Clear Sky Science · nl
Een lichtgewicht multi-schaal detectiekader voor röntgenbeelden met gesuperviseerd contrastief leren
Waarom slimere röntgencontroles ertoe doen
Wie ooit door de beveiliging op een luchthaven is geschoven, weet dat iedere tas snel en nauwkeurig gescand moet worden. Röntgenbeelden zijn echter allesbehalve eenvoudig: messen, flessen, laptops en opladers stapelen zich op elkaar en gevaarlijke voorwerpen kunnen gemakkelijk in de rommel verdwijnen. Dit artikel presenteert een nieuwe methode uit kunstmatige intelligentie (AI) die röntgenapparaten helpt om kleine of overlappende bedreigingen betrouwbaarder te detecteren, terwijl hij nog steeds snel genoeg werkt voor drukke controlepunten.
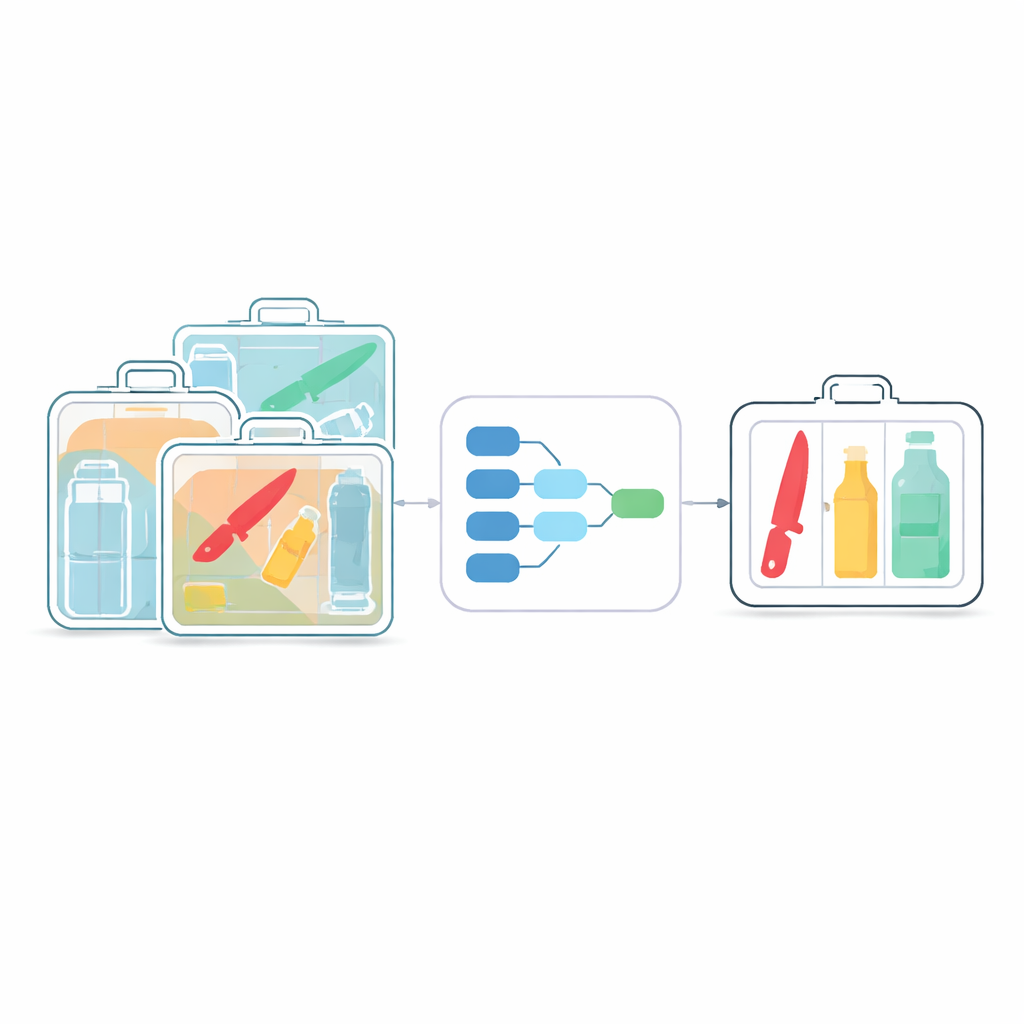
De uitdaging van door de rommel heen zien
Röntgenbeveiligingssystemen zijn de eerste verdedigingslinie op luchthavens, metrostations en andere drukke openbare ruimten. Traditionele menselijke inspectie is traag en vermoeiend, wat het risico op gemiste voorwerpen vergroot. Moderne AI-detectoren zoals de YOLO-familie hebben de geautomatiseerde screening verbeterd, maar ze zijn oorspronkelijk ontworpen voor alledaagse foto’s, niet voor spookachtige, laagcontrast röntgenbeelden. In deze scans overlappen objecten vaak, lijken semi-transparant en variëren sterk in grootte. Kleine messen of flesjes kunnen begraven liggen tussen onschuldige spullen, en veel huidige algoritmen missen ze of vergen zware rekenkracht die moeilijk inzetbaar is op compacte, goedkope apparaten.
Een slanker brein voor röntgenmachines
De auteurs bouwen voort op de populaire YOLOv8-detector en herontwerpen die specifiek voor röntgenbeelden. Hun eerste stap is het netwerk slanker maken met "depthwise separable" convoluties—een technische manier om te zeggen dat het model patronen zuiniger bekijkt. In plaats van grote, dure filters op alle kanalen van het beeld tegelijk toe te passen, breekt het de bewerking op in goedkopere stappen. Deze wijziging verkleint het aantal berekeningen met ongeveer een kwart tot twee vijfde, terwijl de fijne details die nodig zijn om kleine, deels verborgen objecten te zien behouden blijven. Het resultaat is een lichter digitaal „brein” dat in realtime kan draaien op bescheiden hardware, zoals ingebedde processors in scanners.
Het model helpen focussen op wat telt
Het netwerk kleiner maken is niet genoeg; het moet ook selectiever worden. Hiervoor introduceren de onderzoekers een Channel-Spatial Attention Fusion (CSAF)-module. De ene tak van deze module leert welke soorten visuele kenmerken—randen, vormen of materiaalindicaties—globaal het meest informatief zijn, terwijl een andere tak leert waar in het beeld de actie plaatsvindt. In plaats van deze attenties na elkaar toe te passen, verwerkt CSAF ze parallel en fuseert ze vervolgens, zodat het systeem zowel het „wat” als het „waar” tegelijk kan overwegen. Deze aandachtseenheden zijn verweven in een multi-schaal ontwerp dat grove en fijne beelden van de scène combineert, wat bijzonder nuttig is voor het detecteren van piepkleine, overlappende voorwerpen in volle tassen.
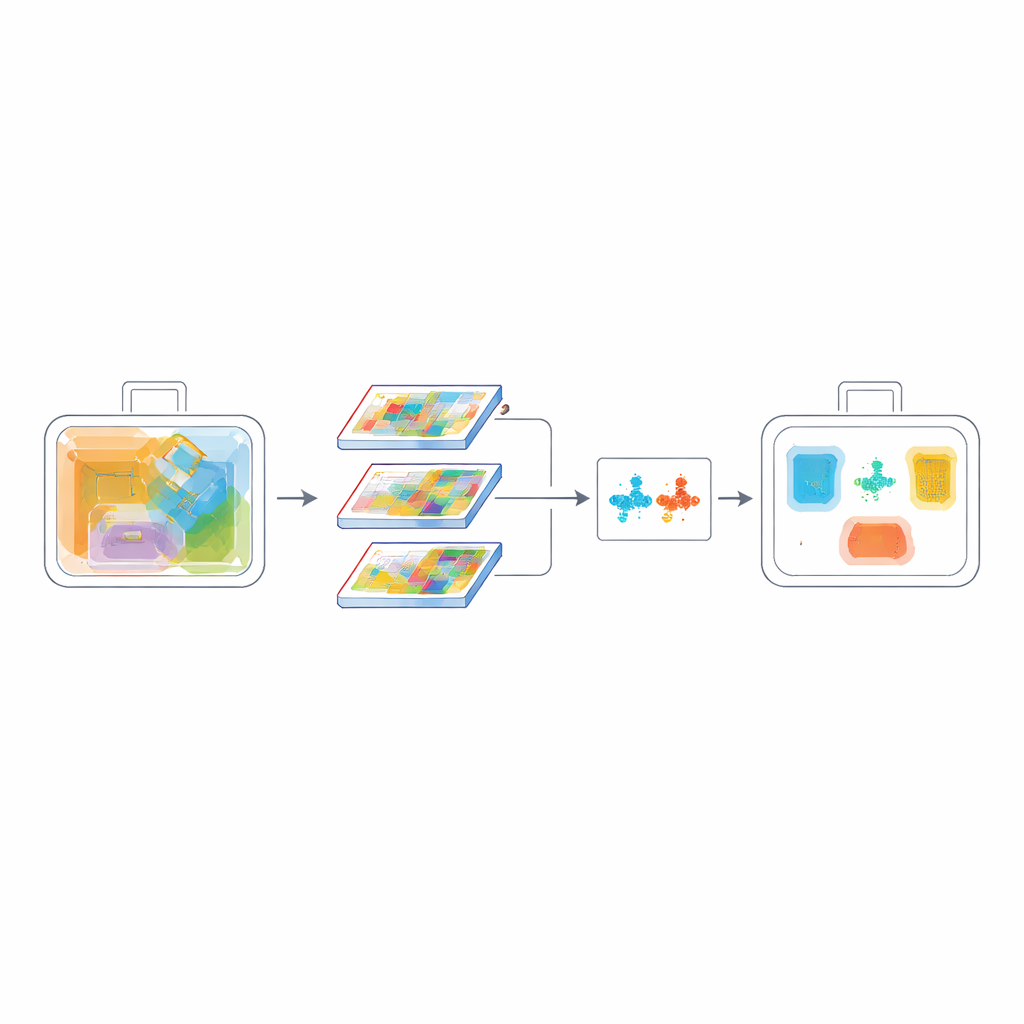
Het systeem leren om dubbelgangers te onderscheiden
Een andere moeilijkheid in röntgenscans is dat veel voorwerpen er vergelijkbaar uitzien: een blikje en een spuitbus, of verschillende soorten messen, kunnen vrijwel identieke omtrekken hebben. Om het model beter te maken in het uit elkaar houden van zulke categorieën voegen de auteurs een contrastieve leerdoelstelling toe. Tijdens training wordt het netwerk aangemoedigd om voorbeelden van dezelfde klasse dichter bij elkaar te brengen in zijn interne representatie, terwijl verschillende klassen verder uit elkaar worden geduwd. Tegelijkertijd helpt een pixelniveau overlapmaat genaamd PIoU bij het fijn afstemmen van de plaatsing en vorm van de voorspelde begrenzingsvakken, wat essentieel is wanneer objecten gekanteld, dicht opeengepakt of slechts gedeeltelijk zichtbaar zijn. Gezamenlijk leren deze verliesfuncties het model niet alleen waar een object zich bevindt, maar ook wat het onderscheidt van verwarrende buren.
Prestaties aantonen in realistische tests
Het team evalueert hun aanpak op twee uitdagende röntgendatasets die echte controlepunten en synthetische bagagescènes met meerdere dreigingscategorieën bevatten. Vergeleken met de standaard YOLOv8-baseline bereikt hun model hogere nauwkeurigheid op strikte overlapmaten terwijl het minder parameters en rekencapaciteit vereist. Het behoudt zeer hoge detectiesnelheden voor scherpe objecten en verbetert de herkenning van transparante of vervormbare items zoals flessen en drankkartons. Precisie–vertrouwens- en recall–vertrouwenscurves laten zien dat zijn voorspellingen stabiel blijven zelfs wanneer de drempel voor het aangeven van een detectie wordt verhoogd, wat betekent dat er minder valse alarmen en minder gemiste bedreigingen zijn. Tests op een tweede dataset die elders is verzameld bevestigen dat het systeem goed generaliseert, een belangrijke vereiste voor inzet in de echte wereld waar tassinformatie en beeldvormingcondities variëren.
Wat dit betekent voor alledaagse reizigers
Voor de leek komt het erop neer dat dit werk een slimmer, zuiniger manier biedt om bagage te scannen. Door een moderne AI-detector zowel lichtgewicht als selectiever te maken, stellen de auteurs röntgenmachines in staat snel te draaien op betaalbare hardware en toch kleine, overlappende of gelijkenis-bedreigingen te onderscheppen. Als dergelijke methoden in de praktijk worden toegepast, kunnen ze helpen wachtrijen te verkorten, onnodige tassencontroles te verminderen en—het allerbelangrijkste—de kans te vergroten dat echt gevaarlijke voorwerpen worden gepakt voordat ze ooit de gate bereiken.
Bronvermelding: Diao, Q., Chan, W., Zain, A.M. et al. A lightweight multi-scale detection framework for X-ray images with supervised contrastive learning. Sci Rep 16, 8635 (2026). https://doi.org/10.1038/s41598-026-38000-0
Trefwoorden: röntgenbeveiliging, objectdetectie, deep learning, luchthavencontrole, computerzicht