Clear Sky Science · it
Rilevamento integrato a livello di pixel con telerilevamento e apprendimento automatico spiegabile per l’esplorazione dell’idrogeno naturale nella parte sud-orientale del Bacino Precaspico, Kazakistan occidentale
Perché l’idrogeno nascosto conta
L’idrogeno è spesso celebrato come il combustibile pulito del futuro, ma la maggior parte di quello prodotto oggi richiede notevoli costi energetici e finanziari. Una storia più silenziosa si svolge invece sotto i nostri piedi: la Terra stessa potrebbe produrre naturalmente grandi quantità di gas idrogeno. Questo articolo esplora come gli scienziati possano individuare sottili segnali di superficie dallo spazio e usare intelligenza artificiale trasparente e spiegabile per restringere le aree in cui l’idrogeno naturale potrebbe essere nascosto nelle rocce del Kazakistan occidentale.

Una nuova caccia al tesoro energetico
A differenza di petrolio e gas, l’idrogeno naturale è leggero, filtra facilmente e lascia solo deboli impronte in superficie. Gli strumenti classici come i rilievi sismici o le misure di gravità faticano a rilevarlo direttamente. Eppure in diverse regioni del mondo l’idrogeno è stato collegato a tipi di rocce specifici, faglie profonde e strane depressioni superficiali rotonde soprannominate “cerchi delle fate”. Il Bacino Precaspico del Kazakistan occidentale ospita già giacimenti petroliferi giganti, spessi strati di sale che costituiscono ottimi tappi e tipi di rocce noti per generare idrogeno. Questa ricetta geologica suggerisce che l’area potrebbe anche accumulare sacche di idrogeno prodotto naturalmente, se riusciamo a imparare a trovarle in modo efficiente ed economico.
Vedere un gas invisibile dallo spazio
I ricercatori si sono rivolti ai satelliti europei Sentinel-2, che registrano la luce solare riflessa dalla Terra in diversi colori, incluse lunghezze d’onda sensibili alla vegetazione, all’umidità del suolo e ai minerali di superficie. Ogni immagine satellitare è composta da piccoli quadrati, o pixel, di 10 metri di lato—più o meno la dimensione di un piccolo lotto edilizio. Per ogni pixel nella regione di Atyrau nel Kazakistan occidentale, il team ha calcolato un insieme di caratteristiche numeriche: bande cromatiche grezze, indici semplici che tracciano la salute della vegetazione e l’acqua superficiale, e misure di tessitura che catturano quanto il terreno appaia ruvido o uniforme. Questi ingredienti hanno formato una descrizione a 22 variabili delle condizioni di superficie di ogni pixel, senza perforazioni né campionamenti locali.
Insegnare alle macchine a riconoscere pattern sottili
Per collegare quelle firme di superficie a possibili perdite di idrogeno, il team ha utilizzato quattro noti metodi di apprendimento automatico eccellenti nei compiti di classificazione. Hanno addestrato questi modelli su milioni di pixel etichettati da esperti come probabilmente legati all’idrogeno o no, basandosi su indagini di campo pregresse e conoscenza geologica. Invece di fornire una semplice risposta sì o no per ogni pixel, i modelli hanno prodotto una probabilità che l’idrogeno fosse presente. È stato poi applicato un taglio rigoroso in modo che soltanto i pixel con alta confidenza fossero segnalati. Per aumentare l’affidabilità, i ricercatori hanno mantenuto solo le località in cui almeno tre dei quattro modelli concordavano, quindi hanno raggruppato i pixel vicini in ammassi che potrebbero rappresentare zone realmente predisposte all’idrogeno piuttosto che isolati puntini di rumore.
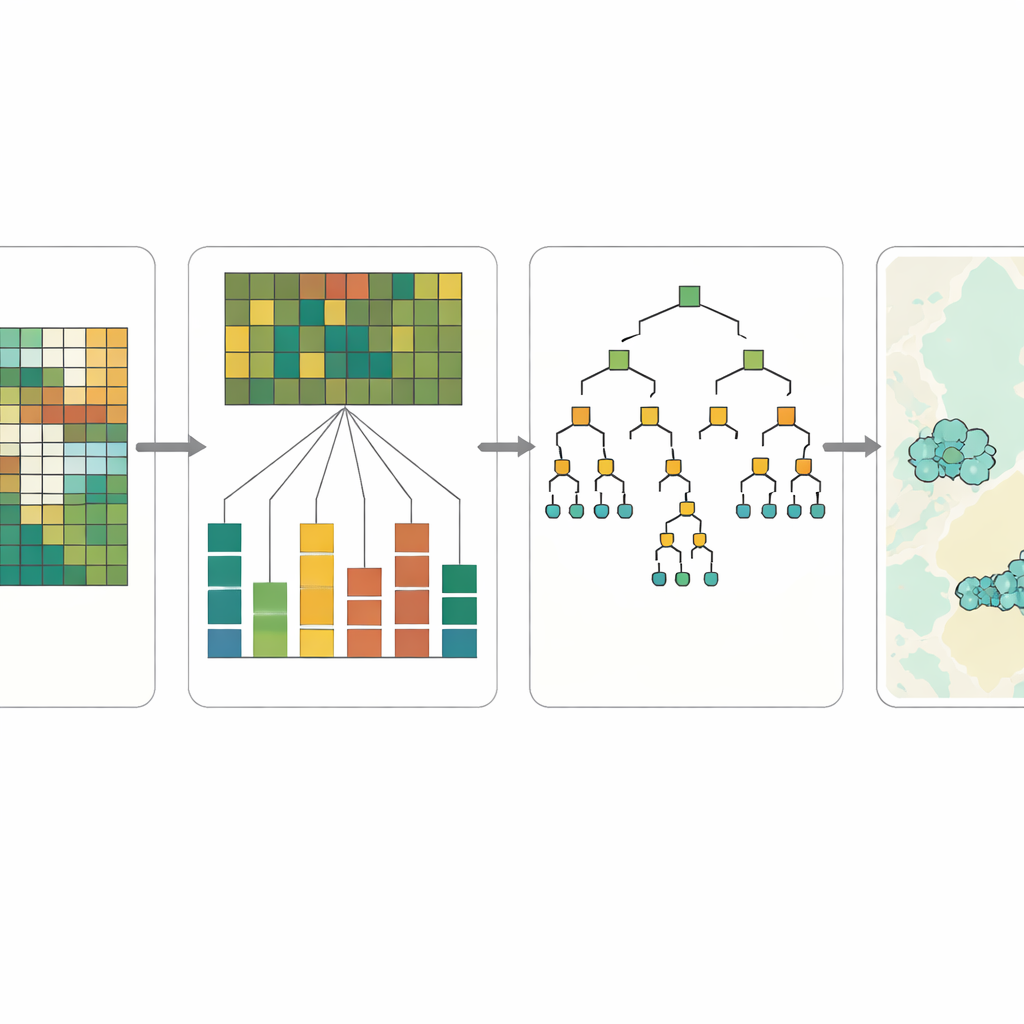
Aprire la “scatola nera” dell’intelligenza artificiale
Una delle principali preoccupazioni sull’apprendimento automatico nelle geoscienze è la fiducia: se un modello indica “questo punto sembra promettente”, gli esperti vogliono sapere perché. Lo studio ha pertanto integrato direttamente la spiegabilità nel flusso di lavoro. Usando una tecnica chiamata SHAP, gli autori hanno misurato quanto ciascuna caratteristica spettrale spingesse un pixel verso o lontano da una previsione di idrogeno. Attraverso i diversi modelli sono emersi pattern simili. Bande nel vicino infrarosso e nel medio-infrarosso—sensibili allo stress della vegetazione, a croste minerali secche e a superfici ricche di sale—sono risultate costantemente le più influenti. Quando queste mappe di importanza delle caratteristiche sono state sovrapposte a sezioni geologiche e faglie note, molte regioni ad alto punteggio coincisero con percorsi di migrazione plausibili e anomalie superficiali, conferendo credibilità fisica alle scelte della macchina.
Dallo screening generale all’intervento sul campo
Le mappe risultanti non costituiscono una prova diretta di serbatoi nascosti di idrogeno, ma forniscono uno strumento di screening potente. I modelli tendono a essere generosi nel segnalare siti potenziali, catturando la maggior parte dei pixel che appaiono simili all’idrogeno ma producendo anche molti falsi positivi. Per l’esplorazione in fase iniziale, questo compromesso è accettabile: l’obiettivo è ridurre una vasta regione di frontiera a un insieme gestibile di obiettivi per campagne di campo. Ad Atyrau, l’approccio evidenzia una manciata di ammassi coerenti, alcuni allineati con faglie profonde e “finestre” di sale, dove il gas potrebbe plausibilmente risalire dal sottosuolo. Combinando dati satellitari, apprendimento automatico a livello di pixel e spiegazioni chiare di cosa guida ogni previsione, lo studio offre una roadmap interpretabile e a basso costo per individuare l’idrogeno naturale in Kazakistan e in altri bacini poco esplorati nel mondo.
Citazione: Wayo, D.D.K., Goliatt, L., Hazlett, R. et al. Integrated pixel-wise remote sensing and explainable machine learning for natural hydrogen exploration in southeastern part of Pricaspian Basin, Western Kazakhstan. Sci Rep 16, 11085 (2026). https://doi.org/10.1038/s41598-026-41845-0
Parole chiave: idrogeno naturale, telerilevamento, apprendimento automatico, Kazakistan, esplorazione energetica