Clear Sky Science · nl
K-means-clustering toegepast op vegetatie-indices voor het in kaart brengen van gecultiveerde gebieden met hoogresolutie Marokkaanse Mohammed VI-satellietbeelden
Waarom slimmer gemaakte gewaskaarten ertoe doen
Het voeden van een groeiende wereldbevolking hangt af van het bijna in realtime weten wat er daadwerkelijk op de grond groeit. Boeren en overheden hebben betrouwbare kaarten nodig van waar gewassen zijn aangeplant, welke percelen kaal zijn en hoe die patronen van seizoen tot seizoen veranderen. Deze studie laat zien hoe een Marokkaanse aardobservatiesatelliet, gecombineerd met een eenvoudige vorm van kunstmatige intelligentie, ruwe beelden kan omzetten in zeer nauwkeurige kaarten van gecultiveerd land zonder dat er legioenen mensen nodig zijn om data met de hand te labelen.
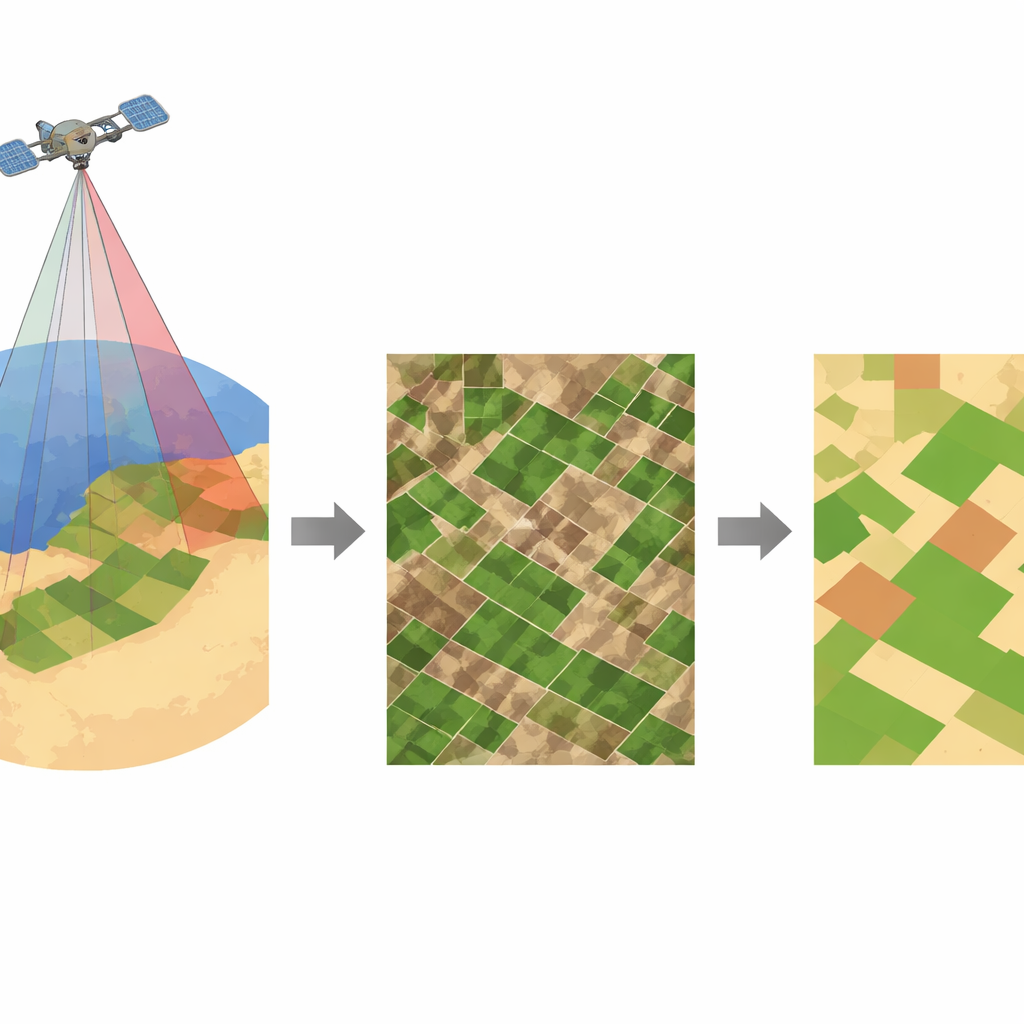
Boerderijen zien vanuit de ruimte
Het werk concentreert zich op het Mohammed VI-satellietsysteem, een paar Marokkaanse satellieten die de aarde in een zon‑synchrone baan omcirkelen. Ze leggen zeer scherpe beelden vast in vier kleuren, waaronder nabij‑infrarood licht, met een resolutie van een halve meter—fijn genoeg om individuele kleine percelen en zelfs rijen bomen te onderscheiden. De auteurs richtten zich op een landbouwgebied van 175 hectare in de regio Fes–Meknes in het noorden van Marokko, waar percelen met granen, maïs, olijven, amandelen, druiven en groenten naast onooglijke percelen en schaarse begroeiing liggen. Die diversiteit maakt het gebied ideaal om gereedschappen te testen die gecultiveerd land van de rest moeten scheiden.
Kleuren omzetten in aanwijzingen
Ruwe satellietbeelden zijn slechts rasters van helderheidswaarden in verschillende kleurbanden. Om die rasters informatiever te maken, berekenen onderzoekers vaak “vegetatie‑indices” die meerdere kleuren samensmelten tot één getal dat de plantgezondheid of het watergehalte weerspiegelt. Deze studie gebruikt de bekende Normalized Difference Vegetation Index, die bladrijke, chlorofylrijke vegetatie accentueert, en de Modified Normalized Difference Water Index, die gevoelig is voor vochtverschillen met gebruik van groen en nabij‑infrarood licht. Samen met de oorspronkelijke nabij‑infraroodband vormen deze drie lagen een compacte beschrijving van de vegetatie‑ en vochtstatus van elke pixel, wat veel rijkere informatie levert dan één enkele band alleen.
Het laten groeperen van de data
In plaats van een complex model te trainen met duizenden met de hand gelabelde voorbeelden, wendden de onderzoekers zich tot K‑means, een eenvoudige clustering‑algoritme uit het onbegeleide machine learning‑vak. K‑means zoekt patronen in de data en groepeert pixels in een vast aantal clusters met vergelijkbare spectrale eigenschappen. Na basisvoorbewerking—het extraheren van de relevante banden, het berekenen van de twee indices, het stapelen ervan en het schalen van alle waarden tussen nul en één—gaf het team K‑means de opdracht precies drie clusters te maken. Deze werden vervolgens geïnterpreteerd als achtergrond (gebieden buiten de percelen of zonder bruikbaar signaal), kale grond en gewasgedomineerde gebieden. Omdat de methode onbegeleid is, kan ze op nieuwe beelden worden toegepast zonder extra gelabelde trainingsdata.

De methode aan de tand voelen
Om te beoordelen hoe goed de aanpak werkte, maakten de auteurs een gedetailleerde referentiekaart door gecultiveerde percelen handmatig te omlijnen in geografische informatiesoftware, gebruikmakend van hetzelfde hoogresolutiebeeld. Ze vergeleken vervolgens vier manieren om het aandeel gecultiveerd land te schatten: een eenvoudige regel gebaseerd alleen op nabij‑infrarood helderheid, een regel gebaseerd op de vegetatie‑index NDVI, een standaard K‑means uitgevoerd op de originele kleurbanden, en hun nieuwe “spectrale K‑means” die de gecombineerde index‑en‑infraroodgegevens clustert. De werkelijke gecultiveerde fractie van het studiegebied was 71,07 procent. Nabij‑infrarood‑drempeling onderschatte dit met 65,59 procent, NDVI alleen gaf 66,13 procent, en standaard K‑means bereikte 67,18 procent. De spectrale K‑means‑aanpak kwam het dichtstbij, met 72,07 procent, wat overeenkomt met een relatieve fout van slechts 1,41 procent—meerdere malen beter dan de concurrerende methoden.
Wat dit betekent voor toekomstige landbouw
Voor boeren, waterbeheerders en planners biedt dit soort geautomatiseerde, nauwkeurige kaartvorming een praktische manier om percelen over grote regio’s te monitoren zonder kostbare schouwrondes of enorme gelabelde datasets. Door betrouwbaar gecultiveerd van niet‑gecultiveerd land te onderscheiden en te laten zien waar de vegetatie welig tiert of juist gestrest is, kan de methode precisieirrigatie ondersteunen, kunstmestgebruik sturen en helpen landgebruikverandering te volgen. Hoewel de huidige validatie op één enkel beeld berust, wijst de aanpak op een toekomst waarin eenvoudige, onbegeleide algoritmen toegepast op hoogresolutie satellietgegevens routinematig kaartjes op perceelschaal opleveren, de voedselproductie verbeteren en tegelijkertijd bijdragen aan een duurzamer gebruik van land en water.
Bronvermelding: Moussaid, A., Bayad, M., Gamoussi, Y. et al. K-means clustering applied to vegetation indices for mapping cultivated areas using high-resolution Moroccan Mohammed VI satellite imagery. Sci Rep 16, 11040 (2026). https://doi.org/10.1038/s41598-026-41167-1
Trefwoorden: precisie-landbouw, satellietbeelden, gewaskaartvorming, onbegeleid leren, vegetatie-indices