Clear Sky Science · nl
Een nieuw gedistribueerd gradiëntalgoritme voor samengestelde constrained optimalisatie over gerichte netwerken
Slimmere besluitvorming zonder één centrale baas
Moderne technologieën — van elektriciteitsnetten en sensornetwerken tot vloten drones — vertrouwen vaak op veel apparaten die samenwerken zonder één centrale controller. Elk apparaat ziet slechts een deel van het geheel, maar de groep als geheel moet toch instemmen met een goede, veilige bedrijfsstand. Dit artikel introduceert een nieuwe manier waarop zulke gedistribueerde systemen efficiënt en betrouwbaar gezamenlijke beslissingen kunnen nemen, zelfs wanneer de onderliggende communicatielinks éénrichtingsverkeer zijn en het probleem lastige beperkingen en scherpe “kosthoeken” bevat.
Waarom veel kleine breinen één groot brein verslaan
Gecentraliseerde optimalisatie — waarbij één krachtige computer alle data verzamelt, één groot probleem oplost en commando’s terugstuurt — is kwetsbaar en moeilijk schaalbaar. Het kan uitvallen als de centrale eenheid wegvalt of vastlopen door communicatietrajecten in grote systemen. Gedistribueerde optimalisatie keert dit beeld om: elke knoop (of agent) bewaart zijn eigen data, werkt zijn lokale beslissing bij en wisselt slechts beperkte informatie uit met nabije buren. De uitdaging is update-regels te ontwerpen zodat, ondanks gedeeltelijke en éénrichtingscommunicatie, alle knopen toch overeenstemming bereiken over een oplossing die globaal optimaal is voor het netwerk.
Lastige problemen met scherpe hoeken en praktische grenzen
De auteurs richten zich op een veeleisende klasse problemen waarbij de totale kosten gladde termen (die geleidelijk veranderen) combineren met niet-gladde termen (die scherpe knikken kunnen veroorzaken), zoals de veelgebruikte l1-norm. Deze niet-gladde onderdelen zijn cruciaal om sparsity en robuustheid te bevorderen in toepassingen zoals compressed sensing, signaalruisonderdrukking en modelafstemming. Daarnaast moet elke knoop lokale gelijkheids- en ongelijkheidsbeperkingen respecteren en binnen toegestane grenzen blijven. Dit alles moet worden afgehandeld over een gericht communicatienetwerk, waarbij informatie van knoop A naar knoop B kan stromen maar niet per se terug. Bestaande methoden veronderstellen doorgaans ongerichte koppelingen, eenvoudigere beperkingen of vaste stapgroottes die moeilijk af te stemmen en minder flexibel zijn.
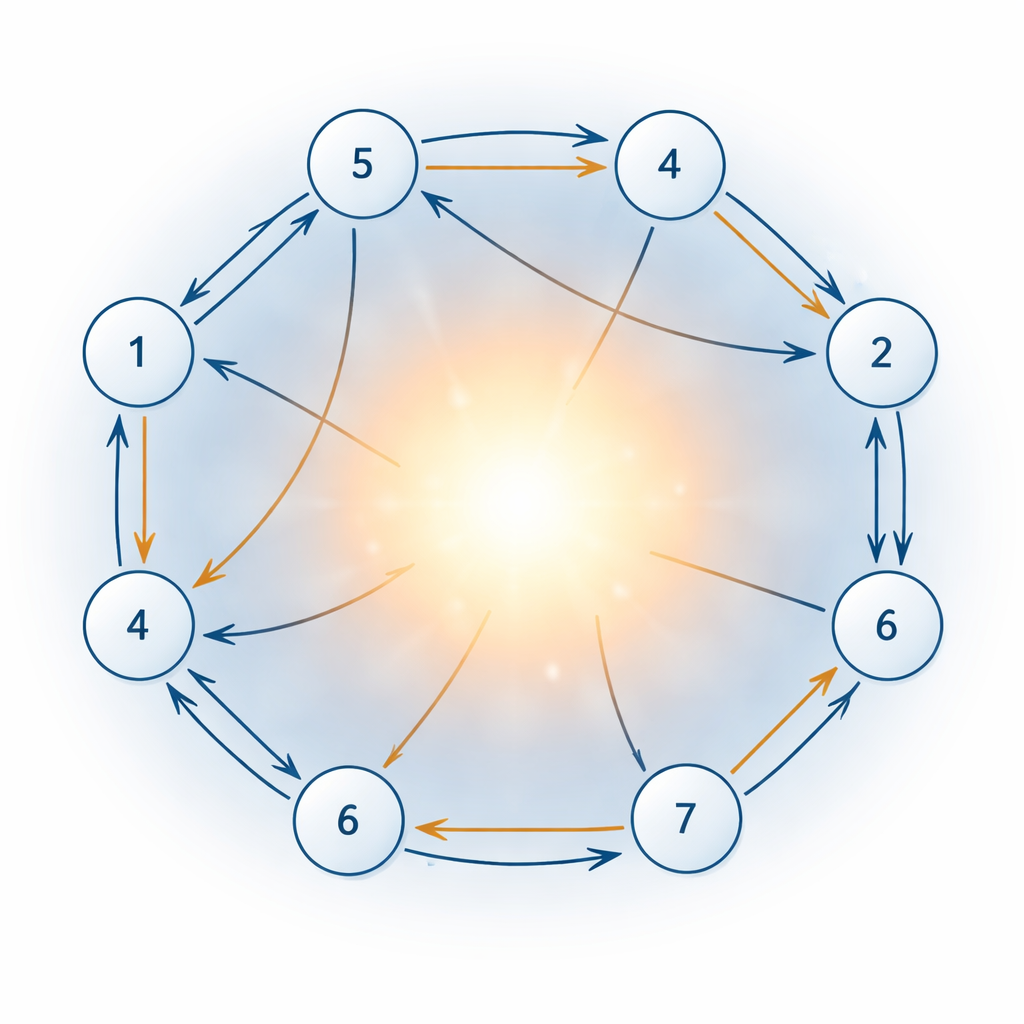
Een nieuwe manier voor knopen om te communiceren en overeen te komen
Om deze moeilijkheden aan te pakken, stelt het artikel een nieuw gedistribueerd gradiëntgebaseerd algoritme voor, toegesneden op samengestelde, geconstrueerde problemen over gerichte netwerken. Elke knoop past herhaaldelijk zijn lokale beslissing aan door een geprojecteerde gradiëntstap te volgen: hij beweegt in een richting die de totale kost verlaagt en projecteert het resultaat vervolgens terug in zijn toegestane gebied zodat beperkingen behouden blijven. Extra variabelen fungeren als interne administratie en helpen het netwerk gelijkheids- en ongelijkheidsvoorwaarden af te dwingen en de niet-gladde l1-term te verwerken. Een belangrijke vernieuwing is een correctiemechanisme dat het onevenwicht veroorzaakt door éénrichtingslinks compenseert, waarbij alleen rij-stochastische gewichten worden gebruikt — wat betekent dat elke knoop alleen hoeft te weten hoe hij informatie ontvangt, niet wie informatie van hem ontvangt.
Flexibele stapgroottes met gegarandeerde convergentie
Een ander kenmerk van de methode is het gebruik van tijdsvariërende maar constante stapgroottes: elke knoop mag binnen een bewijsbaar veilige bandbreedte zijn eigen stap kiezen, in plaats van één gemeenschappelijke vaste waarde te delen. Deze flexibiliteit maakt het afstemmen in de praktijk eenvoudiger en stelt het algoritme in staat zich beter aan te passen aan verschillende lokale omstandigheden. Met gereedschap uit de stabiliteitstheorie bouwen de auteurs een Lyapunov-functie — een soort wiskundige energiemaat — en bewijzen dat deze bij elke iteratie afneemt, zolang de stapgroottes een duidelijke bovengrens respecteren. Dit garandeert dat, vanuit elk startpunt, de beslissingen van alle knopen convergeren naar dezelfde globaal optimale oplossing, zelfs bij aanwezigheid van niet-gladde termen en gemengde beperkingen.
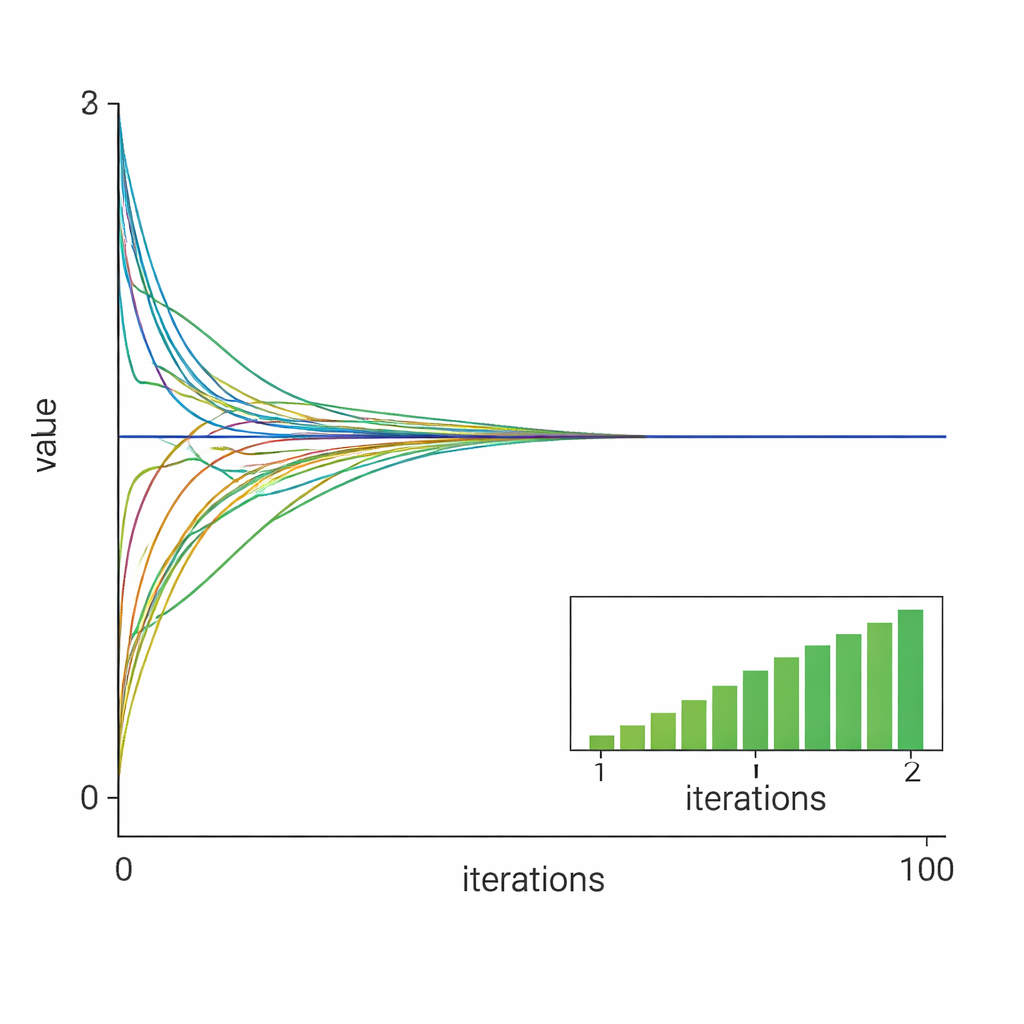
De methode in de praktijk getest
De onderzoekers valideren hun theorie met twee numerieke casestudy’s. In de eerste lossen tien knopen samen een gecontraineerd kwadratisch probleem op met l1-regularisatie, vergelijkbaar met taken in resource-allocatie of sensorfusie. De resultaten tonen aan dat alle lokale variabelen snel samenvloeien naar de gecentraliseerde optimale oplossing en dat het gebruik van een goed gekozen constante stapgrootte leidt tot snellere, bijna lineaire convergentie vergeleken met een afnemende stapgrootte. In de tweede casus pakt de methode een slecht geconditioneerd least-absolute-deviation-probleem aan, dat bekendstaat als moeilijk voor standaardoplossers. Zelfs hier, met slechts vijf knopen en sterk onevenwichtige data, stuurt het algoritme betrouwbaar alle agenten naar de werkelijke oplossing.
Wat dit betekent voor reële systemen
Kort gezegd levert het artikel een robuust recept om groepen netwerkeenheden moeilijke optimalisatieproblemen gezamenlijk te laten oplossen zonder een mastercontroller, terwijl praktische beperkingen worden gerespecteerd en er gewerkt wordt over éénrichtingscommunicatelinks. De methode is toepasbaar op energiesystemen, sensornetwerken en gedistribueerde machine learning-taken waar beperkingen en sparsity belangrijk zijn. Omdat het alleen lokale buurinformatie vereist en duidelijke regels biedt voor het kiezen van stapgroottes, is het goed geschikt voor echte implementaties. De auteurs suggereren de aanpak uit te breiden naar tijdsvariërende netwerken, als volgende stap richting realistische, voortdurend veranderende communicatieomgevingen.
Bronvermelding: Ou, M., Zhang, H., Yan, Z. et al. A novel distributed gradient algorithm for composite constrained optimization over directed network. Sci Rep 16, 5185 (2026). https://doi.org/10.1038/s41598-026-36058-4
Trefwoorden: gedistribueerde optimalisatie, gerichte netwerken, multi-agent systemen, sparse regularisatie, geconstrueerde convexe problemen