Clear Sky Science · it
Stima delle filtrazioni in dighe in terra eterogenee su fondazioni permeabili mediante machine learning interpretabile
Perché conta l’acqua che filtra attraverso le dighe
In tutto il mondo molte comunità dipendono da dighe in terra per immagazzinare acqua potabile, irrigare i campi e contenere le inondazioni. Eppure queste strutture apparentemente solide sono costantemente soggette a perdite. Un piccolo rivolo ben controllato è innocuo; una filtrazione nascosta eccessiva può scavare gallerie all’interno della diga o nella fondazione e provocare un cedimento improvviso. Questo articolo esplora come il moderno machine learning possa aiutare gli ingegneri a prevedere quel flusso invisibile in modo più accurato e rapido, specialmente nel caso più realistico di dighe con interni stratificati costruite su terreni permeabili.
Come le dighe perdono acqua sotto la superficie
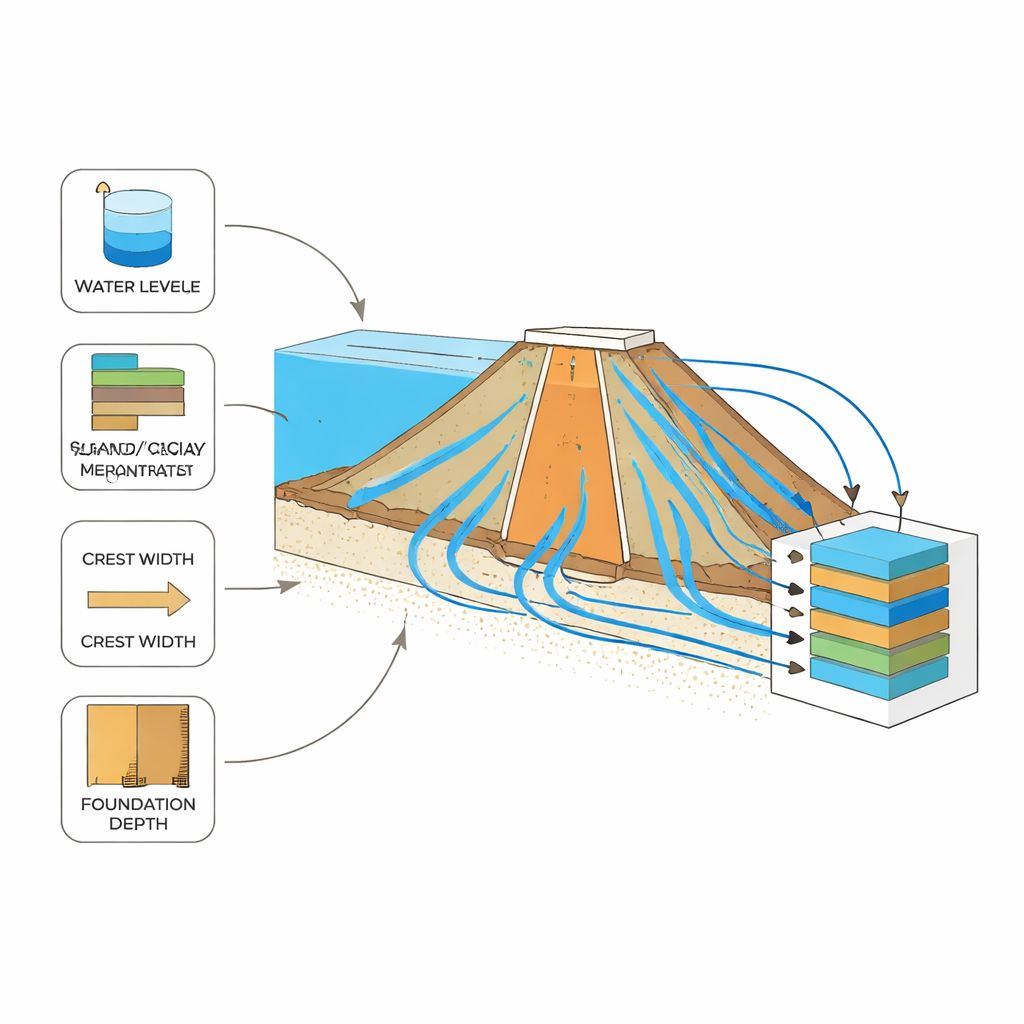
Le dighe in terra non sono cumuli di terreno omogenei. Spesso presentano un nucleo relativamente impermeabile affiancato da gusci più porosi, il tutto poggiante su una fondazione che può anch’essa lasciar passare l’acqua. Quando l’acqua del bacino preme sulla faccia a monte, una parte filtra attraverso il corpo della diga e sotto la sua base, seguendo percorsi complessi controllati dall’altezza dell’acqua, dai tipi di suolo e dalla geometria della diga. I calcoli tradizionali semplificano questo quadro a tal punto da funzionare solo per forme idealizzate. Simulazioni numeriche dettagliate basate sul metodo degli elementi finiti fanno di meglio, ma possono essere lente e richiedere competenze specialistiche, il che ne limita l’uso per verifiche rapide di progetto o revisioni di sicurezza di routine.
Insegnare ai computer a riconoscere i pattern di filtrazione
Gli autori hanno assemblato una grande libreria digitale di 4.374 scenari di filtrazione, ciascuno prodotto da un programma di simulazione affidabile che calcola il flusso d’acqua attraverso e sotto le dighe. Per ogni caso hanno variato sette input chiave che gli ingegneri possono misurare o progettare: larghezza della cresta, profondità della fondazione, livello dell’acqua nel bacino, le lunghezze delle pendici a monte e a valle, quanto facilmente l’acqua attraversa la fondazione e quanto il nucleo è meno permeabile rispetto ai gusci. Per ogni combinazione di input, la simulazione ha prodotto un output principale: quanta acqua filtra per metro di diga. Questo dataset curato è diventato il terreno di addestramento per diversi modelli di machine learning che mirano a prevedere la filtrazione direttamente a partire dai sette input.
Trovare il motore di previsione più affidabile
Il team ha testato cinque famiglie di modelli ampiamente usate su dati tabulari di ingegneria: alberi decisionali singoli, foreste casuali e tre metodi di “boosting” che combinano molti piccoli alberi in un ensemble potente. Piuttosto che indovinare i parametri del modello, hanno utilizzato l’ottimizzazione bayesiana, una strategia di ricerca sistematica che tratta ogni prova come un esperimento e si concentra sulle opzioni più promettenti evitando l’overfitting. La performance è stata valutata con una batteria di misure di errore, grafici che confrontano le previsioni con i risultati delle simulazioni e controlli incrociati usando diverse suddivisioni dei dati. Il chiaro vincitore è stato il modello di categorical gradient boosting (CGB), che ha riprodotto la filtrazione simulata con precisione quasi perfetta su dati non visti, mentre i modelli ad albero più semplici sono rimasti indietro.
Aprire la scatola nera del machine learning
Per rendere questi modelli sofisticati utili agli ingegneri di dighe, gli autori hanno dovuto spiegare cosa guida le loro previsioni. Si sono rivolti a uno strumento moderno di interpretabilità noto come SHAP, che assegna a ciascun input una quota di responsabilità per l’output in ogni scenario. Questa analisi ha rivelato che due fattori dominano il comportamento della filtrazione: quanto è profondo il livello del bacino e quanto il nucleo è più compatto rispetto ai gusci circostanti. Un’acqua più profonda spinge fortemente la filtrazione verso l’alto, mentre un nucleo molto meno permeabile la riduce nettamente. La permeabilità della fondazione e la profondità della fondazione giocano un ruolo secondario, e la larghezza della cresta ha un effetto stabilizzante modesto. I dettagli delle pendenze contano relativamente poco nei range studiati, risultato che può aiutare a concentrare l’attenzione sulle leve di progetto più influenti.
Dal modello di ricerca allo strumento di uso quotidiano
Per colmare il divario tra teoria e pratica, il modello CGB con le migliori prestazioni è stato racchiuso in una semplice applicazione desktop. Gli utenti possono inserire le sette proprietà della diga e della fondazione e ottenere immediatamente una stima della filtrazione, singola o per molti scenari contemporaneamente. Le previsioni del modello hanno concordato sia con studi numerici precedenti sia con uno studio di caso indipendente sulla diga Hub in Pakistan, restando entro circa il 10 percento dei risultati consolidati su diversi livelli d’acqua. Per i non specialisti, il messaggio principale è rassicurante: combinando simulazioni ad alta fedeltà, machine learning avanzato e spiegazioni chiare di ciò che conta di più, gli ingegneri dispongono ora di un modo rapido e trasparente per prevedere quanta acqua filtrerà attraverso dighe in terra complesse e per verificare se tali perdite rimangono entro limiti di sicurezza.
Citazione: Sayed Ahmed, M.M., Khursheed, M.Z., Alshameri, B. et al. Estimating seepage in heterogeneous earthfill dams on permeable foundations using explainable machine learning. Sci Rep 16, 12060 (2026). https://doi.org/10.1038/s41598-026-45048-5
Parole chiave: dighe in terra, filtrazioni, machine learning, sicurezza delle dighe, ingegneria geotecnica