerde kenmerken: één veelvoorkomend stollingseiwit bekend als fibrinogeen en vier van de autoantilichamen, genoemd p53, SOX2, MAGE A1 en GBU4-5. Zelfs in deze compacte vorm behield het model vrijwel de gehele toegevoegde capaciteit om kwaadaardige van goedaardige knobbeltjes te onderscheiden vergeleken met de volledige 12-factorversie.
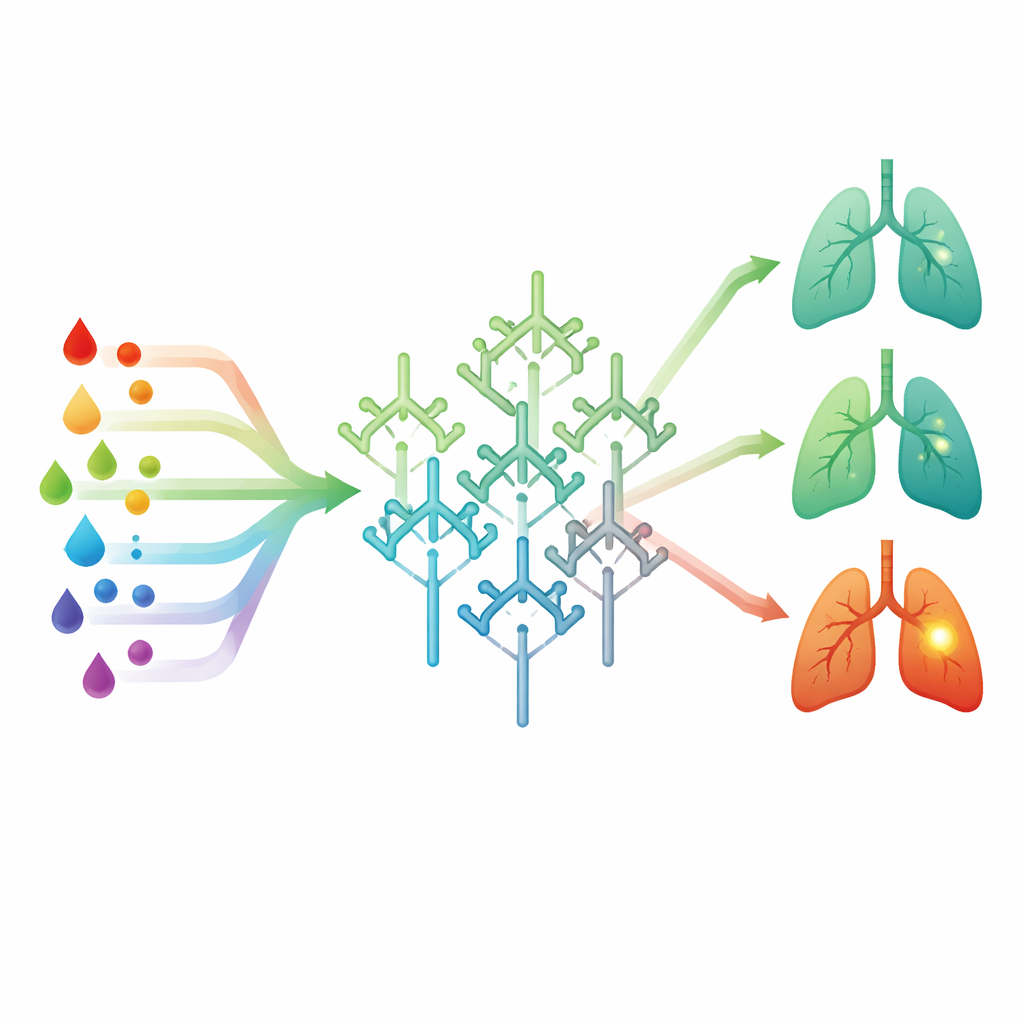
Hoe dit hulpmiddel gebruikt zou kunnen worden
In tests toonde het model een sterke capaciteit om veel echte kankergevallen correct te identificeren terwijl het een hoge specificiteit handhaafde, wat betekent dat de meeste knobbeltjes die het als laag risico beoordeelde inderdaad goedaardig waren. De sensitiviteit—hoeveel kankers het detecteert—lag echter rond twee derde, wat te laag is om als zelfstandige screeningstest te dienen. In plaats daarvan suggereren de auteurs dat het een “extra stem” aan de besluitvormingstafel kan worden: artsen helpen herkennen welke patiënten waarschijnlijk geen kanker hebben en onmiddellijke invasieve procedures mogelijk kunnen vermijden, terwijl beeldvorming en klinisch oordeel blijven bepalen voor de definitieve beslissingen.
Wat dit betekent voor patiënten
Dit onderzoek levert een proof of concept dat informatie die al beschikbaar is uit een routinematige bloedafname, wanneer geïnterpreteerd door een zorgvuldig gevalideerd machine-learningmodel, kan helpen het risico dat een longknobbeltje kwaadaardig is te verduidelijken. De auteurs bouwden zelfs een webgebaseerde rekenhulp zodat andere groepen de aanpak kunnen testen. Vooralsnog blijft het werk experimenteel: het werd uitgevoerd in één ziekenhuis, met een bescheiden aantal patiënten en voornamelijk bij één type longkanker. Grotere, multicenterstudies zullen nodig zijn om aan te tonen of het model daadwerkelijk de zorg verbetert en betrouwbaar is in de dagelijkse praktijk. Als die toekomstige tests slagen, zouden dergelijke hulpmiddelen onnodige operaties kunnen verminderen, de aandacht richten op patiënten die het meest zorg nodig hebben, en het ontdekken van een klein plekje in de long iets minder beangstigend maken.
Bronvermelding: Liu, L., Li, H., Miao, Y. et al. Diagnosis model of early malignant pulmonary nodules based on clinical laboratory data. Sci Rep 16, 12172 (2026). https://doi.org/10.1038/s41598-026-42111-z
Trefwoorden: longkanker, longknobbeltjes, autoantilichamen, machine learning, bloed-biomarkers