Clear Sky Science · it
Un framework di deep learning embedded per il rilevamento di violenza in tempo reale e la generazione di allarmi
Perché telecamere più intelligenti contano per la sicurezza quotidiana
Risse e aggressioni in strada, a scuola e sui mezzi pubblici si svolgono spesso in pochi secondi, molto prima che un operatore umano possa controllare ogni schermo di sorveglianza e chiamare aiuto. Questo studio introduce un metodo che consente a piccoli computer a basso costo — dispositivi modesti come una scheda Raspberry Pi — di analizzare il video in tempo reale e segnalare automaticamente comportamenti probabili di violenza. Compattando potenti tecniche di analisi video in un sistema efficiente e on‑device, il lavoro mostra come le telecamere esistenti possano diventare sentinelle più rapide e affidabili senza dipendere da data center remoti o da un controllo umano costante.
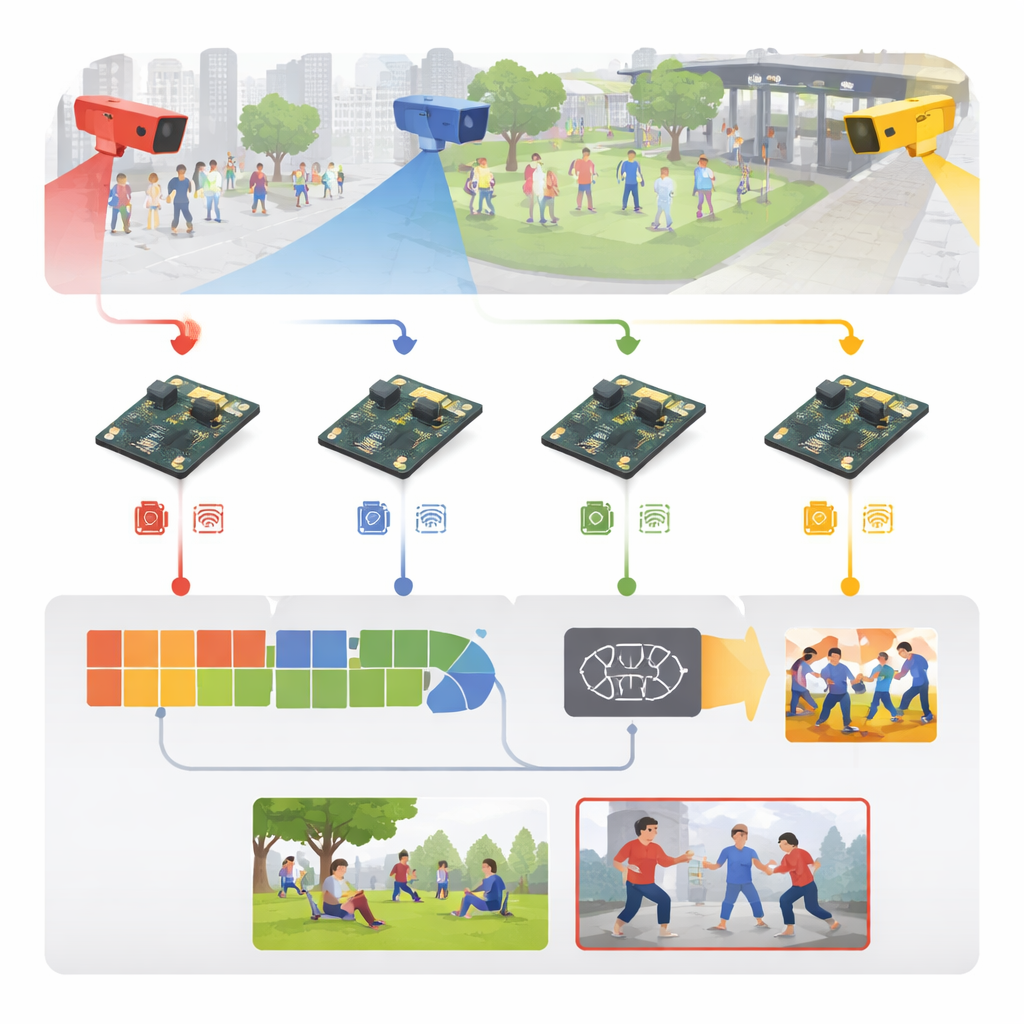
Da video grezzo a segnali di allerta precoci
Il sistema prende avvio da normali riprese di sorveglianza provenienti da luoghi come impianti sportivi, marciapiedi, percorsi del campus e corridoi interni. Invece di inviare tutto questo flusso video a un server centrale, ogni telecamera invia i suoi frame direttamente a una board embedded vicina. Lì, i frame in ingresso vengono standardizzati — ridimensionati, puliti e leggermente alterati con flip, rotazioni e variazioni di luminosità durante l’addestramento — in modo che il modello impari a gestire diverse condizioni di illuminazione, punti di osservazione e densità di folla. Gli autori hanno inoltre costruito un mix ricco di materiale di addestramento: cinque dataset pubblici noti più una nuova raccolta a sei categorie che comprende pugni, calci, attacchi con armi, violenza di gruppo, fuga e interazioni normali.
Come funziona il cervello compatto dentro la scatola
Al centro del sistema c’è un motore di apprendimento snello a due stadi. Prima, un modulo immagine leggero esamina ogni frame alla ricerca di indizi visivi rivelatori — sagome del corpo, posizioni di braccia e gambe e contorni di movimento — utilizzando operazioni convoluzionali a basso costo riprese dai modelli per telefoni cellulari. Poi un secondo modulo osserva una breve sequenza di frame per capire come questi indizi cambiano nel tempo, catturando la differenza tra, per esempio, un tocco amichevole e un pugno. Questo è realizzato con una struttura ricorrente efficiente che memorizza il movimento recente senza il pesante carico computazionale delle reti video più ingombranti. Un semplice strato finale trasforma questa comprensione spazio‑temporale in una delle sei etichette di attività, separando il movimento ordinario dalla probabile aggressione.
Adattare il deep learning a una scheda piccola e a basso consumo
Progettare un modello intelligente è solo metà della storia; farlo funzionare rapidamente su un computer delle dimensioni del palmo è la vera sfida. Gli autori trattano l’intero sistema come una pipeline ingegneristica: partono da una versione addestrata su una potente workstation grafica, poi la convertono in un formato portabile e la riducono drasticamente. La precisione numerica viene ridotta in modo che i pesi occupino un quarto della memoria originale e le parti non necessarie della rete vengono potate. Utilizzando strumenti di ottimizzazione specializzati off‑device, generano un modello tarato che può essere eseguito in modo efficiente sul Raspberry Pi tramite un runtime ottimizzato. Il risultato è un sistema che elabora circa 26 fotogrammi al secondo con un ritardo di circa 38 millisecondi per frame, consumando solo pochi watt — abbastanza veloce ed efficiente per un funzionamento continuo sul campo.

Test, fiducia e limiti del giudizio della macchina
Per verificare se il loro osservatore compatto fosse sia accurato che affidabile, i ricercatori lo hanno sottoposto a una batteria di test. Su raccolte di benchmark che vanno dalle piste di hockey alle strade cittadine, e sul loro dataset a sei classi, il sistema ha etichettato correttamente gli eventi in circa 97 casi su 100 e ha mostrato un buon equilibrio tra il rilevamento di atti violenti e la riduzione dei falsi allarmi. I confronti con modelli video più elaborati — come reti convoluzionali 3D complete e architetture basate su transformer — hanno mostrato che questo approccio più snello può eguagliare o superare la loro accuratezza utilizzando molta meno potenza di calcolo. Il team ha anche visualizzato dove il modello «guarda» all’interno di ogni frame, constatando che la sua attenzione si concentra naturalmente su arti in movimento e contatti ravvicinati tra persone, piuttosto che su dettagli di sfondo irrilevanti, il che aiuta a costruire fiducia nelle sue decisioni.
Cosa significa per spazi più sicuri e più intelligenti
Il messaggio principale dello studio non è aver inventato un tipo totalmente nuovo di rete neurale, ma aver dimostrato come impacchettare tecniche consolidate in uno strumento pratico e in tempo reale per hardware modesto. Bilanciando con cura progettazione del modello, preparazione dei dati e compressione al momento della distribuzione, gli autori forniscono un sistema embedded che può monitorare video in diretta, riconoscere violenza probabile e lanciare allarmi con basso ritardo e basso consumo energetico. Riconoscono anche sfide aperte: il sistema può ancora essere ingannato da cattiva illuminazione, scene affollate o movimenti rapidi simili a quelli sportivi, e qualsiasi tecnologia di questo tipo deve essere dispiegata con attenzione a privacy, bias e supervisione umana. Anche così, il lavoro indica un futuro in cui molte telecamere ordinarie sono abbinate a piccoli computer silenziosi che aiutano a individuare il pericolo prima e a supportare risposte più rapide e meglio informate.
Citazione: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Parole chiave: rilevamento della violenza, vision embedded, edge AI, videosorveglianza, deep learning